XuanwuAI/SecEval
收藏Hugging Face2023-12-21 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/XuanwuAI/SecEval
下载链接
链接失效反馈官方服务:
资源简介:
# SecEval: A Comprehensive Benchmark for Evaluating Cybersecurity Knowledge of Foundation Models
The advent of large language models has ignited a transformative era for the cybersecurity industry. Pioneering applications are being developed, deployed, and utilized in areas such as cybersecurity knowledge QA, vulnerability hunting, and alert investigation. Various researches have indicated that LLMs primarily acquire their knowledge during the pretraining phase, with fine-tuning serving essentially to align the model with user intentions, providing the ability to follow instructions. This suggests that the knowledge and skills embedded in the foundational model significantly influence the model's potential on specific downstream tas ks
Yet, a focused evaluation of cybersecurity knowledge is missing in existing datasets. We address this by introducing "SecEval". SecEval is the first benchmark specifically created for evaluating cybersecurity knowledge in Foundation Models. It offers over 2000 multiple-choice questions across 9 domains: Software Security, Application Security, System Security, Web Security, Cryptography, Memory Safety, Network Security, and PenTest.
SecEval generates questions by prompting OpenAI GPT4 with authoritative sources such as open-licensed textbooks, official documentation, and industry guidelines and standards. The generation process is meticulously crafted to ensure the dataset meets rigorous quality, diversity, and impartiality criteria. You can explore our dataset the [explore page](https://xuanwuai.github.io/SecEval/explore.html).
Using SecEval, we conduct an evaluation of 10 state-of-the-art foundational models, providing new insights into their performance in the field of cybersecurity. The results indicate that there is still a long way to go before LLMs can be the master of cybersecurity. We hope that SecEval can serve as a catalyst for future research in this area.
## Table of Contents
- [Leaderboard](#leaderboard)
- [Dataset](#dataset)
- [Generation Process](#generation-process)
- [Limitations](#limitations)
- [Future Work](#future-work)
- [Licenses](#licenses)
- [Citation](#citation)
- [Credits](#credits)
## Leaderboard
| # | Model | Creator | Access | Submission Date | System Security | Application Security | PenTest | Memory Safety | Network Security | Web Security | Vulnerability | Software Security | Cryptography | Overall |
