bfcl_v3
收藏魔搭社区2026-05-16 更新2025-06-21 收录
下载链接:
https://modelscope.cn/datasets/AI-ModelScope/bfcl_v3
下载链接
链接失效反馈官方服务:
资源简介:
# Berkeley Function Calling Leaderboard
The Berkeley function calling leaderboard is a live leaderboard to evaluate the ability of different LLMs to call functions (also referred to as tools).
We built this dataset from our learnings to be representative of most users' function calling use-cases, for example, in agents, as a part of enterprise workflows, etc.
To this end, our evaluation dataset spans diverse categories, and across multiple languages.
Checkout the Leaderboard at [gorilla.cs.berkeley.edu/leaderboard.html](https://gorilla.cs.berkeley.edu/leaderboard.html)
and our release blogs:
[BFCL V1](https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html): Our initial BFCL release
[BFCL V2](https://gorilla.cs.berkeley.edu/blogs/12_bfcl_v2_live.html): Our second release, employing enterprise and OSS-contributed live data
[BFCL V3](https://gorilla.cs.berkeley.edu/blogs/13_bfcl_v3_multi_turn.html#composition): Introduces multi-turn and multi-step function calling scenarios
**_Latest Version Release Date_**: 09/22/2024
**_Original Release Date_**: 02/26/2024
## Evaluation
**Check out the EvalScope [best practices](https://evalscope.readthedocs.io/zh-cn/latest/third_party/bfcl_v3.html) and start a model evaluation with just one click!**
## Dataset Composition
We break down our dataset into our 3 major releases. The composition of each release is as follows:
**BFCL V1**:

**BFCL V2 Live**:
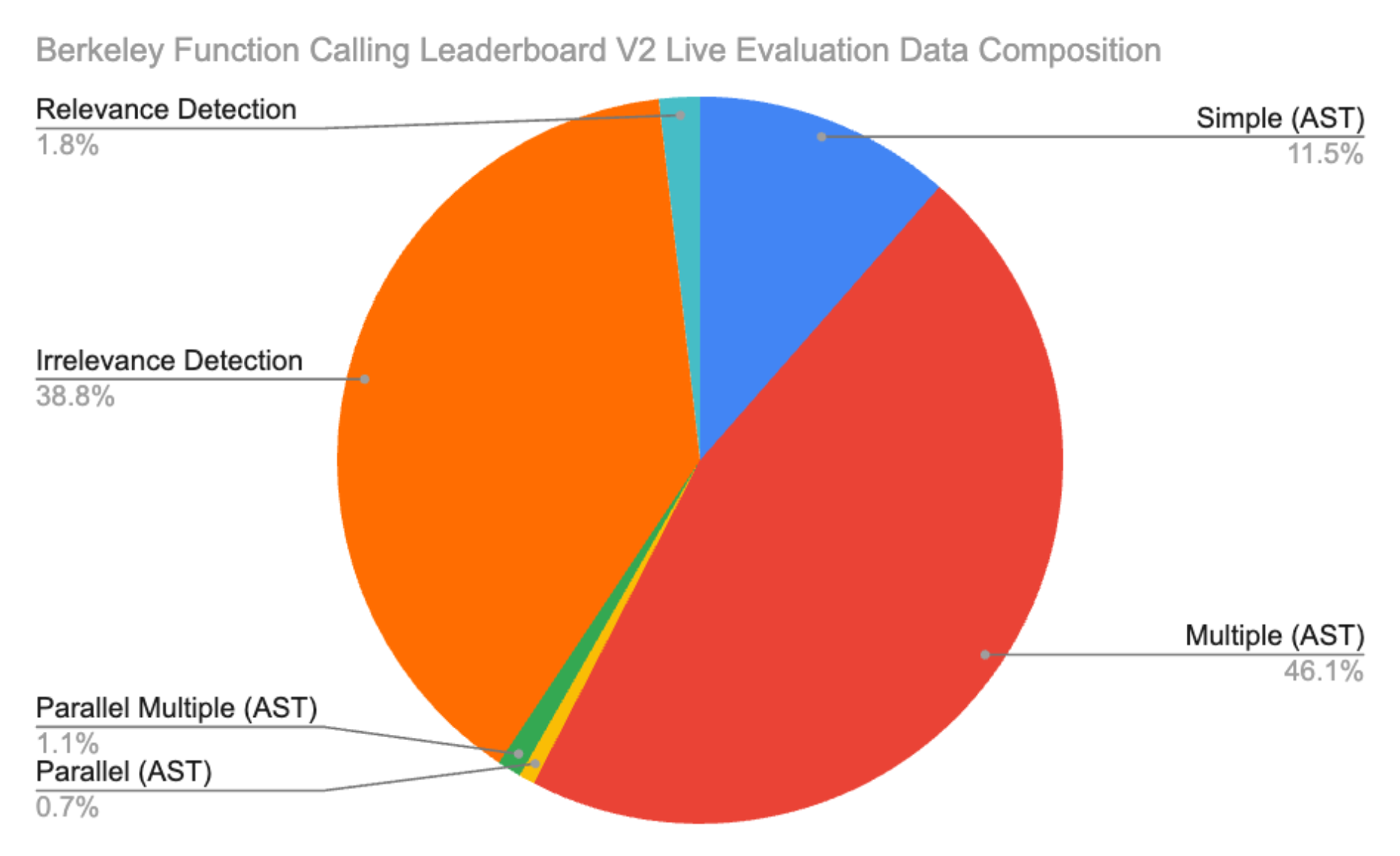
**BFCL V3 Multi-Turn**:
<p align="center">
<img src="https://gorilla.cs.berkeley.edu/assets/img/blog_post_13_data_composition.png" alt="BFCL V3 data composition"/>
</p>
### Dataset Description
## BFCL V1:
In our first release, the majority of our evaluation is broken into two categories:
- **Python**: Simple Function, Multiple Function, Parallel Function, Parallel Multiple Function
