CANDLE
收藏github2021-12-10 更新2024-05-31 收录
下载链接:
https://github.com/gautam0707/CANDLE
下载链接
链接失效反馈官方服务:
资源简介:
CANDLE数据集包含12546张`.png`格式的图像,每张图像通过随机放置前景对象于背景场景中生成。这种受控的图像生成方式允许记录变异的真实因素,从而使我们能够使用无监督和监督学习研究解耦表示学习。
The CANDLE dataset comprises 12,546 images in `.png` format, each generated by randomly placing foreground objects onto background scenes. This controlled method of image generation allows for the documentation of varying real-world factors, thereby enabling the study of disentangled representation learning through both unsupervised and supervised learning approaches.
创建时间:
2021-06-03
原始信息汇总
数据集概述
数据集名称
IITH-CANDLE
数据集内容
- 图像数量:12546张
- 图像格式:
.png - 图像生成方式:随机放置前景对象于背景场景中,支持无监督和监督学习下的解耦表示学习研究。
变量因素
- 对象:Cube, Sphere, Cylinder, Cone, Torus
- 颜色:Red, Blue, Yellow, Purple, Orange
- 大小:Small, Medium, Large
- 旋转:0◦, 15◦, 30◦, 45◦, 60◦, 90◦
- 光照:Left, Middle, Right
- 场景:Indoor, Playground, Outdoor, Bridge, City Square, Hall, Grassland, Garage, Street, Beach, Station, Tunnel, Moonlit Grass, Dusk City, Skywalk, Garden
数据集结构
- 元数据格式:
json - 元数据内容示例: json { "scene": "playground", "lights": "middle", "objects": { "Torus_0": { "object_type": "torus", "color": "blue", "size": 2.5, "rotation": 15, "bounds": [[150,36],[245,66]] } } }
数据集下载
- 下载链接:Google Drive
- 大小:1.7 GB
数据集使用
- 模拟与扩展:使用Blender渲染,可通过修改
candle_simulator.py脚本添加新对象。 - 评估指标:提出两种评估指标,用于研究因果解耦。
引用信息
-
引用格式:
@article{candle, title={On Causally Disentangled Representations},
journal={Proceedings of the AAAI Conference on Artificial Intelligence}, author={Abbavaram Gowtham Reddy and Benin Godfrey L and Vineeth N Balasubramanian}, year={2022}, month={February} }
