Isnad-AI-Identifying-Islamic-Citation
收藏Hugging Face2025-08-26 更新2025-08-28 收录
下载链接:
https://huggingface.co/datasets/FatimahEmadEldin/Isnad-AI-Identifying-Islamic-Citation
下载链接
链接失效反馈官方服务:
资源简介:
这个数据集包含由大型语言模型生成的文本中用于识别《古兰经》经文(艾雅)和圣训(哈迪斯)的跨度。该模型基于AraBERTv2,并使用一种新颖的基于规则的数据生成管道来解决特定任务缺乏大量手动标注数据集的问题。数据集的整个训练和验证数据集都是使用多阶段管道生成的。
创建时间:
2025-08-22
原始信息汇总
Isnad AI: AraBERT for Ayah & Hadith Span Detection in LLM Outputs 数据集概述
数据集基本信息
- 许可证: Apache 2.0
- 语言: 阿拉伯语 (ar)
- 评估指标: F1分数
- 基础模型: aubmindlab/bert-base-arabertv02
数据集用途
该数据集用于训练模型识别大型语言模型(LLM)输出中古兰经经文(Ayahs)和圣训(Hadiths)的字符级跨度,采用BIO标注模式:
- B-Ayah (古兰经经文开始)
- I-Ayah (古兰经经文内部)
- B-Hadith (圣训开始)
- I-Hadith (圣训内部)
- O (非宗教引用)
数据生成方法
采用基于规则的数据生成管道,完全无需人工标注:
- 数据来源: 古兰经全部6,236节经文和六大圣训集的34,000多条叙述
- 文本分割: 将超过25个token的古兰经经文分割,使独特阿亚特文本从6,236增加到6,910
- 数据增强: 通过移除阿拉伯语变音符号(Tashkeel),使独特阿亚特文本数量翻倍至13,820
- 模板生成: 使用前缀、后缀和中性连接句构建训练样本
数据集统计
数据分布
| 阶段 | 语料库 | 阿亚特数量 | 圣训数量 | 独特文本总数 | 生成样本总数 |
|---|---|---|---|---|---|
| 原始文本 | 原始文本 | 6,236 | 34,662 | 40,898 | - |
| 增强后 | 增强后文本 | 13,820 | 31,317 | 45,137 | - |
| 训练集(70%) | 训练集 | 20,622 | 72,477 | 31,033 | 93,099 |
| 验证集(30%) | 验证集 | 20,313 | 20,313 | 13,542 | 40,626 |
| 总计 | - | 40,935 | 92,790 | 44,575 | 133,725 |