|-----|-------------------|-----------|-----------|-----------------|-----------------|----------------------|---------|---------------|------------------|--------------|---------------|-------------------|--------------|---------|
| 1 | GPT-4-turbo | OpenAI | API, Web | 2023-12-20 | 73.61 | 75.25 | 80.00 | 70.83 | 75.65 | 82.15 | 76.05 | 73.28 | 64.29 | 79.07 |
| 2 | gpt-3.5-turbo | OpenAI | API, Web | 2023-12-20 | 59.15 | 57.18 | 72.00 | 43.75 | 60.87 | 63.00 | 60.18 | 58.19 | 35.71 | 62.09 |
| 3 | Yi-6B | 01-AI | Weight | 2023-12-20 | 50.61 | 48.89 | 69.26 | 35.42 | 56.52 | 54.98 | 49.40 | 45.69 | 35.71 | 53.57 |
| 4 | Orca-2-7b | Microsoft | Weight | 2023-12-20 | 46.76 | 47.03 | 60.84 | 31.25 | 49.13 | 55.63 | 50.00 | 52.16 | 14.29 | 51.60 |
| 5 | Mistral-7B-v0.1 | Mistralai | Weight | 2023-12-20 | 40.19 | 38.37 | 53.47 | 33.33 | 36.52 | 46.57 | 42.22 | 43.10 | 28.57 | 43.65 |
| 6 | chatglm3-6b-base | THUDM | Weight | 2023-12-20 | 39.72 | 37.25 | 57.47 | 31.25 | 43.04 | 41.14 | 37.43 | 39.66 | 28.57 | 41.58 |
| 7 | Aquila2-7B | BAAI | Weight | 2023-12-20 | 34.84 | 36.01 | 47.16 | 22.92 | 32.17 | 42.04 | 38.02 | 36.21 | 7.14 | 38.29 |
| 8 | Qwen-7B | Alibaba | Weight | 2023-12-20 | 28.92 | 28.84 | 41.47 | 18.75 | 29.57 | 33.25 | 31.74 | 30.17 | 14.29 | 31.37 |
| 9 | internlm-7b | Sensetime | Weight | 2023-12-20 | 25.92 | 25.87 | 36.21 | 25.00 | 27.83 | 32.86 | 29.34 | 34.05 | 7.14 | 30.29 |
| 10 | Llama-2-7b-hf | MetaAI | Weight | 2023-12-20 | 20.94 | 18.69 | 26.11 | 16.67 | 14.35 | 22.77 | 21.56 | 20.26 | 21.43 | 22.15 |
## Dataset
### Format
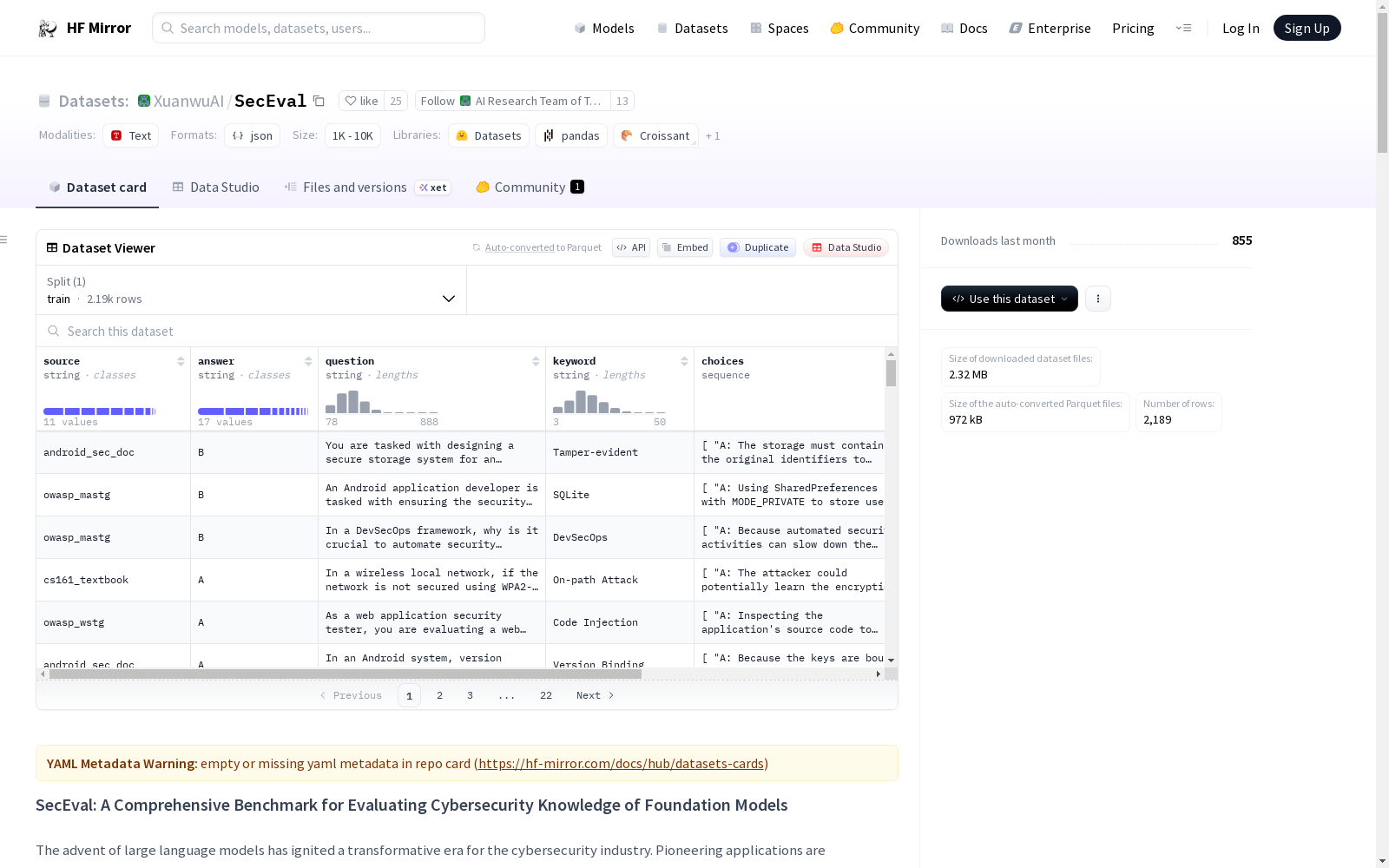
The dataset is in json format. Each question has the following fields:
* id: str # unique id for each question
* source: str # the source where the question is generated from
* question: str # the question description
* choices: List[str] # the choices for the question
* answer: str # the answer for the question
* topics: List[QuestionTopic] # the topics for the question, each question can have multiple topics.
* keyword: str # the keyword for the question
### Question Distribution
| Topic | No. of Questions |
|---------------------|-----------------|
| SystemSecurity | 1065 |
| ApplicationSecurity | 808 |
| PenTest | 475 |
| MemorySafety | 48 |
| NetworkSecurity | 230 |
| WebSecurity | 773 |
| Vulnerability | 334 |