- **Non-Python**: Chatting Capability, Function Relevance Detection, REST API, SQL, Java, Javascript
#### Python
**Simple (400 AST/100 Exec)**: Single function evaluation contains the simplest but most commonly seen format, where the user supplies a single JSON function document, with one and only one function call being invoked.
**Multiple Function (200 AST/50 Exec)**: Multiple function category contains a user question that only invokes one function call out of 2 to 4 JSON function documentations. The model needs to be capable of selecting the best function to invoke according to user-provided context.
**Parallel Function (200 AST/50 Exec)**: Parallel function is defined as invoking multiple function calls in parallel with one user query. The model needs to digest how many function calls need to be made and the question to model can be a single sentence or multiple sentence.
**Parallel Multiple Function (200 AST/40 Exec)**: Parallel Multiple function is the combination of parallel function and multiple function. In other words, the model is provided with multiple function documentation, and each of the corresponding function calls will be invoked zero or more times.
Each category has both AST and its corresponding executable evaluations. In the executable evaluation data, we manually write Python functions drawing inspiration from free REST API endpoints (e.g. get weather) and functions (e.g. linear regression) that compute directly. The executable category is designed to understand whether the function call generation is able to be stably utilized in applications utilizing function calls in the real world.
#### Non-Python Evaluation
While the previous categories consist of the majority of our evaluations, we include other specific categories, namely Chatting Capability, Function Relevance Detection, REST API, SQL, Java, and JavaScript, to evaluate model performance on diverse scenarios and support of multiple programming languages, and are resilient to irrelevant questions and function documentations.