模板组件示例
| 组件类型 | 类别 | 训练集示例 | 验证集示例 |
|---|---|---|---|
| 前缀 | 阿亚特 | قال الله تعالى:, وقال الله عز وجل: | وفي القرآن الكريم نجد:, ومن آيات الله: |
| 后缀 | 阿亚特 | صدق الله العظيم, آية كريمة | هذا من كلام الله, آية عظيمة |
| 前缀 | 圣训 | قال رسول الله صلى الله عليه وسلم:, وقال النبي صلى الله عليه وسلم: | وفي السنة النبوية:, ومن هدي النبي صلى الله عليه وسلم: |
| 后缀 | 圣训 | رواه البخاري, رواه مسلم | من السنة النبوية, حديث نبوي شريف |
| 中性句子 | 两者 | وبناء على ذلك، يمكننا أن نستنتج., وهذا يوضح عظمة التشريع. | ولنتأمل معاً, وفي هذا السياق |
模型性能
测试集结果
- 最终F1分数: 66.97%
- 生成数据消融实验: 50.50%
- 数据库查找消融实验: 34.80%
开发集性能
- 最终宏F1分数: 65.08%
- 各类别性能(字符级):
- 非宗教文本: 精确率0.8423, 召回率0.9688, F1分数0.9011
- 阿亚特: 精确率0.8326, 召回率0.5574, F1分数0.6678
- 圣训: 精确率0.4750, 召回率0.3333, F1分数0.3917
局限性
- 圣训识别性能: 对圣训文本的识别效果较低
- 模板依赖性: 可能无法识别训练数据中未出现的新颖上下文中的引用
- 范围限制: 仅识别引用形式,不验证引用的真实性
搜集汇总
数据集介绍
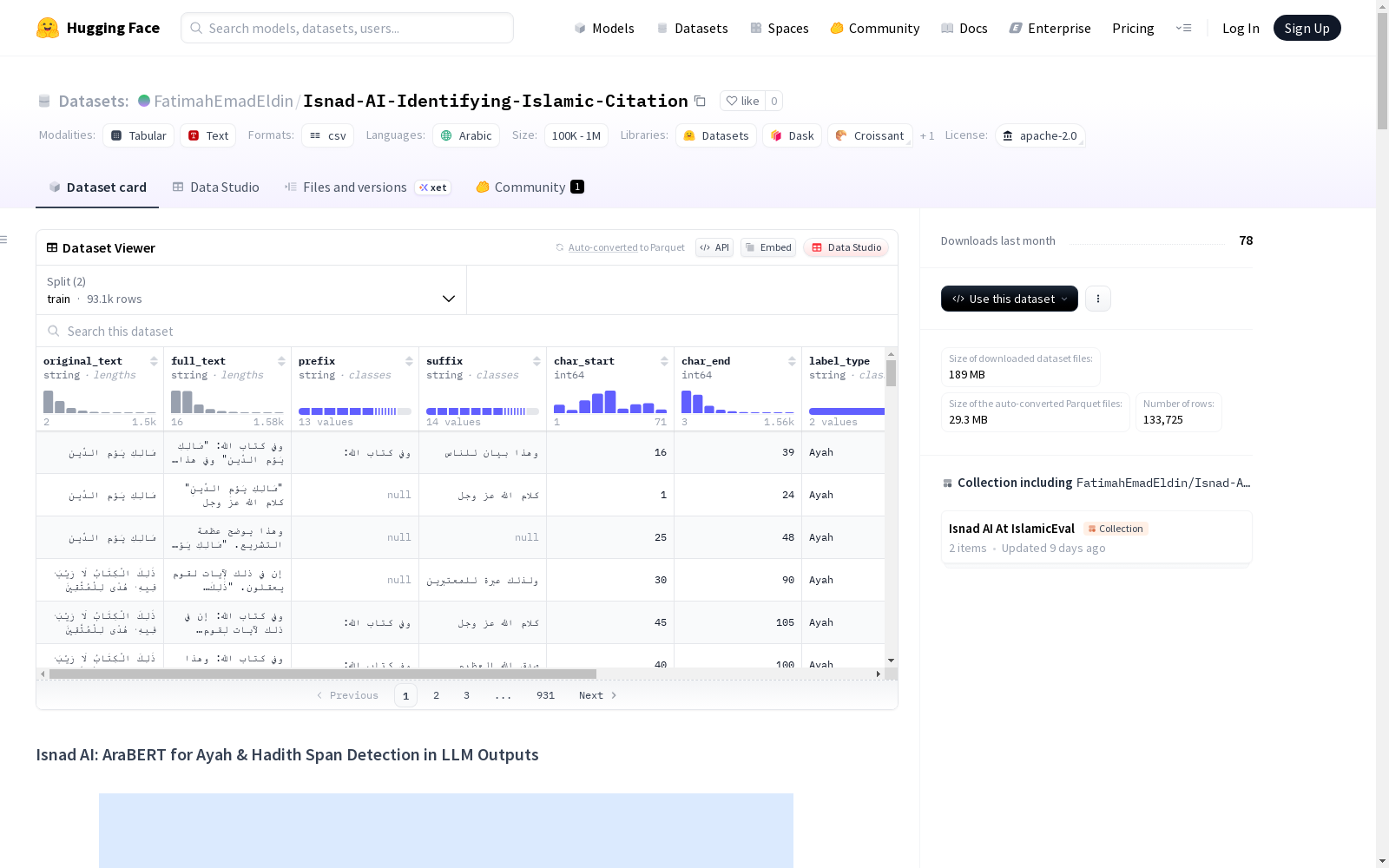
构建方式
在伊斯兰文本计算分析领域,数据稀缺性构成了关键挑战。Isnad-AI数据集通过创新的规则驱动流程构建,首先从权威宗教典籍中提取6236段古兰经节文和34662段圣训原文,并实施文本分割与音符号去除等数据增强策略,使有效文本规模扩展至45137条。采用模板化生成机制,将宗教文本嵌入多样化上下文模板,自动生成133725条标注样本,彻底规避了传统人工标注的局限性。
特点
该数据集的核心特征体现在其专业化标注体系与结构多样性上。所有文本均采用BIO序列标注框架,精确标识古兰经文(B/I-Ayah)和圣训文本(B/I-Hadith)的字符级边界。数据集涵盖不同长度的宗教引文变体,并包含去音符号文本变体,增强了模型对阿拉伯语书写变体的适应性。通过精心设计的上下文模板库,模拟了大语言模型输出中宗教引用的典型呈现方式,为模型提供了丰富的语境化学习样本。