| SoftwareSecurity | 232 |
| Cryptography | 14 |
| Overall | 2126 |
### Download
You can download the json file of the dataset by running.
```
wget https://huggingface.co/datasets/XuanwuAI/SecEval/blob/main/questions.json
```
Or you can load the dataset from [Huggingface](https://huggingface.co/datasets/XuanwuAI/SecEval).
### Evaluate Your Model on SecEval
You can use our [evaluation script](https://github.com/XuanwuAI/SecEval/tree/main/eval) to evaluate your model on SecEval dataset.
## Generation Process
### Data Collection
- **Textbook**: We selected open-licensed textbooks from the Computer Security courses CS161 at UC Berkeley and 6.858 at MIT. These resources provide extensive information on network security, memory safety, web security, and cryptography.
- **Official Documentation**: We utilized official documentation, such as Apple Platform Security, Android Security, and Windows Security, to integrate system security and application security knowledge specific to these platforms.
- **Industrial Guidelines**: To encompass web security, we referred to the Mozilla Web Security Guidelines. In addition, we used the OWASP Web Security Testing Guide (WSTG) and OWASP Mobile Application Security Testing Guide (MASTG) for insights into web and application security testing.
- **Industrial Standards**: The Common Weakness Enumeration (CWE) was employed to address knowledge of vulnerabilities. For penetration testing, we incorporated the MITRE ATT&CK and MITRE D3fend frameworks.
### Questions Generation
To facilitate the evaluation process, we designed the dataset in a multiple-choice question format. Our approach to question generation involved several steps:
1. **Text Parsing**: We began by parsing the texts according to their hierarchical structure, such as chapters and sections for textbooks, or tactics and techniques for frameworks like ATT&CK.
2. **Content Sampling**: For texts with extensive content, such as CWE or Windows Security Documentation, we employed a sampling strategy to maintain manageability. For example, we selected the top 25 most common weakness types and 175 random types from CWE.
3. **Question Generation**: Utilizing GPT-4, we generated multiple-choice questions based on the parsed text, with the level of detail adjusted according to the content's nature. For instance, questions stemming from the CS161 textbook were based on individual sections, while those from ATT&CK were based on techniques.
