ALIF_Urdu_Corpus_AUC
收藏Hugging Face2025-05-09 更新2025-05-10 收录
下载链接:
https://huggingface.co/datasets/orature/ALIF_Urdu_Corpus_AUC
下载链接
链接失效反馈官方服务:
资源简介:
ALIF乌尔都语语料库是一个大规模、多样化的高质量乌尔都语预训练数据集,由Orature AI组织创建,适用于乌尔都语生成性语言模型的预训练。
创建时间:
2025-05-08
搜集汇总
数据集介绍
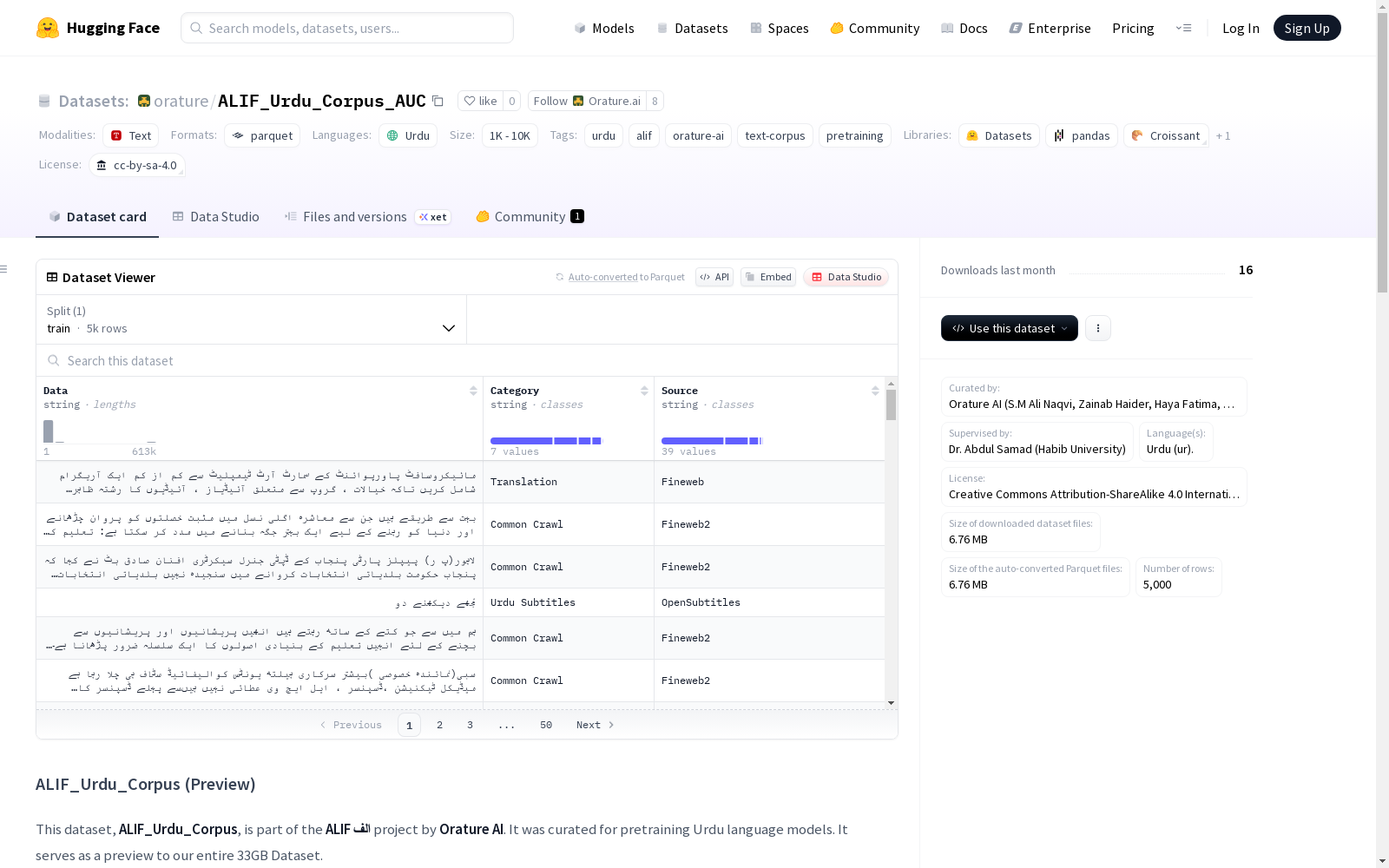
构建方式
在乌尔都语自然语言处理领域,ALIF_Urdu_Corpus_AUC数据集通过多源采集策略构建而成。该语料库整合了来自Common Crawl网络爬虫的过滤文本、基于Google Translate API翻译的教育内容、新闻网站抓取数据、现有公开语料库资源,以及通过光学字符识别技术处理的书籍文本和博客内容。在数据预处理阶段,研发团队采用语言检测工具过滤非乌尔都语内容,运用MinHash局部敏感哈希算法进行文档级去重,并通过编码规范化和文本清洗流程确保数据质量,最终形成结构化的CSV格式语料。
特点
作为乌尔都语预训练语料库,本数据集具有显著的规模优势与内容多样性。其完整版本容量达33GB,当前预览版包含5000条文本样本,涵盖新闻、教育、文学等多领域内容。每条数据均标注来源类别与具体出处,为研究者提供清晰的元数据追溯路径。语料经过严格的质量控制流程,包括噪声过滤、编码统一和去重处理,确保语言纯粹性与文本独特性,为乌尔都语大语言模型训练提供坚实的数据基础。
使用方法
该数据集主要服务于乌尔都语自然语言处理的研究与应用。使用者可通过Hugging Face平台加载数据集,直接用于生成式语言模型的预训练任务。在技术实现层面,数据条目采用End-of-Text标记进行文档边界划分,支持标准的文本生成训练流程。除基础预训练外,该语料还可延伸应用于指令微调、语言现象研究、模型偏见分析等场景,为乌尔都语NLP社区提供多维度研究支撑。
背景与挑战
背景概述