使用方法
该数据集专用于训练和评估宗教文本引用检测模型。研究者可通过HuggingFace Transformers库加载预训练模型,使用token-classification管道进行预测。输入阿拉伯语文本后,模型将输出字符级的实体边界预测及置信度评分。建议采用aggregation_strategy="simple"参数优化实体聚合效果,适用于检测大语言模型生成内容中的宗教引文,为伊斯兰计算语言学提供可靠的技术基础。
背景与挑战
背景概述
伊斯兰文本计算分析领域近年来受到自然语言处理技术的深刻影响,Isnad-AI数据集由开罗大学的Fatimah Emad Eldin博士团队为IslamicEval 2025共享任务而构建,专注于识别大型语言模型输出中的古兰经经文和圣训引文片段。该数据集采用创新的规则化数据生成管道,通过程序化方式从权威宗教文本中构建大规模训练语料,完全避免了人工标注需求,显著提升了阿拉伯语宗教文本自动识别的研究水平,为伊斯兰数字人文研究提供了重要基础设施。
当前挑战
该数据集核心挑战在于解决阿拉伯语宗教文本自动标注问题,特别是应对古兰经经文与圣训在语言结构和表达多样性上的显著差异。构建过程中面临标注标准统一、数据稀缺性以及方言变体处理等难题,研究团队通过设计多阶段数据生成管道,采用文本分割、音符号去除等增强技术,有效提升了模型对不同书写变体的识别鲁棒性,但圣训类别的识别性能仍显著低于经文类别,反映出宗教文本语义复杂性带来的持续挑战。
常用场景
经典使用场景
在伊斯兰文本计算分析领域,该数据集主要应用于大语言模型输出中古兰经经文和圣训引文的自动识别与标注。通过基于AraBERTv2架构的序列标注模型,系统能够精准定位阿拉伯语文本中宗教引文的字符级边界,为后续的引文验证和语义分析奠定基础。这种技术路径特别适用于处理包含混合宗教内容的生成文本,为数字化伊斯兰文献研究提供了可靠的自动化工具。
解决学术问题
该数据集有效解决了伊斯兰计算语言学中宗教引文自动识别的核心难题。通过创新的规则化数据生成管道,突破了传统人工标注的数据稀缺瓶颈,为研究大语言模型中宗教内容引用模式提供了标准化评估基准。其提出的BIO标注框架和特征增强方法,显著提升了模型对阿拉伯语宗教文本的语义理解能力,推动了跨宗教自然语言处理技术的发展。
衍生相关工作
该数据集催生了多项伊斯兰计算语言学的重要研究,包括基于模板增强的宗教文本生成方法、跨文档宗教引文关联分析技术等。其规则化数据构建范式被扩展应用于其他宗教文本处理任务,如圣经引文检测和佛经语义标注。相关工作还推动了多模态宗教内容理解系统的开发,为数字人文研究提供了新的技术路径和方法论参考。
以上内容由遇见数据集搜集并总结生成