**Chatting Capability (200)**: In Chatting Capability, we design scenarios where no functions are passed in, and the users ask generic questions - this is similar to using the model as a general-purpose chatbot. We evaluate if the model is able to output chat messages and recognize that it does not need to invoke any functions. Note the difference with “Relevance” where the model is expected to also evaluate if any of the function inputs are relevant or not. We include this category for internal model evaluation and exclude the statistics from the live leaderboard. We currently are working on a better evaluation of chat ability and ensuring the chat is relevant and coherent with users' requests and open to suggestions and feedback from the community.
**Function Relevance Detection (240)**: In function relevance detection, we design scenarios where none of the provided functions are relevant and supposed to be invoked. We expect the model's output to be a non-function-call response. This scenario provides insight into whether a model will hallucinate on its functions and parameters to generate function code despite lacking the function information or instructions from the users to do so.
**REST API (70)**: A majority of the real-world API calls are from REST API calls. Python mainly makes REST API calls through `requests.get()`, `requests.post()`, `requests.delete()`, etc that are included in the Python requests library. `GET` requests are the most common ones used in the real world. As a result, we include real-world `GET` requests to test the model's capabilities to generate executable REST API calls through complex function documentation, using `requests.get()` along with the API's hardcoded URL and description of the purpose of the function and its parameters. Our evaluation includes two variations. The first type requires passing the parameters inside the URL, called path parameters, for example, the `{Year}` and `{CountryCode}` in `GET` `/api/v3/PublicHolidays/{Year}/{CountryCode}`. The second type requires the model to put parameters as key/value pairs into the params and/or headers of `requests.get(.)`. For example, `params={'lang': 'fr'}` in the function call. The model is not given which type of REST API call it is going to make but needs to make a decision on how it's going to be invoked.
For REST API, we use an executable evaluation to check for the executable outputs' effective execution, response type, and response JSON key consistencies. On the AST, we chose not to perform AST evaluation on REST mainly because of the immense number of possible answers; the enumeration of all possible answers is exhaustive for complicated defined APIs.
**SQL (100)**: SQL evaluation data includes our customized `sql.execute` functions that contain sql_keyword, table_name, columns, and conditions. Those four parameters provide the necessary information to construct a simple SQL query like `SELECT column_A from table_B where column_C == D` Through this, we want to see if through function calling, SQL query can be reliably constructed and utilized rather than training a SQL-specific model. In our evaluation dataset, we restricted the scenarios and supported simple keywords, including `SELECT`, `INSERT INTO`, `UPDATE`, `DELETE`, and `CREATE`. We included 100 examples for SQL AST evaluation. Note that SQL AST evaluation will not be shown in our leaderboard calculations. We use SQL evaluation to test the generalization ability of function calling for programming languages that are not included in the training set for Gorilla OpenFunctions-v2. We opted to exclude SQL performance from the AST evaluation in the BFCL due to the multiplicity of methods to construct SQL function calls achieving identical outcomes. We're currently working on a better evaluation of SQL and are open to suggestions and feedback from the community. Therefore, SQL has been omitted from the current leaderboard to pave the way for a more comprehensive evaluation in subsequent iterations.
**Java (100) and Javascript (50)**: Despite function calling formats being the same across most programming languages, each programming language has language-specific types. For example, Java has the `HashMap` type. The goal of this test category is to understand how well the function calling model can be extended to not just Python type but all the language-specific typings. We included 100 examples for Java AST evaluation and 70 examples for Javascript AST evaluation.
The categories outlined above provide insight into the performance of different models across popular API call scenarios, offering valuable perspectives on the potential of function-calling models.
## BFCL V2 Live:
Our second release uses real world data in order to better measure LLM function calling performance in real world uses cases. To this end, there is a greater focus on the multiple function scenario, as well as relevance/irrelevance detection. The data in BFCL V2 Live is comprised of **simple (258)**, **multiple (1037)**, **parallel (16)**, and **parallel multiple (24)** categories, similar to those described in BFCL V1. In addition to these, we have the **Relevance** category, which can be broken down into the following two subcategories.
