SpeakerVid-5M
收藏arXiv2025-07-14 更新2025-07-16 收录
下载链接:
https://dorniwang.github.io/SpeakerVid-5M/
下载链接
链接失效反馈官方服务:
资源简介:
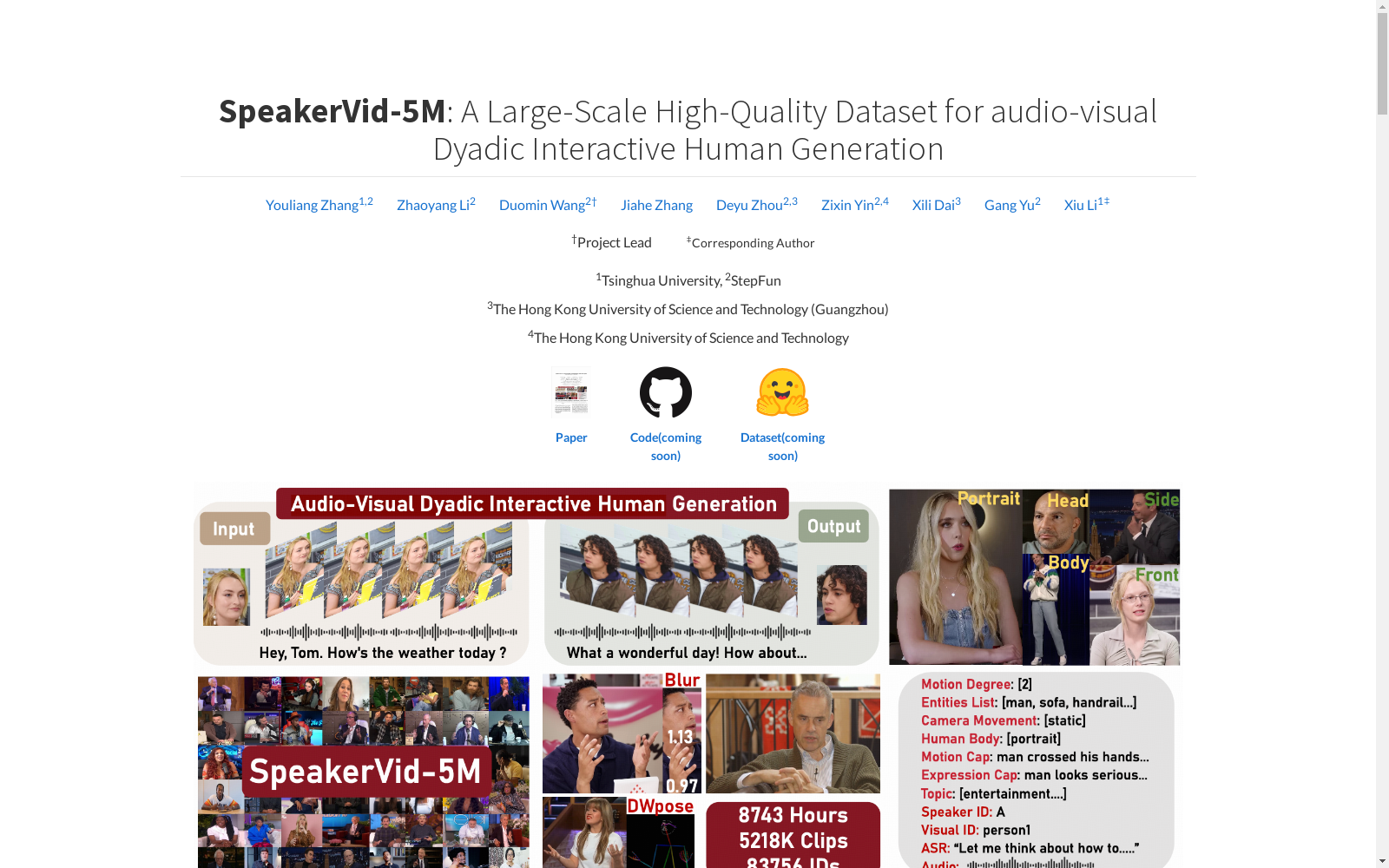
SpeakerVid-5M是一个大规模、高质量的音频-视觉双交互人类生成数据集。该数据集由清华大学、StepFun、香港科技大学(广州)和香港科技大学的研究团队合作创建,旨在推动虚拟人类领域的研究。数据集包含超过8.7万小时的视频数据,超过520万个人物肖像视频片段,涵盖了从单一人谈话、倾听到双人对话等多种互动类型。数据集结构上分为对话分支、单分支、倾听分支和多轮分支,并分为大规模预训练子集和经过精心挑选的高质量子集,以适应不同的研究需求。此外,数据集还提供了自动回归(AR)视频聊天基线模型和相应的评价指标,以供未来研究使用。
SpeakerVid-5M is a large-scale, high-quality human-generated audio-visual bimodal interactive dataset. It was collaboratively developed by research teams from Tsinghua University, StepFun, Hong Kong University of Science and Technology (Guangzhou) and Hong Kong University of Science and Technology, aiming to advance research in the domain of virtual humans. The dataset contains over 87,000 hours of video data and more than 5.2 million human portrait video clips, covering various interaction types including single-person talking, listening, two-person conversations and more. Structurally, the dataset is categorized into four branches: dialogue branch, single-person branch, listening branch and multi-turn branch, and it is split into a large-scale pre-training subset and a carefully curated high-quality subset to cater to diverse research requirements. Additionally, the dataset provides an autoregressive (AR) video chat baseline model and corresponding evaluation metrics for future research use.
