lego_minifigure_captions
收藏Hugging Face2024-11-29 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/armaggheddon97/lego_minifigure_captions
下载链接
链接失效反馈官方服务:
资源简介:
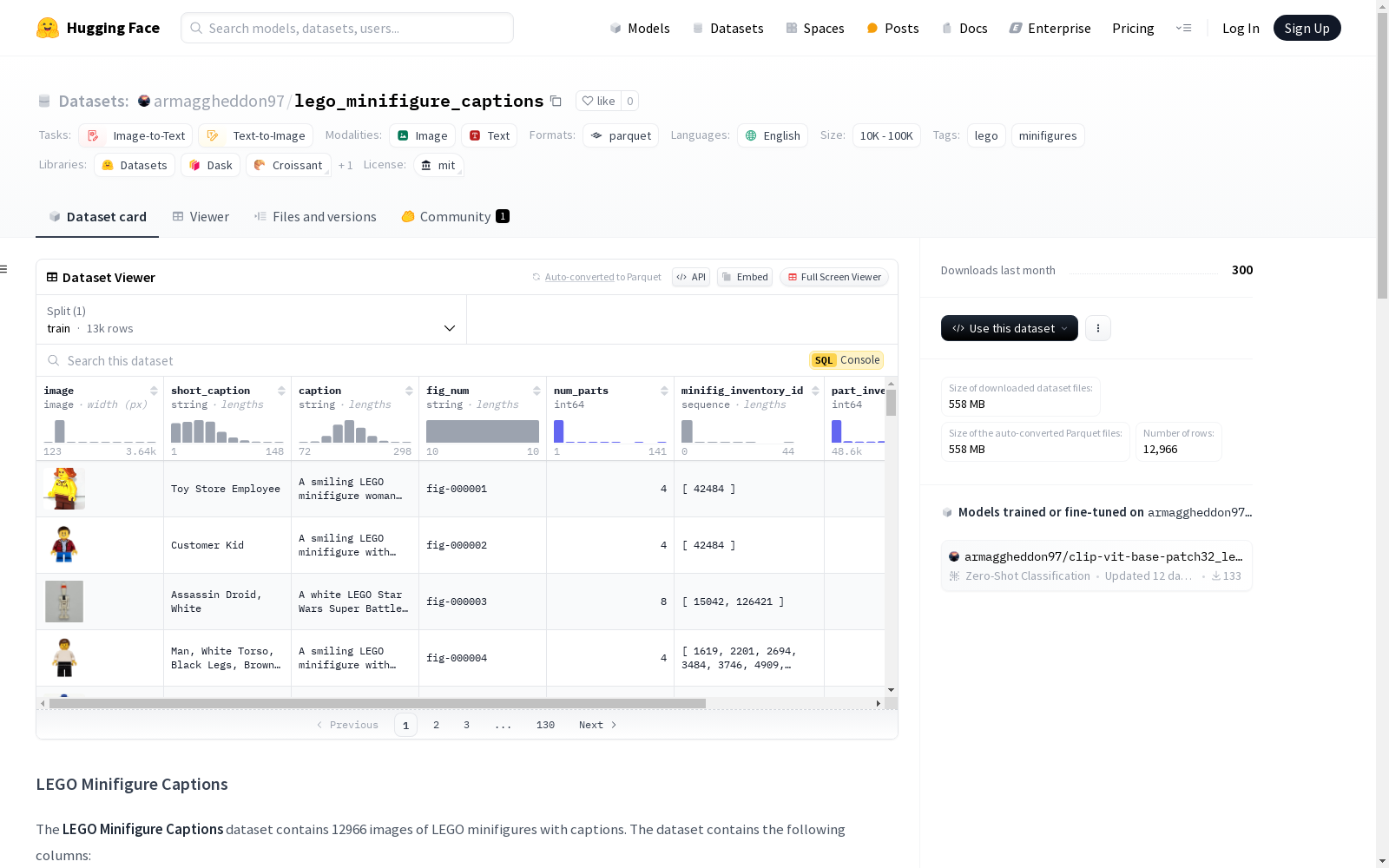
LEGO Minifigure Captions数据集包含12966张LEGO迷你人偶的图像及其描述。数据集包含以下列:'fig_num'表示迷你人偶的编号,'image'为JPEG格式的图像,'short_caption'为图像中迷你人偶的简短描述。数据来源于Rebrickable网站,图像从原始'minifigs.csv'文件的'img_url'列下载。未来计划添加使用Gemini-1.5-flash生成的'caption'列。该数据集适用于图像到文本和文本到图像的任务。
创建时间:
2024-11-28
原始信息汇总
LEGO Minifigure Captions 数据集概述
数据集信息
- 名称: Lego Minifigure Captions
- 许可证: MIT
- 语言: 英语 (en)
- 标签: lego, minifigures
- 大小类别: 10K<n<100K
- 任务类别: image-to-text, text-to-image
数据集内容
- 样本数量: 12966
- 特征:
fig_num: 字符串类型,表示minifigure的编号。image: 图像类型,包含minifigure的jpeg图像,格式为{"bytes": bytes, "path": str},可被huggingfacedatasets库解释为PIL.Image对象。short_caption: 字符串类型,描述图像中minifigure的简短描述。- 即将添加
caption: 使用Gemini-1.5-flash生成的minifigure描述。
数据来源
- 来源: Rebrickable网站
- 数据下载日期: 2024年11月27日
- 备注: 原始
minifigs.csv文件包含14985个minifigures,但由于某些图像不可用,仅下载了12966张图像。
使用方法
使用pandas
-
需要安装
pyarrow库。 -
示例代码: python from pathlib import Path import pandas as pd
PATH_TO_DATASET = Path("path_to_dataset")
加载数据集
df = pd.read_parquet(PATH_TO_DATASET / "minifigures-00000-of-00003.parquet") print(df.head())
使用huggingface/datasets
-
示例代码: python from datasets import load_dataset
以流模式加载数据集
ds = load_dataset("armaggheddon97/lego_minifigure_captions", split="minifigures", streaming=True)
打印数据集信息
print(next(iter(ds)))
-
备注:
image列已为PIL格式。
搜集汇总
数据集介绍
构建方式
LEGO Minifigure Captions数据集的构建过程主要依赖于Rebrickable网站提供的数据源。具体而言,数据集中的图像信息来源于Rebrickable的`minifigs.csv`文件中的`img_url`列,并通过自动化脚本进行下载。由于部分图像不可用,最终仅获取了12966张图像。每张图像均配有详细的文字描述,其中`caption`字段通过Gemini-1.5-flash模型生成,模型根据特定提示词对乐高小人仔的独特特征进行精确描述。此外,数据集还包含了乐高小人仔的编号、零件数量、库存ID等结构化信息,这些数据均直接从Rebrickable数据库中提取。