#### Relevance Evaluation
**Irrelevance Detection (875)**: The scenario where none of the function choices provided are relevant to the user query and none should be invoked. We expect the model to not output a function call; the model can either output a message explaining why the function provided are not relevant or simply output a non-function call response (e.g., an empty list).
**Relevance Detection (41)**: The opposite of irrelevance detection. The scenario where at least one of the function choices provided are relevant to the user query and should be invoked, but the way the user prompt or the function doc is stated means that there could be infinitely many correct function calls and impossible to use a pre-defined possible answer set to evaluate. We expect the model to output some function call (one or multiple) that is relevant to the user query; we don't check for the correctness of the function call in this category (eg, correct parameter value).
## BFCL V3:
This release introduces scenarios that require multi-step function calling, where multiple internal function calls can be used to address a single user request, as well as multi-turn function calls, which involve multiple exchanges or function calls between user and assistant. Within our multi-step and multi-turn data are the following categories:
**Base Multi-Turn (200)**: This category covers the foundational yet sufficiently diverse basic multi-turn interactions. In this category, we provide complete information to call each function (either through current turn question, execution result from previous turn, or initial state configuration)
**Augmented Multi-Turn (800)**: This category introduce additional complexity, such as ambiguous prompts or situations where the model must process multiple pieces of information across turns (similar to Multihop QA), requiring models to handle more nuanced decision-making, disambiguation, and conditional logic across multiple turns.
The augmented multiturn data is comprised of the followin subcategories:
- **Missing Parameters (200)**: This dataset challenges the model to identify required missing information that cannot be retrieved elsewhere in the system. In this scenario, we expect the LLM to ask for a follow-up to clarify the misinformation. This is distinct from certain entries in the Core Multi-Turn dataset where the question has implicit intent that can be answered by referencing the backend system.
- **Missing Functions (200)**: This scenario denotes when we expect the model to recognize that no action should be taken given the lack of functions provided. If the LLM raises that concern, we then supply it with the hold-out functions that can successfully perform user intended tasks. Note that the Core dataset and the Missing Function dataset essentially contains the same sequence of actions except for the latter we hold-out a subset of functions on execution path to further challenge the model's inference ability.
- **Long-Context (200)**: This dataset challenges the model's resilience in long context scenarios on function calling. We inject random objects (e.g. hundreds of files in one directory or thousands of booking records) to mimic real world API output, which tend to be overtly informative. Here, we aim to test the model's ability to grasp the core information from an overwhelmingly large context.
- **Composite (200)**: Composite Category seeks to combine all three scenarios above to create an exceptionally hard challenge that, despite being rare, is important to handle when using autonomous agents at scale. Through this category, we want to convince the audience that a good model performance in this category offers a strong signal that LLMs can function as autonomous agents at scale despite rare and extremely difficult scenarios.
### Contributing
All the models, and data used to train the models are released under Apache 2.0.
Gorilla is an open source effort from UC Berkeley and we welcome contributors.
Please email us your comments, criticisms, and questions.