提供机构:
清华大学, StepFun, 香港科技大学(广州), 香港科技大学
创建时间:
2025-07-14
原始信息汇总
SpeakerVid-5M 数据集概述
数据集基本信息
- 名称: SpeakerVid-5M
- 类型: 大规模高质量音频-视觉双人交互虚拟人生成数据集
- 总量: 超过8,743小时
- 视频片段数量: 超过520万个人物肖像视频片段
- 数据来源: YouTube
数据集特点
- 多样性: 涵盖多种尺度和交互类型,包括单人讲话、倾听和双人对话
- 结构化维度:
- 交互类型: 分为对话分支、单分支、倾听分支和多轮分支
- 数据质量: 分为大规模预训练子集和高质量监督微调(SFT)子集
数据标注
- 多模态标注: 使用Qwen-VL等模型进行丰富标注
- 细粒度标注:
- 身体组成(全身、半身、头部)
- 摄像机视角(正面、侧面)
- 模糊度评分
- 同步评分
基准测试
- VidChatBench: 提供基于自回归(AR)的视频聊天基线模型、专用指标和测试数据
数据集比较优势
- 每个剪辑仅保留一个人,确保音频和视觉流的干净对齐
- 提供大多数先前工作中缺少的身体组成和摄像机视角的细粒度注释
数据演示
- 不同范围: 全身、半身、头部、侧面
- 分支类型: 对话分支、单分支、倾听分支、多轮分支
生成结果
- 提供单人和对话场景的基线方法生成案例
引用信息
bibtex @inproceedings{zhang2025speakervid5m, title={A Large-Scale High-Quality Dataset for audio-visual Dyadic Interactive Human Generation}, author={Zhang, Youliang and Li, Zhaoyang and Wang, Duomin and Zhang, Jiahe and Zhou, Deyu and Yin, Zixin and Dai, Xili and Yu, gang and Xiu, Li}, journal={arxiv}, year={2025} }
搜集汇总
数据集介绍
构建方式
SpeakerVid-5M数据集的构建采用了系统化的多阶段流程,涵盖数据收集、预处理、标注和质量过滤。首先,从YouTube手动收集高质量的双人对话视频,包括访谈、新闻报道和电视节目等多样化的内容。随后,利用SceneDetect进行场景分割,3D-Speaker进行说话人分离,YOLO进行人体检测,SyncNet确保音频与视频的同步。此外,通过ArcFace进行ID校正,确保说话人身份的一致性。数据标注阶段,采用Qwen2.5-VL生成结构化文本描述,包括相机运动、实体列表和身体动作等细节。最后,通过严格的亮度、视频质量、清晰度和音频过滤,确保数据的高质量。
特点
