AI4Industry/MolParser-7M
收藏Hugging Face2025-01-25 更新2024-12-14 收录
下载链接:
https://hf-mirror.com/datasets/AI4Industry/MolParser-7M
下载链接
链接失效反馈官方服务:
资源简介:
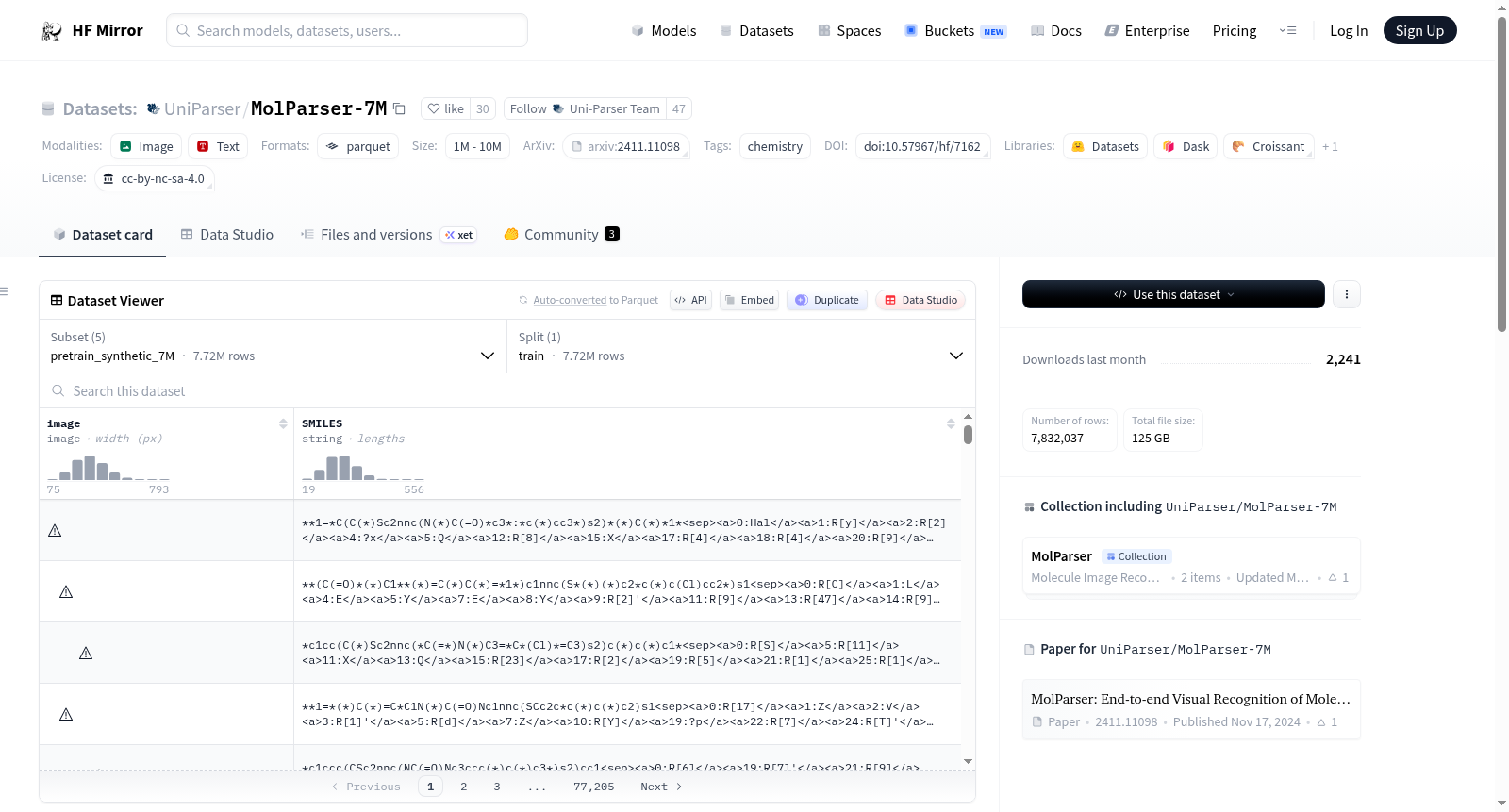
MolParser-7M数据集包含近800万对图像-SMILES数据,用于训练和评估MolParser模型,该模型旨在从图像中识别分子结构。数据集分为训练集、验证集和测试集。训练集包含超过770万的数据,验证集包含403个数据,测试集包含20k个从真实专利或论文中裁剪的分子结构图像,分为普通分子结构和Markush结构的子集。所有数据集的图像和SMILES对都是配对的,且SMILES格式为论文中提出的扩展格式。
The MolParser-7M dataset contains nearly 8 million paired image-SMILES data, used for training and evaluating the MolParser model, which aims to recognize molecular structures from images. The dataset is divided into training, validation, and test sets. The training set contains more than 7.7 million data, the validation set contains 403 data, and the test set contains 20k molecule structure images cropped from real patents or papers, divided into ordinary and Markush structure subsets. All datasets have paired images and SMILES, with the SMILES format being the extended format proposed in the paper.