4. **Question Refinement**: We then prompted GPT-4 to identify and filter out questions with issues such as too simplistic or not self-contained. Where possible, questions were revised; otherwise, they were discarded.
5. **Answer Calibration**: We refine the selection of answer options by presenting GPT-4 with both the question and the source text from which the question is derived. Should the response generated by GPT-4 diverge from the previously established answer, this discrepancy suggests that obtaining a consistent answer for the question is inherently challenging. In such cases, we opt to eliminate these problematic questions.
6. **Classification**: Finally, we organized the questions into 9 topics, and attached a relevant fine-grained keyword to each question.
## Limitations
The dataset, while comprehensive, exhibits certain constraints:
1. **Distribution Imbalance**: The dataset presents an uneven distribution of questions across different domains, resulting in a higher concentration of questions in certain areas while others are less represented.
2. **Incomplete Scope**: Some topics on Cybersecurity are absent from the dataset, such as content security, reverse engineering, and malware analysis. As such, it does not encapsulate the full breadth of knowledge within the field.
## Future Work
1. **Improvement on Distribution**: We aim to broaden the dataset's comprehensiveness by incorporating additional questions, thereby enriching the coverage of existing cybersecurity topics.
2. **Improvement on Topic Coverage**: Efforts will be made to include a wider array of cybersecurity topics within the dataset, which will help achieve a more equitable distribution of questions across various fields.
## Licenses
The dataset is released under the [CC BY-NC-SA 4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/) license. The code is released under the [MIT](https://opensource.org/licenses/MIT) license.
## Citation
```bibtex
@misc{li2023seceval,
title={SecEval: A Comprehensive Benchmark for Evaluating Cybersecurity Knowledge of Foundation Models},
author={Li, Guancheng and Li, Yifeng and Wang Guannan and Yang, Haoyu and Yu, Yang},
publisher = {GitHub},
