Street View House Numbers (SVHN) dataset
收藏arXiv2023-12-06 更新2024-06-21 收录
下载链接:
http://ufldl.stanford.edu/housenumbers/
下载链接
链接失效反馈官方服务:
资源简介:
SVHN数据集是由图宾根大学创建的,包含从Google街景中提取的真实房屋号码图像,共有10个类别,每个数字一个类别。该数据集包含73,257个训练样本和26,032个测试样本,以及531,131个额外的简单样本。SVHN数据集主要用于深度学习中的数字分类任务,也被广泛用于生成模型、异常检测和对抗性鲁棒性等任务的基准测试。数据集的创建过程涉及从街景图像中提取房屋号码,并进行分类和分割。SVHN数据集的应用领域包括但不限于图像识别、生成模型评估和数据压缩技术的发展。
The Street View House Numbers (SVHN) dataset was developed by the University of Tübingen. It comprises real-world house number images extracted from Google Street View, with 10 categories corresponding to each individual digit. The dataset includes 73,257 training samples, 26,032 test samples, and 531,131 additional easy samples. Primarily utilized for digit classification tasks in deep learning, the SVHN dataset has also been widely adopted as a benchmark for generative models, anomaly detection, adversarial robustness and other related tasks. The dataset creation process involves extracting house numbers from Street View images, followed by classification and segmentation annotation. Application areas of the SVHN dataset include, but are not limited to, image recognition, generative model evaluation and the development of data compression technologies.
提供机构:
图宾根大学
创建时间:
2023-10-30
搜集汇总
数据集介绍
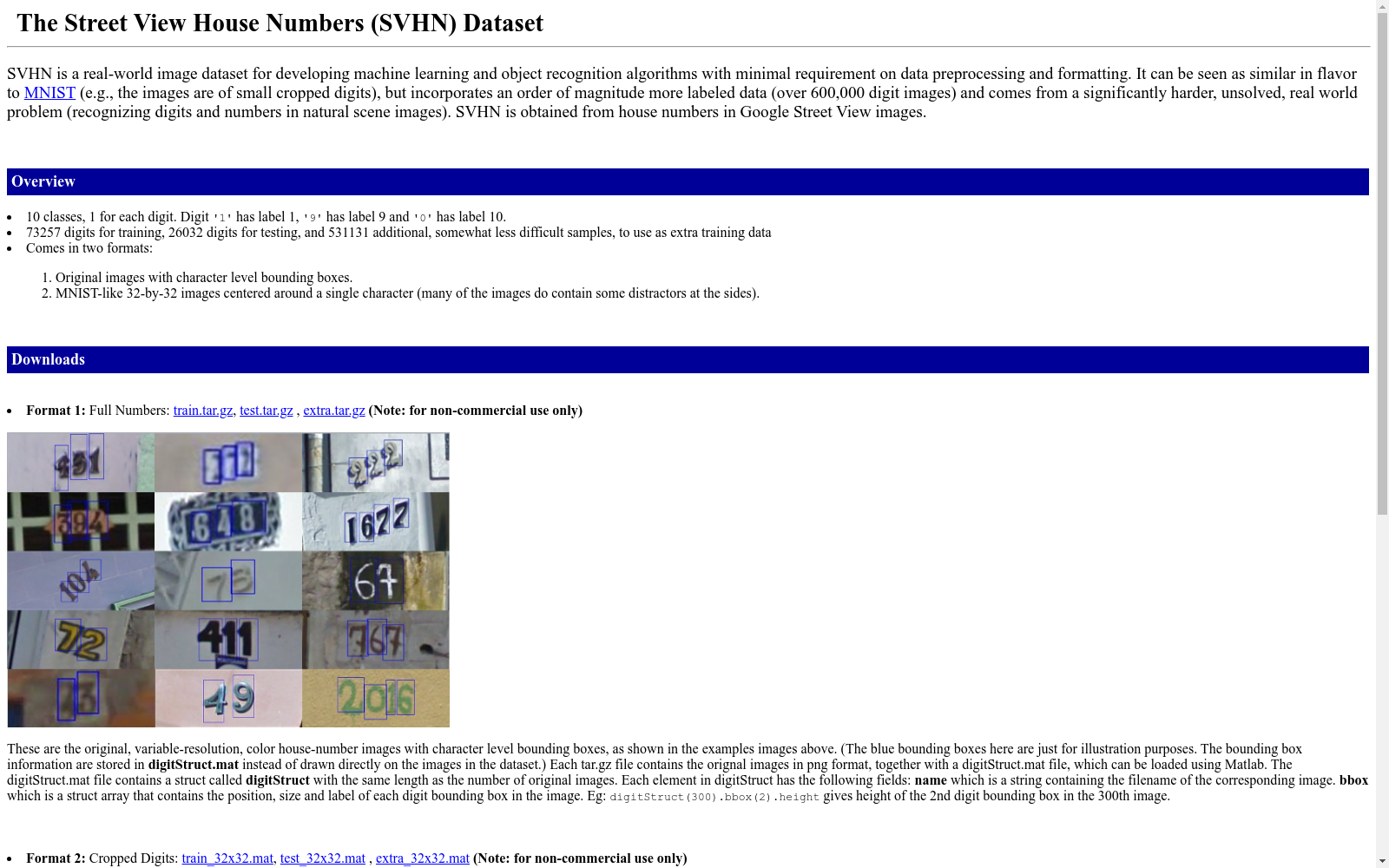
构建方式
SVHN数据集的构建基于从Google Street View中采集的真实房屋号码图像,涵盖了10个类别,每个类别代表一个数字。数据集被划分为三个部分:包含73,257个样本的训练集Dtrain,26,032个样本的测试集Dtest,以及一个较少使用的额外训练集,包含531,131个更简单的样本。为了解决训练集和测试集之间的分布不匹配问题,研究者提出了一种新的分割方法,即将原始的Dtrain和Dtest合并后重新洗牌并重新分割,以确保新的训练集和测试集来自同一分布。