More information about the project can be found at https://gorilla.cs.berkeley.edu/
### BibTex
```bibtex
@misc{berkeley-function-calling-leaderboard,
title={Berkeley Function Calling Leaderboard},
author={Fanjia Yan and Huanzhi Mao and Charlie Cheng-Jie Ji and Tianjun Zhang and Shishir G. Patil and Ion Stoica and Joseph E. Gonzalez},
howpublished={\url{https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html}},
year={2024},
}
```
# 伯克利函数调用排行榜(Berkeley Function Calling Leaderboard)
伯克利函数调用排行榜是一个实时排行榜,用于评估不同大语言模型(Large Language Model,简称LLM)的函数调用(也称作工具调用)能力。我们基于实际应用场景构建了该评测数据集,以覆盖大多数用户的函数调用使用场景,例如在AI智能体(AI Agent)、企业工作流中等场景。为此,我们的评测数据集涵盖多元类别,并支持多语言。
您可访问以下链接查看该排行榜:[gorilla.cs.berkeley.edu/leaderboard.html](https://gorilla.cs.berkeley.edu/leaderboard.html),以及我们的系列发布博客:
- [BFCL V1](https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html):我们的初始BFCL版本发布
- [BFCL V2](https://gorilla.cs.berkeley.edu/blogs/12_bfcl_v2_live.html):我们的第二版发布,采用企业级与开源社区贡献的实时数据
- [BFCL V3](https://gorilla.cs.berkeley.edu/blogs/13_bfcl_v3_multi_turn.html#composition):引入多轮与多步函数调用场景
**_最新版本发布日期_**:2024年9月22日
**_原始发布日期_**:2024年2月26日
## 评测
**欢迎查看EvalScope [最佳实践指南](https://evalscope.readthedocs.io/zh-cn/latest/third_party/bfcl_v3.html),一键启动模型评测!**
## 数据集构成
我们将数据集划分为三个主要发布版本,各版本的构成如下:
**BFCL V1**:

**BFCL V2 实时版**:

**BFCL V3 多轮版**:
<p align="center">
<img src="https://gorilla.cs.berkeley.edu/assets/img/blog_post_13_data_composition.png" alt="BFCL V3 数据构成"/>
</p>
### 数据集详情
#### BFCL V1:
在首个发布版本中,我们的评测主体分为两大类别:
- **Python类**:单函数调用、多函数选择、并行函数调用、并行多函数调用
- **非Python类**:聊天能力、函数相关性检测、REST API(表述性状态转移应用程序编程接口,Representational State Transfer Application Programming Interface)调用、SQL(结构化查询语言,Structured Query Language)、Java、Javascript
##### Python类
注:本类别中AST代表抽象语法树(Abstract Syntax Tree),Exec代表可执行(Executable)。
**单函数调用(400 AST/100 Exec)**:单函数评测采用最简单但最常见的格式,即用户仅提供一份JSON函数文档,且仅需调用且仅能调用一个函数。
**多函数选择(200 AST/50 Exec)**:该类别下的用户问题仅需从2至4份JSON函数文档中选择最合适的函数进行调用。模型需具备根据用户提供的上下文挑选最优函数的能力。
**并行函数调用(200 AST/50 Exec)**:并行函数调用指通过一条用户查询并行发起多个函数调用。模型需识别所需调用的函数数量,用户查询可包含单句或多句内容。
**并行多函数调用(200 AST/40 Exec)**:并行多函数调用是并行函数调用与多函数选择的结合。换言之,模型将收到多份函数文档,且每个对应函数可被调用零次或多次。
每个类别均包含抽象语法树(AST)评测与对应的可执行性评测。在可执行评测数据中,我们参考公开REST API端点(如获取天气信息)与可直接计算的函数(如线性回归)手动编写Python函数。可执行类别旨在验证函数调用生成结果能否在实际函数调用应用中稳定落地。