howpublished= "https://github.com/XuanwuAI/SecEval",
year={2023}
}
```
## Credits
This work is supported by [Tencent Security Xuanwu Lab](https://xlab.tencent.com/en/) and Tencent Spark Talent Program.
# SecEval:面向基础模型(Foundation Models)网络安全知识评估的综合基准测试集
大语言模型(Large Language Model,以下简称LLM)的出现,开启了网络安全行业的变革性新时代。诸多开创性应用已在网络安全知识问答、漏洞挖掘、告警溯源等领域得到开发、部署与应用。多项研究表明,LLM的知识主要来源于预训练阶段,而微调本质上是为了让模型适配用户意图,使其具备遵循指令的能力。这意味着基础模型中蕴含的知识与技能,将显著影响模型在特定下游任务中的表现潜力。
然而,现有数据集仍缺乏针对网络安全知识的针对性评估方案。为此,我们推出了SecEval基准测试集——这是首个专为评估基础模型的网络安全知识而打造的评测基准。该数据集覆盖9大领域,包含2000余道多项选择题,分别为:软件安全(Software Security)、应用安全(Application Security)、系统安全(System Security)、Web安全(Web Security)、密码学(Cryptography)、内存安全(Memory Safety)、网络安全(Network Security)以及渗透测试(PenTest)。
SecEval通过结合权威数据源调用OpenAI GPT-4生成题目,所用权威数据源包括开放许可教材、官方文档以及行业指南与标准。题目生成流程经过精心设计,确保数据集满足严苛的质量、多样性与公正性要求。您可通过[探索页面](https://xuanwuai.github.io/SecEval/explore.html)查看本数据集。
我们利用SecEval对10款当前顶尖的基础模型开展了评估,为理解其在网络安全领域的表现提供了全新视角。评估结果显示,LLM要完全掌握网络安全知识仍有较长的路要走。我们希望SecEval能够推动该领域的后续研究工作。
## 目录
- [排行榜](#leaderboard)
- [数据集](#dataset)
- [生成流程](#generation-process)
- [局限性](#limitations)
- [未来工作](#future-work)
- [许可协议](#licenses)
- [引用](#citation)
- [致谢](#credits)
## 排行榜
| 序号 | 模型 | 开发方 | 获取方式 | 提交日期 | 系统安全(System Security) | 应用安全(Application Security) | 渗透测试(PenTest) | 内存安全(Memory Safety) | 网络安全(Network Security) | Web安全(Web Security) | 漏洞(Vulnerability) | 软件安全(Software Security) | 密码学(Cryptography) | 综合得分 |
|-----|-------------------|-----------|-----------|-----------------|-----------------|----------------------|---------|---------------|------------------|--------------|---------------|-------------------|--------------|---------|
| 1 | GPT-4-turbo | OpenAI | API、网页端 | 2023-12-20 | 73.61 | 75.25 | 80.00 | 70.83 | 75.65 | 82.15 | 76.05 | 73.28 | 64.29 | 79.07 |
| 2 | gpt-3.5-turbo | OpenAI | API、网页端 | 2023-12-20 | 59.15 | 57.18 | 72.00 | 43.75 | 60.87 | 63.00 | 60.18 | 58.19 | 35.71 | 62.09 |
| 3 | Yi-6B | 01-AI | 权重文件 | 2023-12-20 | 50.61 | 48.89 | 69.26 | 35.42 | 56.52 | 54.98 | 49.40 | 45.69 | 35.71 | 53.57 |
| 4 | Orca-2-7b | Microsoft | 权重文件 | 2023-12-20 | 46.76 | 47.03 | 60.84 | 31.25 | 49.13 | 55.63 | 50.00 | 52.16 | 14.29 | 51.60 |