许可证
搜集汇总
数据集介绍
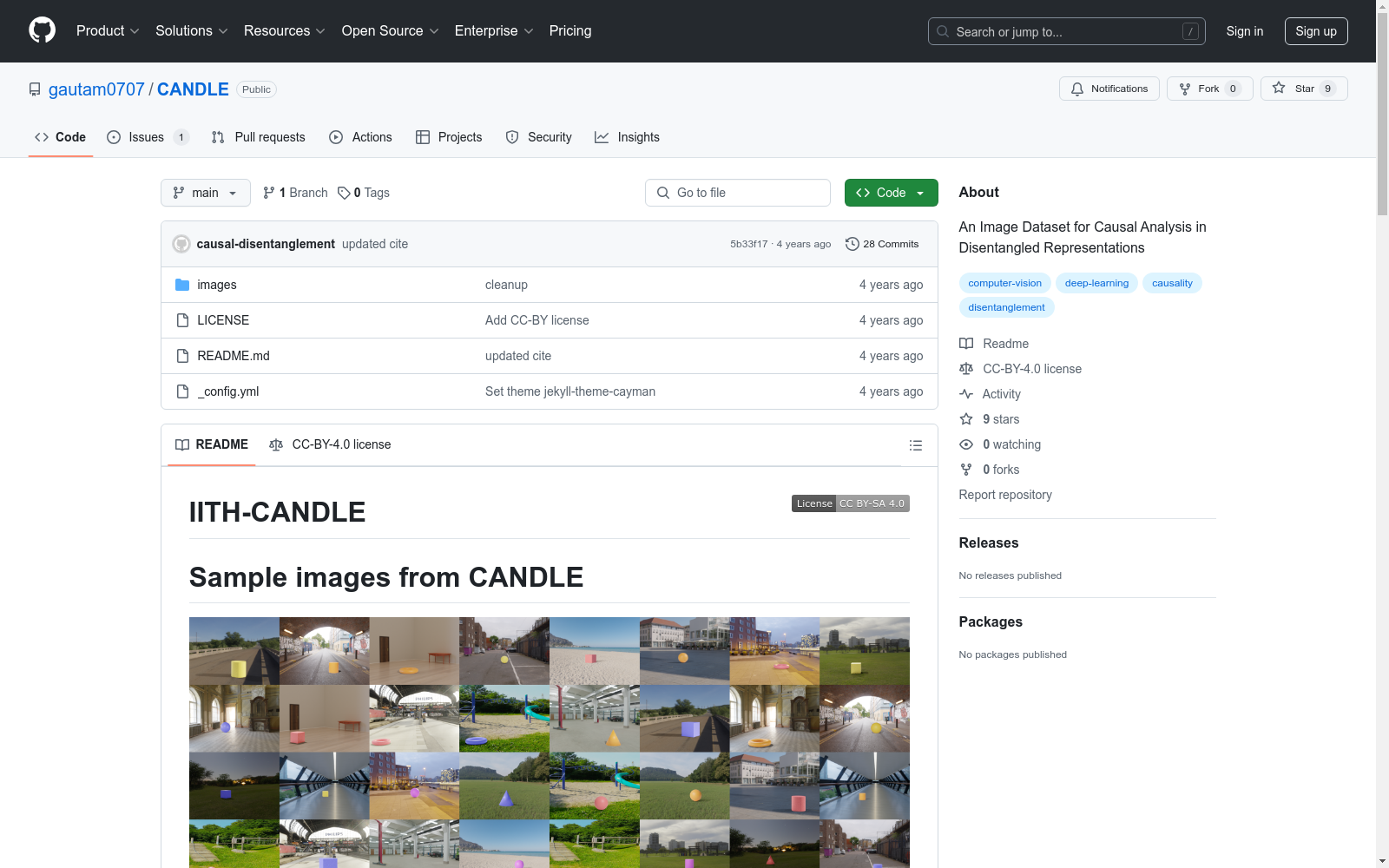
构建方式
CANDLE数据集的构建采用了基于Blender的3D渲染技术,通过将3D对象随机放置在HDRi全景背景图像中生成图像。每个图像都包含了前景对象与背景场景的精确组合,确保了生成过程中能够记录地面真实的变异因素。这种受控的生成方式使得数据集能够用于研究无监督和有监督学习中的解耦表示学习。
特点
CANDLE数据集包含了12546张PNG格式的图像,每张图像都附有详细的元数据,记录了生成过程中的各种因素,如对象类型、颜色、大小、旋转角度、光源位置和场景类型。这些因素不仅独立存在,还可能受到观察到的或未观察到的混杂因素的影响,从而为研究因果解耦提供了丰富的实验材料。
使用方法
CANDLE数据集的使用方法包括下载数据集、解析元数据以及运行Blender脚本来扩展或修改数据集。用户可以通过提供的Blender脚本自定义前景对象和背景场景,生成新的图像。此外,数据集还提供了用于评估因果解耦的指标,用户可以使用这些指标对现有的解耦表示学习模型进行因果视角的评估。
背景与挑战
背景概述
CANDLE数据集由印度海得拉巴国际信息技术研究所(IITH)的研究团队于2022年创建,旨在推动因果解耦表示学习的研究。该数据集包含12546张图像,每张图像通过在前景中随机放置物体并叠加到背景场景中生成,确保了生成过程中所有变化因素的精确记录。CANDLE的独特之处在于其基于因果生成过程的构建方式,生成因素既可以是独立的,也可以受到观察或未观察到的混杂因素的影响。这一设计使得CANDLE成为研究因果解耦表示学习的理想工具,尤其在公平性和可解释性等现实问题中展现了重要价值。
当前挑战
CANDLE数据集的核心挑战在于如何有效解耦图像中的因果生成因素。尽管数据集通过控制生成过程提供了精确的元数据,但在实际应用中,如何从复杂的场景中分离出独立的生成因素仍是一个难题。此外,数据集的构建过程中,研究者需要克服混杂因素对生成图像的潜在影响,例如自然光与外部光源的微妙交互。这些挑战不仅要求模型具备强大的解耦能力,还需要开发新的评估指标来衡量因果解耦的效果。CANDLE的提出为相关领域的研究提供了新的方向,但也对算法的鲁棒性和泛化能力提出了更高要求。
常用场景
经典使用场景
CANDLE数据集在计算机视觉和机器学习领域中被广泛用于研究解耦表示学习。通过生成包含明确生成因素(如物体类型、颜色、大小、旋转角度、光照和场景)的图像,CANDLE为研究人员提供了一个可控的环境,用于探索无监督和监督学习中的解耦表示。其独特的生成机制使得研究者能够精确控制每个生成因素的变化,从而深入分析解耦表示的有效性。
衍生相关工作
CANDLE数据集衍生了一系列经典的研究工作,特别是在解耦表示学习和因果推断领域。例如,基于CANDLE的研究提出了新的评估指标来衡量因果解耦的效果,并推动了Beta VAE等潜在变量模型的发展。此外,CANDLE的开源模拟器也为研究者提供了扩展和定制数据集的工具,进一步促进了相关领域的研究进展。
数据集最近研究
最新研究方向
在因果解缠表示学习领域,CANDLE数据集的最新研究方向聚焦于通过因果生成过程来研究解缠表示。该数据集通过控制生成图像的方式,记录地面真实的变异因素,从而支持无监督和监督学习的研究。当前的研究热点包括探索潜在变量模型(如Beta VAE)作为解缠因果过程,并提出新的评估指标来衡量因果解缠。这些指标基于图像中因果负责的生成因素,旨在捕捉解缠因果过程的理想特性。CANDLE数据集的引入不仅推动了因果解缠表示学习的发展,还为公平性和可解释性等现实世界问题提供了新的研究视角。
以上内容由遇见数据集搜集并总结生成