##### 非Python类评测
除上述主体评测类别外,我们还增设了其他特定类别,包括聊天能力、函数相关性检测、REST API调用、SQL、Java与Javascript,以评测模型在多元场景下的表现与多编程语言支持能力,同时验证模型对无关问题与函数文档的鲁棒性。
**聊天能力(200样本)**:在聊天能力评测中,我们设计了无需传入任何函数的场景,用户仅提出通用问题——这与将模型用作通用聊天机器人的场景一致。我们将评测模型能否输出聊天回复,并识别出无需调用任何函数的场景。请注意该类别与“相关性检测”的区别:后者要求模型同时评估任意函数输入是否相关。该类别仅用于内部模型评测,未纳入实时排行榜统计。目前我们正优化聊天能力的评测方案,确保回复与用户请求相关且连贯,并欢迎社区提出建议与反馈。
**函数相关性检测(240样本)**:在该评测场景中,所有提供的函数均与用户查询无关,无需发起任何函数调用。我们期望模型输出非函数调用格式的回复。该场景可用于探究模型是否会在缺乏函数信息或用户调用指令的情况下,虚构函数与参数以生成函数代码。
**REST API调用(70样本)**:现实世界中的API调用大多为REST API调用。Python主要通过`requests`库中的`requests.get()`、`requests.post()`、`requests.delete()`等方法发起REST API调用,其中`GET`请求是最常见的调用方式。因此,我们纳入真实`GET`请求场景,测试模型能否根据复杂的函数文档生成可执行的REST API调用代码,包括使用`requests.get()`搭配API硬编码URL、函数用途说明与参数说明。我们的评测包含两种变体:第一种要求将参数嵌入URL路径中(路径参数),例如`GET /api/v3/PublicHolidays/{Year}/{CountryCode}`中的`{Year}`与`{CountryCode}`;第二种要求模型将参数以键值对形式放入`requests.get(.)`的`params`和/或`headers`中,例如函数调用中的`params={'lang': 'fr'}`。模型不会被预先告知需调用的REST API类型,需自行决定调用方式。
针对REST API评测,我们采用可执行性评测,以验证输出能否有效执行、响应类型是否正确以及响应JSON的键是否一致。在抽象语法树(AST)评测环节,我们未对REST API类别进行评测,主要原因是可能的答案数量极多,对复杂定义的API枚举所有可能答案的成本过高。
**SQL评测(100样本)**:SQL评测数据包含我们自定义的`sql.execute`函数,该函数包含sql_keyword、table_name、columns与conditions四个参数,可用于构建如`SELECT column_A from table_B where column_C == D`这类简单SQL查询。我们希望通过该评测验证:能否通过函数调用可靠地构建并使用SQL查询,而非仅针对SQL场景训练专用模型。在评测数据集中,我们限定了场景并支持`SELECT`、`INSERT INTO`、`UPDATE`、`DELETE`与`CREATE`等简单关键字。我们共纳入100个SQL AST评测样本。请注意,SQL AST评测结果未纳入排行榜计算。我们使用SQL评测来测试函数调用模型对Gorilla OpenFunctions-v2训练集中未覆盖的编程语言的泛化能力。由于构建SQL函数调用的方式多样且可达到相同效果,我们未将SQL性能纳入BFCL的AST评测环节。目前我们正优化SQL评测方案,并欢迎社区提出建议与反馈。因此,当前版本的排行榜未纳入SQL评测结果,为后续迭代中的全面评测预留空间。
**Java(100样本)与Javascript(50样本)**:尽管大多数编程语言的函数调用格式大同小异,但每种语言都有其专属的类型系统,例如Java的`HashMap`类型。该测试类别的目标是探究函数调用模型能否适配Python之外的其他语言专属类型系统。我们纳入了100个Java AST评测样本与70个Javascript AST评测样本。
上述评测类别覆盖了主流API调用场景,可为不同模型的函数调用性能提供多维度的参考价值,助力评估函数调用模型的应用潜力。