| 5 | Mistral-7B-v0.1 | Mistralai | 权重文件 | 2023-12-20 | 40.19 | 38.37 | 53.47 | 33.33 | 36.52 | 46.57 | 42.22 | 43.10 | 28.57 | 43.65 |
| 6 | chatglm3-6b-base | THUDM | 权重文件 | 2023-12-20 | 39.72 | 37.25 | 57.47 | 31.25 | 43.04 | 41.14 | 37.43 | 39.66 | 28.57 | 41.58 |
| 7 | Aquila2-7B | BAAI | 权重文件 | 2023-12-20 | 34.84 | 36.01 | 47.16 | 22.92 | 32.17 | 42.04 | 38.02 | 36.21 | 7.14 | 38.29 |
| 8 | Qwen-7B | Alibaba | 权重文件 | 2023-12-20 | 28.92 | 28.84 | 41.47 | 18.75 | 29.57 | 33.25 | 31.74 | 30.17 | 14.29 | 31.37 |
| 9 | internlm-7b | Sensetime | 权重文件 | 2023-12-20 | 25.92 | 25.87 | 36.21 | 25.00 | 27.83 | 32.86 | 29.34 | 34.05 | 7.14 | 30.29 |
| 10 | Llama-2-7b-hf | MetaAI | 权重文件 | 2023-12-20 | 20.94 | 18.69 | 26.11 | 16.67 | 14.35 | 22.77 | 21.56 | 20.26 | 21.43 | 22.15 |
## 数据集
### 数据格式
本数据集采用JSON格式,每道题目包含以下字段:
* id:字符串类型 # 每道题目的唯一标识符
* source:字符串类型 # 题目的生成来源
* question:字符串类型 # 题目描述
* choices:字符串列表 # 题目选项
* answer:字符串类型 # 题目正确答案
* topics:QuestionTopic列表 # 题目所属主题,每道题可对应多个主题
* keyword:字符串类型 # 题目关键词
### 题目分布
| 主题 | 题目数量 |
|---------------------|-----------------|
| 系统安全(SystemSecurity) | 1065 |
| 应用安全(ApplicationSecurity) | 808 |
| 渗透测试(PenTest) | 475 |
| 内存安全(MemorySafety) | 48 |
| 网络安全(NetworkSecurity) | 230 |
| Web安全(WebSecurity) | 773 |
| 漏洞(Vulnerability) | 334 |
| 软件安全(SoftwareSecurity) | 232 |
| 密码学(Cryptography) | 14 |
| 总计(Overall) | 2126 |
### 下载
您可通过以下命令下载数据集的JSON文件:
wget https://huggingface.co/datasets/XuanwuAI/SecEval/blob/main/questions.json
也可从[Huggingface平台](https://huggingface.co/datasets/XuanwuAI/SecEval)加载本数据集。
### 在SecEval上评估您的模型
您可使用我们提供的[评估脚本](https://github.com/XuanwuAI/SecEval/tree/main/eval)在SecEval数据集上评估您的模型。
## 生成流程
### 数据采集
- **教材**:我们选取了加州大学伯克利分校CS161课程以及麻省理工学院6.858课程的开放许可教材,这些资源涵盖了网络安全、内存安全、Web安全与密码学等领域的丰富内容。
- **官方文档**:我们使用了苹果平台安全、安卓安全以及Windows安全等官方文档,以纳入对应平台专属的系统安全与应用安全知识。
- **行业指南**:针对Web安全领域,我们参考了Mozilla Web安全指南;此外,我们还使用了OWASP Web安全测试指南(WSTG)以及OWASP移动应用安全测试指南(MASTG),以获取Web与应用安全测试相关的参考内容。
- **行业标准**:我们采用通用弱点枚举(Common Weakness Enumeration,CWE)体系来覆盖漏洞相关知识;针对渗透测试领域,我们纳入了MITRE ATT&CK与MITRE D3fend框架。
### 题目生成
为便于评估流程开展,我们将数据集设计为多项选择题形式,题目生成流程包含以下步骤:
1. **文本解析**:首先根据文本的层级结构进行解析,例如教材的章节结构,或是ATT&CK等框架的战术与技术结构。
2. **内容抽样**:针对内容体量较大的文本(如CWE或Windows安全文档),我们采用抽样策略以控制处理规模。例如,我们从CWE中选取了最常见的25类弱点以及175类随机弱点。