提供机构:
AI4Industry
搜集汇总
数据集介绍
构建方式
在化学信息学领域,分子结构识别是连接视觉信息与机器可读表示的关键桥梁。MolParser-7M数据集的构建采用了分阶段合成与人工标注相结合的策略。其核心部分包含超过770万条合成训练数据,通过算法生成分子图像及其对应的扩展SMILES格式标注,确保了大规模预训练数据的多样性与可控性。此外,数据集还纳入了从真实专利或论文中裁剪的分子结构图像,并辅以精细的人工标注数据,用于监督微调阶段,从而有效弥合合成数据与真实应用场景之间的分布差距。
使用方法
针对分子结构视觉解析任务,该数据集提供了清晰的使用路径。研究者可首先利用`pretrain_synthetic_7M`配置中的大规模合成数据对模型进行预训练,以学习基础的图像到SMILES序列的映射能力。随后,可加载`sft_real`配置中的人工标注真实数据对模型进行监督微调,提升其在真实复杂场景下的泛化性能。在模型开发过程中,`valid`配置中的验证集可用于快速监控训练进展。最终,模型性能可在`test_simple_10k`与`test_markush_10k`两个测试集上进行全面评估,分别对应不同复杂度的真实世界分子图像。
背景与挑战
背景概述
在化学信息学与人工智能交叉领域,分子结构的光学化学结构识别(OCSR)长期面临从复杂图像中准确提取分子表示的挑战。MolParser-7M数据集由AI4Industry团队于2025年构建,其核心研究聚焦于开发端到端的视觉识别模型,以解析真实场景下的分子结构图像。该数据集通过提供近八百万对图像与扩展SMILES格式的配对数据,显著推动了分子结构自动解析技术的发展,为药物发现与材料科学等领域的智能化进程奠定了数据基础。
当前挑战
该数据集旨在解决分子结构图像识别中的领域挑战,包括对多样化、低质量真实场景图像的鲁棒性解析,以及复杂化学结构(如Markush结构)的准确表示。在构建过程中,挑战主要体现在大规模合成数据的生成与真实世界图像的高质量标注上,需平衡数据多样性、化学正确性与标注一致性,同时确保扩展SMILES格式能有效捕获分子结构的视觉与语义信息。
常用场景
经典使用场景
在化学信息学与计算化学领域,分子结构的视觉识别是连接文献图像与机器可读数据的关键桥梁。MolParser-7M数据集以其近八百万规模的图像-SMILES配对数据,为端到端的分子结构识别模型提供了核心训练资源。该数据集最经典的使用场景在于训练深度学习模型,使其能够直接从科学文献、专利文档等真实场景中截取的分子结构图像中,自动解析并生成标准化的SMILES字符串表示。这种能力极大地推动了光学化学结构识别(OCSR)技术的发展,使得从海量非结构化图像中高效提取结构化分子信息成为可能。
解决学术问题
该数据集主要致力于解决化学信息学中长期存在的学术挑战,即如何精准、自动化地从多样且复杂的真实世界图像中识别分子结构。传统方法往往受限于图像质量、绘制风格的多变性以及复杂结构(如马库什结构)的表示难题。MolParser-7M通过提供大规模合成数据与真实标注数据相结合的训练集,以及专门设计的WildMol基准测试集,为研究者构建鲁棒、通用的视觉识别模型奠定了数据基础。其意义在于弥合了化学视觉信息与数字化表示之间的鸿沟,为后续的分子性质预测、药物发现等下游任务提供了高质量的数据入口。
实际应用
在实际应用层面,MolParser-7M数据集支撑的技术可直接应用于药物研发与化学研究的多个环节。例如,在药物专利分析中,系统可以自动扫描并提取专利文档中数以万计的分子结构图,快速构建可搜索的分子数据库。在学术出版领域,该技术能够辅助化学家从历史文献或新发表的研究论文中批量提取化合物信息,加速知识挖掘与整合。此外,它也为化学教育工具的开发提供了可能,例如开发能够自动识别并解释手绘或印刷分子结构图的教学辅助软件。
数据集最近研究
最新研究方向
在化学信息学领域,分子结构图像识别正成为连接视觉计算与分子表征的关键桥梁。MolParser-7M数据集凭借其近八百万规模的图像-SMILES配对数据,为端到端分子结构视觉解析模型提供了坚实的训练基础。当前研究前沿聚焦于利用该数据集的大规模合成数据预训练结合真实场景图像微调,以提升模型在复杂真实环境如专利或论文图像中的泛化能力。相关热点事件包括基于该数据集组织的OCSR竞赛,旨在推动开放化学结构识别技术的进步。这一工作对加速药物发现、材料科学等领域的自动化信息提取具有深远意义,为多模态人工智能在科学计算中的应用开辟了新路径。
以上内容由遇见数据集搜集并总结生成