## BFCL V2 实时版:
我们的第二版发布采用真实世界数据,以更精准地评测大语言模型在实际应用中的函数调用性能。为此,该版本更侧重多函数调用场景,以及相关性/非相关性检测任务。BFCL V2 实时版的数据由**单函数调用(258)**、**多函数选择(1037)**、**并行函数调用(16)**与**并行多函数调用(24)**四类构成,与BFCL V1中的类别类似。除此之外,我们还增设了**相关性评测**类别,可分为以下两个子类别:
### 相关性评测
**非相关性检测(875样本)**:该场景下,所有提供的函数选项均与用户查询无关,无需发起任何函数调用。我们期望模型不输出函数调用格式的内容,可选择输出解释为何提供的函数不相关的回复,或直接输出非函数调用格式的响应(例如空列表)。
**相关性检测(41样本)**:与非相关性检测相反,该场景下至少有一个提供的函数选项与用户查询相关且应被调用,但由于用户提示或函数文档的表述方式,可能存在无限多的正确函数调用,无法使用预定义的答案集进行评测。我们期望模型输出与用户查询相关的函数调用(一个或多个),该类别不评测函数调用参数的正确性。
## BFCL V3:
该版本引入了需要多步函数调用的场景,即通过多个内部函数调用处理单条用户请求,同时也包含多轮函数调用场景,即涉及用户与助手之间的多轮交互或函数调用。在我们的多步与多轮数据中,包含以下类别:
**基础多轮交互(200样本)**:该类别覆盖了基础且足够多元的多轮交互场景。在此类别中,我们为每个函数调用提供完整信息(可通过当前轮次的问题、上一轮的执行结果或初始状态配置获取)。
**增强型多轮交互(800样本)**:该类别引入了更多复杂性,例如歧义提示,或模型需要跨轮次处理多条信息的场景(类似多跳问答),要求模型在多轮交互中处理更精细的决策、歧义消解与条件逻辑。
增强型多轮数据由以下子类别构成:
- **参数缺失(200样本)**:该数据集用于挑战模型识别无法从系统其他位置获取的必要缺失信息。在此场景中,我们期望大语言模型发起追问以澄清缺失的信息。这与核心多轮数据集中的部分条目不同:后者的问题包含隐含意图,可通过参考后端系统作答。
- **函数缺失(200样本)**:该场景指当模型意识到由于缺少提供的函数,无法执行任何操作的情况。若大语言模型提出该问题,我们将向其提供可完成用户目标的预留函数。请注意,核心数据集与函数缺失数据集的操作序列基本一致,仅在后者中我们预留了部分执行路径上的函数,以进一步挑战模型的推理能力。
- **长上下文(200样本)**:该数据集用于挑战模型在长上下文场景下的函数调用鲁棒性。我们注入随机对象(例如一个目录下的数百个文件或数千条预订记录)以模拟现实世界中信息过载的API输出。我们的目标是测试模型能否从海量上下文中提取核心信息。
- **复合场景(200样本)**:复合类别旨在结合上述所有三类场景,构建极具挑战性的任务——这类场景虽罕见,但在大规模部署自主AI智能体时至关重要。通过该类别,我们希望证明:若模型在该类别中表现良好,则可作为强信号表明,大语言模型能够在罕见且极具难度的场景下大规模部署为自主AI智能体。
### 贡献指南
所有模型与用于训练模型的数据均以Apache 2.0协议开源。
Gorilla是加州大学伯克利分校的开源项目,我们欢迎开发者贡献代码。
欢迎通过邮件向我们反馈意见、批评与疑问。更多项目详情可访问 https://gorilla.cs.berkeley.edu/
### BibTex引用
bibtex
@misc{berkeley-function-calling-leaderboard,
title={伯克利函数调用排行榜(Berkeley Function Calling Leaderboard)},
author={Fanjia Yan and Huanzhi Mao and Charlie Cheng-Jie Ji and Tianjun Zhang and Shishir G. Patil and Ion Stoica and Joseph E. Gonzalez},
howpublished={url{https://gorilla.cs.berkeley.edu/blogs/8_berkeley_function_calling_leaderboard.html}},
year={2024},
}
提供机构:
maas
创建时间:
2025-06-17
搜集汇总
数据集介绍
背景与挑战
背景概述
bfcl_v3是Berkeley Function Calling Leaderboard的第三个版本,专注于评估大语言模型在函数调用任务上的能力,特别引入了多轮和多步函数调用场景,以模拟真实世界中的复杂交互,如代理和企业工作流程。数据集包含多种编程语言和类别,例如Python、Java、REST API和SQL,旨在全面测试模型在多样化场景下的性能,包括基础多轮交互以及增强多轮中的缺失参数、缺失函数、长上下文和复合挑战。
以上内容由遇见数据集搜集并总结生成