SpeakerVid-5M数据集以其大规模和高多样性著称,包含超过8,743小时的视频数据,涵盖单人和双人交互场景。其特点包括高分辨率(93%的视频为1080P或更高)、丰富的多模态标注(如ASR转录、骨骼序列和运动评分)以及多样的身体构图(全身、半身和侧面视图)。此外,数据集还提供了详细的对话分支和高质量的子集,适用于预训练和微调任务,为音频-视觉交互虚拟人生成提供了全面的支持。
使用方法
SpeakerVid-5M数据集适用于多种音频-视觉生成任务,如虚拟人驱动、唇音同步和多模态对话建模。使用时,研究人员可以根据任务需求选择不同的数据子集,例如利用对话分支训练交互式虚拟人模型,或使用单分支数据进行单人生成任务。数据集提供的丰富标注(如运动评分和ASR转录)可作为条件信号,增强生成模型的细节控制。此外,配套的VidChatBench基准测试可用于评估模型在视频质量、身份一致性和对话连贯性等方面的表现。
背景与挑战
背景概述
SpeakerVid-5M是由清华大学、StepFun等机构的研究团队于2025年发布的大规模高质量音频-视觉双人交互数据集,旨在推动交互式虚拟人生成领域的研究。该数据集包含超过8,743小时的视频素材,涵盖5.2百万个单人视频片段和77万组双人对话对,是首个专注于音频-视觉双人交互任务的开源数据集。其核心研究问题聚焦于如何通过多模态理解实现虚拟人的自主交互能力,为数字新闻播报、虚拟助手等应用提供数据支持。数据集通过精细的标注体系(包括骨骼序列、ASR转录等)和分层质量设计,显著提升了生成模型的真实感和交互连贯性,已成为虚拟人驱动与渲染领域的重要基准资源。
当前挑战
该数据集主要面临三重挑战:在领域问题层面,需解决音频-视觉双模态时序对齐、对话语义连贯性保持以及身份特征一致性维护等核心难题;在构建过程中,面临原始视频中说话人分离与身份校正、跨模态数据清洗(如93%视频需满足1080P清晰度标准)以及大规模标注质量控制等技术挑战;在应用层面,现有模型对复杂手势生成、长时序动作连贯性等细粒度控制仍存在明显性能瓶颈。此外,多轮对话场景下的上下文保持、非对称交互(如倾听状态)的建模等新兴问题也对数据集提出了更高维度的要求。
常用场景
经典使用场景
SpeakerVid-5M数据集在音频-视觉双模态交互式虚拟人生成领域具有广泛的应用价值。该数据集最经典的使用场景是训练和评估能够生成连贯音频-视觉响应的虚拟人模型。研究者可以利用该数据集中的对话分支数据,模拟真实世界中的双人对话场景,训练模型根据输入者的音频-视觉信号生成合适的响应。这种能力对于开发具有交互功能的虚拟助手、数字主播和在线教育应用至关重要。
实际应用
在实际应用方面,SpeakerVid-5M数据集可广泛应用于多个领域。在娱乐产业中,可用于开发更真实的虚拟主播和数字演员;在教育领域,可创建具有自然交互能力的虚拟教师;在客户服务方面,可开发更具亲和力的虚拟客服。此外,该数据集还可用于开发远程会议中的虚拟化身系统,提升在线交流的真实感和沉浸感。
衍生相关工作
基于SpeakerVid-5M数据集,已经衍生出多个重要的研究工作。例如,研究者开发了基于自回归框架的音频-视觉对话生成基线模型,该模型能够联合生成音频和视频响应。此外,还建立了专门的评估基准VidChatBench,用于系统评估生成模型在视频质量、音频-视觉一致性等方面的表现。这些工作为后续研究提供了重要的参考和比较基准。
以上内容由遇见数据集搜集并总结生成