3. **题目生成**:我们基于解析后的文本,通过调用GPT-4生成多项选择题,并根据内容属性调整题目细节程度。例如,源自CS161教材的题目以单个章节为基础生成,而源自ATT&CK的题目则以单个技术为基础生成。
4. **题目优化**:随后我们调用GPT-4识别并过滤掉存在缺陷的题目,例如过于简单或缺乏独立性的题目。若可修改则对题目进行优化,否则直接弃用。
5. **答案校准**:我们将题目及其来源文本一同提交给GPT-4,以优化选项选择。若GPT-4生成的答案与预先设定的正确答案不一致,则说明该题难以获得统一的标准答案,此类题目将被弃用。
6. **分类标注**:最后,我们将题目划分为9个主题,并为每道题目添加相关的细粒度关键词。
## 局限性
本数据集虽具备较强的全面性,但仍存在一定局限:
1. **分布不均衡**:数据集在不同领域的题目分布不均,部分领域题目集中度较高,而其他领域的覆盖度则相对不足。
2. **范围不完整**:数据集未覆盖部分网络安全主题,例如内容安全、逆向工程以及恶意代码分析等,因此未能涵盖该领域的全部知识范畴。
## 未来工作
1. **优化分布均衡性**:我们计划通过新增题目拓展数据集的全面性,以丰富现有网络安全主题的覆盖度。
2. **拓展主题覆盖范围**:我们将致力于在数据集中纳入更多网络安全主题,从而实现各领域题目分布的更均衡状态。
## 许可协议
本数据集采用[CC BY-NC-SA 4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/)许可协议发布,相关代码采用[MIT](https://opensource.org/licenses/MIT)许可协议发布。
## 引用
bibtex
@misc{li2023seceval,
title={SecEval: A Comprehensive Benchmark for Evaluating Cybersecurity Knowledge of Foundation Models},
author={Li, Guancheng and Li, Yifeng and Wang Guannan and Yang, Haoyu and Yu, Yang},
publisher = {GitHub},
howpublished= "https://github.com/XuanwuAI/SecEval",
year={2023}
}
## 致谢
本项目得到[腾讯安全玄武实验室](https://xlab.tencent.com/zh-CN/)以及腾讯星火计划的支持。
提供机构:
XuanwuAI
原始信息汇总
SecEval: A Comprehensive Benchmark for Evaluating Cybersecurity Knowledge of Foundation Models
数据集概述
SecEval是一个专门用于评估基础模型网络安全知识的基准测试,包含超过2000道多选题,涵盖9个领域:软件安全、应用安全、系统安全、Web安全、密码学、内存安全、网络安全和渗透测试。
数据集详情
格式
数据集采用JSON格式,每个问题包含以下字段:
id: 问题的唯一IDsource: 问题来源question: 问题描述choices: 问题的选项列表answer: 问题的答案topics: 问题所属的主题列表keyword: 问题的关键词
问题分布
| 主题 | 问题数量 |
|---|---|
| SystemSecurity | 1065 |
| ApplicationSecurity | 808 |
| PenTest | 475 |
| MemorySafety | 48 |
| NetworkSecurity | 230 |
| WebSecurity | 773 |
| Vulnerability | 334 |
| SoftwareSecurity | 232 |
| Cryptography | 14 |
| Overall | 2126 |
下载
数据集可通过以下命令下载: bash wget https://huggingface.co/datasets/XuanwuAI/SecEval/blob/main/questions.json
或从Huggingface加载。
模型评估
可以使用评估脚本在SecEval数据集上评估您的模型。
生成过程
数据收集
- 教科书:从UC Berkeley的CS161和MIT的6.858课程中选择开放许可的教科书。
- 官方文档:使用Apple、Android和Windows的官方安全文档。
- 行业指南:参考Mozilla的Web安全指南、OWASP的Web安全测试指南和移动应用安全测试指南。
- 行业标准:使用CWE、MITRE ATT&CK和MITRE D3fend框架。
问题生成
- 文本解析:根据文本的层次结构进行解析。
- 内容采样:对内容较多的文本进行采样。
- 问题生成:使用GPT-4生成多选题。
- 问题细化:筛选和修订问题。
- 答案校准:确保答案的一致性。
- 分类:将问题分类并附加关键词。