特点
LEGO Minifigure Captions数据集的核心特点在于其丰富的多模态数据组合。每一条数据均包含一张乐高小人仔的图像及其对应的文字描述,其中文字描述分为简短的`short_caption`和详细的`caption`,后者通过先进的自然语言生成模型生成,确保了描述的准确性和多样性。此外,数据集还提供了乐高小人仔的编号、零件数量、库存ID等结构化信息,为研究者提供了多维度的分析视角。数据集规模适中,包含12966条数据,适用于图像到文本、文本到图像等多种任务。
使用方法
LEGO Minifigure Captions数据集的使用方法灵活多样,支持通过pandas和Hugging Face的`datasets`库进行加载。使用pandas时,需安装`pyarrow`库以读取parquet格式的数据文件,并通过`pd.read_parquet`方法加载数据。使用Hugging Face的`datasets`库时,可通过`load_dataset`函数直接加载数据集,支持流式加载和常规加载两种模式。数据集的`image`字段在加载时已自动转换为PIL格式,便于直接进行图像处理。此外,数据集的分割方式为单一的训练集,适用于模型训练和评估任务。
背景与挑战
背景概述
LEGO Minifigure Captions数据集于2024年11月27日由Armaggheddon团队创建,主要基于Rebrickable网站提供的LEGO人仔数据。该数据集包含12966张LEGO人仔图像及其对应的描述性文本,旨在为图像到文本和文本到图像任务提供高质量的训练数据。数据集的核心研究问题在于如何通过详细的图像描述,捕捉LEGO人仔的独特特征,如服饰、配件、面部表情和主题。该数据集不仅为计算机视觉和自然语言处理领域的研究提供了新的资源,还为LEGO爱好者和收藏家提供了丰富的参考信息。
当前挑战
LEGO Minifigure Captions数据集在构建过程中面临多重挑战。首先,原始数据集中部分图像无法获取,导致数据集规模缩减至12966张,影响了数据的完整性和多样性。其次,生成高质量的图像描述需要精确捕捉LEGO人仔的细节特征,这对自然语言生成模型提出了较高要求。此外,数据集的构建依赖于Rebrickable网站的数据,其数据格式和更新频率可能对数据集的维护和扩展带来不确定性。最后,如何确保图像描述的一致性和准确性,避免生成过于泛化或模糊的文本,也是该数据集面临的重要挑战。
常用场景
经典使用场景
LEGO Minifigure Captions数据集在图像描述生成任务中展现了其独特的价值。通过提供12966张乐高迷你人仔图像及其对应的详细描述,该数据集为研究人员提供了一个丰富的资源,用于训练和评估图像到文本生成模型。特别是在多模态学习领域,该数据集能够帮助模型理解图像中的细节,并生成准确且富有描述性的文本。
衍生相关工作
基于LEGO Minifigure Captions数据集,许多经典研究工作得以展开。例如,研究人员开发了基于深度学习的图像描述生成模型,这些模型在生成文本时能够更好地捕捉图像中的细节。此外,该数据集还促进了多模态学习领域的研究,推动了图像和文本之间的跨模态理解技术的发展。
数据集最近研究
最新研究方向
在计算机视觉与自然语言处理交叉领域,LEGO Minifigure Captions数据集为图像描述生成任务提供了丰富的实验素材。近年来,研究者们利用该数据集探索了多模态学习模型在图像到文本转换中的表现,特别是在细粒度图像描述生成方面。结合Gemini-1.5-flash生成的详细描述,该数据集被广泛应用于评估生成模型的准确性与多样性。此外,随着生成式人工智能技术的快速发展,该数据集在文本到图像生成任务中也展现出重要价值,推动了LEGO模型设计与虚拟场景构建的智能化进程。
以上内容由遇见数据集搜集并总结生成