特点
SVHN数据集以其丰富的真实世界图像和多样的数字类别著称,常被视为MNIST数据集的更复杂变体。然而,该数据集的一个显著特点是其训练集和测试集之间存在分布不匹配的问题,这一问题在分类任务中影响较小,但在概率生成模型(如变分自编码器和扩散模型)的评估中影响显著。通过重新混合和分割数据集,这一问题得到了有效缓解。
使用方法
SVHN数据集主要用于深度学习中的数字分类任务,同时也被广泛应用于生成模型、分布外检测和对抗鲁棒性等任务。在使用SVHN进行生成模型评估时,建议采用重新混合后的数据集分割,以避免分布不匹配带来的评估偏差。此外,通过使用Fréchet Inception Distance(FID)和Inception Score(IS)等指标,可以对生成模型的样本质量进行客观评估。
背景与挑战
背景概述
Street View House Numbers (SVHN) 数据集是计算机视觉领域中一个广受欢迎的基准数据集,由Tübingen大学的研究人员于2011年创建。该数据集包含从Google Street View中提取的真实世界房屋号码图像,涵盖10个类别,每个类别代表一个数字。SVHN数据集通常被视为比MNIST数据集更具挑战性的变体,因其包含彩色图像和更复杂的背景。该数据集不仅用于数字分类任务,还被广泛应用于生成模型、分布外检测和对抗鲁棒性等其他任务。SVHN数据集的创建和广泛使用极大地推动了深度学习领域的发展,特别是在生成模型和图像处理方面。
当前挑战
尽管SVHN数据集在多个领域中表现出色,但其作为生成模型基准数据集的使用面临一个重大挑战:训练集和测试集之间的分布不匹配。具体而言,SVHN的官方训练集和测试集并非来自同一分布,这种分布不匹配对分类任务影响较小,但对概率生成模型的评估产生了严重影响。例如,变分自编码器和扩散模型在评估测试集似然性时会受到误导,导致模型性能的错误评估。此外,构建过程中遇到的挑战包括确保数据集的多样性和代表性,以及处理图像中的复杂背景和噪声。这些问题需要通过重新划分数据集或采用新的评估方法来解决,以确保生成模型的准确性和可靠性。
常用场景
经典使用场景
在计算机视觉领域,Street View House Numbers (SVHN) 数据集因其丰富的真实世界图像而成为深度学习模型的经典基准。SVHN 数据集主要用于数字分类任务,其图像来源于 Google Street View 中的房屋门牌号,包含 10 个类别,每个类别代表一个数字。由于其图像的复杂性和多样性,SVHN 常被视为 MNIST 数据集的更高级变体,广泛应用于生成模型、异常检测和对抗鲁棒性等任务的开发与评估。
解决学术问题
SVHN 数据集解决了在真实世界图像中进行数字识别的学术研究问题。其图像的复杂背景和多样性为模型提供了更具挑战性的训练环境,有助于提升模型在复杂场景下的识别能力。此外,SVHN 数据集的引入促进了生成模型的发展,如变分自编码器(VAEs)和扩散模型,这些模型在数据分布不匹配的情况下仍能有效评估和改进。
衍生相关工作
基于 SVHN 数据集,研究者们开发了多种生成模型和分类算法,推动了计算机视觉领域的进步。例如,生成对抗网络(GANs)和变分自编码器(VAEs)在 SVHN 数据集上的应用,显著提升了图像生成和重建的质量。此外,SVHN 数据集的分布不匹配问题也催生了新的数据集划分方法,如 SVHN-Remix,为生成模型的评估提供了更可靠的基准。
以上内容由遇见数据集搜集并总结生成