限制
- 分布不均:不同领域的题目数量不均衡。
- 范围不全:某些网络安全主题未包含在内。
未来工作
- 改进分布:增加题目以丰富覆盖范围。
- 改进主题覆盖:扩展更多网络安全主题。
许可证
数据集采用CC BY-NC-SA 4.0许可证,代码采用MIT许可证。
引用
bibtex @misc{li2023seceval, title={SecEval: A Comprehensive Benchmark for Evaluating Cybersecurity Knowledge of Foundation Models}, author={Li, Guancheng and Li, Yifeng and Wang Guannan and Yang, Haoyu and Yu, Yang}, publisher = {GitHub}, howpublished= "https://github.com/XuanwuAI/SecEval", year={2023} }
搜集汇总
数据集介绍
构建方式
在网络安全领域,随着大语言模型的兴起,评估其专业知识成为迫切需求。SecEval数据集的构建过程体现了严谨的学术方法,其核心在于利用权威知识源生成高质量多选题。研究团队精心选取了开放许可的教材、官方文档及行业指南作为基础材料,通过解析文本结构并采用分层抽样策略确保内容的代表性。随后,借助GPT-4模型生成初步问题,并经过多轮精细化筛选与校准,包括问题修正、答案一致性验证及主题分类,最终形成了涵盖九个网络安全领域的超过两千道题目。这一流程不仅保证了数据的多样性与公正性,也为后续模型评估奠定了可靠基础。
特点
SecEval数据集作为首个专注于评估基础模型网络安全知识的基准,展现出鲜明的专业特性。其题目覆盖了软件安全、应用安全、系统安全、网络安防、密码学、内存安全、渗透测试等九大核心领域,构成了一个多维度的知识评估体系。数据集以多选题形式呈现,每道题目均附有详细的元数据,包括来源、主题标签及关键词,便于深入分析。尽管存在领域间题目分布不均的局限,但其基于权威文献的生成方式确保了问题的专业深度与时效性。该数据集不仅为模型性能提供了量化指标,更揭示了当前大语言模型在网络安全知识掌握上的差距与挑战。
使用方法
SecEval数据集为研究人员提供了系统评估模型网络安全知识的标准工具。用户可通过HuggingFace平台直接加载数据集,或下载原始JSON文件进行本地处理。数据集中的每条记录包含唯一标识、问题描述、选项列表、正确答案及主题分类,支持灵活的评估脚本开发。研究团队已开源配套的评估代码,用户可据此对自有模型进行测试,并参照公开的排行榜进行性能对比。该数据集适用于模型预训练知识检验、领域适应性微调效果评估等多种场景,其结构化设计便于集成到自动化评估流水线中,推动网络安全领域大模型研究的深入发展。
背景与挑战
背景概述
随着大语言模型的崛起,网络安全领域正经历一场深刻变革,模型在知识问答、漏洞挖掘等任务中展现出巨大潜力。然而,现有评估体系缺乏对模型网络安全专业知识的系统化测评。为此,宣武AI实验室于2023年推出了SecEval基准数据集,这是首个专门用于评估基础模型网络安全知识的综合性基准。该数据集涵盖软件安全、应用安全、系统安全等九大领域,通过GPT-4基于权威教材、行业标准等生成超过2000道选择题,旨在填补该领域评估工具的空白,为模型能力诊断与研究提供关键支撑。
当前挑战
SecEval致力于解决基础模型在网络安全领域知识评估的核心挑战,其首要难题在于如何构建一个既全面又平衡的跨领域知识测评体系。当前数据集中各主题分布不均,部分领域如密码学仅包含14道题,而系统安全题目多达1065道,这种失衡可能影响评估的全面性。在构建过程中,团队面临如何从海量专业文献中高效提取关键知识并转化为高质量题目的挑战,需通过分层解析、内容采样与多轮GPT-4迭代生成来确保题目的准确性与多样性,同时避免因生成模型固有偏差导致的知识覆盖不全问题。
常用场景
经典使用场景
在网络安全领域,随着大语言模型的兴起,评估其专业知识水平成为关键需求。SecEval数据集通过涵盖软件安全、应用安全、系统安全等九大领域的2000余道多选题,为研究人员提供了一个标准化的基准测试平台。该数据集常用于对基础模型进行系统性评估,揭示模型在网络安全知识方面的掌握程度,从而推动模型在漏洞挖掘、安全问答等任务中的性能优化。
实际应用
在实际应用中,SecEval被广泛用于安全智能系统的开发与部署。企业可利用该数据集测试和比较不同大语言模型在网络安全任务中的表现,从而选择适合的模型用于自动化漏洞检测、安全警报分析和渗透测试辅助。此外,教育机构也能借助这一基准设计课程评估工具,提升网络安全人才培养的针对性和效率。
衍生相关工作
基于SecEval数据集,多项经典研究工作得以展开。例如,研究团队利用该基准对GPT-4、Yi-6B等十种前沿基础模型进行了全面评估,揭示了模型在加密学、内存安全等子领域的性能差异。这些评估结果不仅催生了针对模型安全知识增强的微调方法,还激发了跨领域研究,如将安全知识融入模型预训练流程,以提升智能系统在真实威胁环境中的鲁棒性。
以上内容由遇见数据集搜集并总结生成