在低资源语言处理领域,乌尔都语作为南亚地区的重要语言长期面临数字化资源匮乏的困境。由Orature AI团队主导、哈比卜大学萨马德博士监督的ALIF乌尔都语语料库项目应运而生,该项目系统整合了来自公共爬虫数据、新闻网站、翻译文献等多源文本,旨在构建大规模预训练语料库以推动乌尔都语生成式语言模型的发展。该数据集采用知识共享许可协议,通过严谨的数据清洗与去重流程,为乌尔都语自然语言处理研究提供了关键基础设施,显著提升了该语言在人工智能领域的表征能力。
当前挑战
构建乌尔都语语料库需应对双重挑战:在领域问题层面,乌尔都语复杂的波斯-阿拉伯文字体系与黏着语特性对语言模型建模构成结构性障碍,同时缺乏标准化评测基准制约了模型性能评估;在技术实施层面,原始数据中存在大量非乌尔都语混杂内容与编码不一致问题,扫描文献的光学字符识别错误率居高不下,跨源数据的近似重复文本检测需要开发基于局部敏感哈希的高级去重算法,这些因素共同增加了高质量语料构建的技术复杂度。
常用场景
经典使用场景
在乌尔都语自然语言处理领域,ALIF_Urdu_Corpus作为大规模预训练语料库,其经典应用场景集中于生成式语言模型的基座训练。该数据集通过整合新闻文本、文学著作、网络博客等多元来源,构建了覆盖正式与口语化表达的语料体系,为乌尔都语语言模型的语义表征能力奠定基础。研究者常将其作为初始训练数据,通过自监督学习范式使模型掌握乌尔都语的语法结构、词汇分布及文化语境特征。
解决学术问题
该数据集有效缓解了乌尔都语自然语言处理研究中高质量语料稀缺的困境。通过系统化的数据清洗、去重与编码规范化流程,它解决了低资源语言模型中常见的噪声干扰与数据稀疏问题。其多源异构的语料结构为研究语言模型跨领域适应能力提供了实验基础,同时支持词汇语义演化、语言偏见检测等语言学分析任务,推动了南亚语言计算语言学理论体系的完善。
衍生相关工作
该语料库催生了系列乌尔都语NLP创新研究,例如Orature AI团队基于完整33GB语料开发的ALIF语言模型系列。相关研究延伸至低资源语言多模态预训练、乌尔都语-英语神经机器翻译系统优化等领域。学术界以此为基础构建了UrduBERT、UrduT5等预训练架构,并在EMNLP等国际会议形成了专门针对乌尔都语语言技术的研究脉络。
以上内容由遇见数据集搜集并总结生成


