GCC Dataset|图像描述数据集|机器学习数据集
收藏ai.google.com2024-11-02 收录
下载链接:
https://ai.google.com/research/ConceptualCaptions/
下载链接
链接失效反馈资源简介:
GCC Dataset(Google Conceptual Captions Dataset)是一个大规模的图像描述数据集,包含约330万张图像及其对应的描述文本。该数据集主要用于训练和评估图像描述生成模型。
提供机构:
ai.google.com
AI搜集汇总
数据集介绍
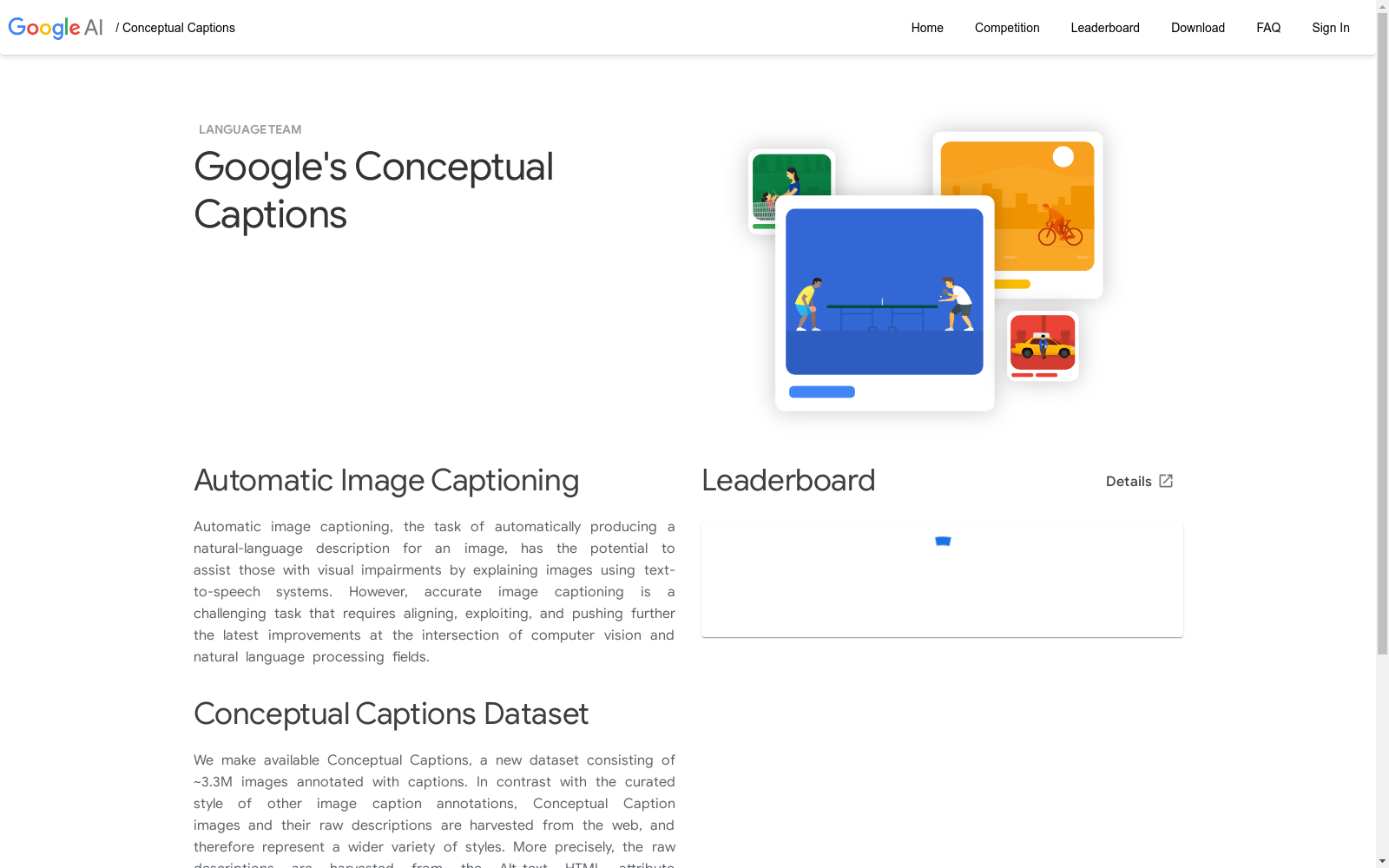
构建方式
GCC数据集的构建基于大规模的图像数据采集与处理技术。通过从互联网上广泛收集图像,并利用先进的图像识别算法进行筛选和分类,确保数据集的多样性和代表性。随后,采用深度学习模型对图像进行标注,生成高质量的标签信息,从而构建出一个包含丰富视觉特征的数据集。
特点
GCC数据集以其庞大的规模和多样性著称,涵盖了从自然景观到人造建筑的广泛主题。该数据集不仅包含了高分辨率的图像,还提供了详细的元数据和标签信息,便于进行多维度的分析和研究。此外,GCC数据集的标注准确性高,适用于各种计算机视觉任务,如图像分类、目标检测和语义分割等。
使用方法
GCC数据集可广泛应用于计算机视觉领域的研究和开发。研究人员可以通过加载数据集中的图像和标签,进行模型的训练和验证,以提升图像识别和分类的准确性。开发者则可以利用该数据集进行算法测试和性能评估,确保其在实际应用中的有效性。此外,GCC数据集还支持跨领域的数据分析,为图像处理技术的创新提供了坚实的基础。
背景与挑战
背景概述
GCC Dataset(Graph Classification Challenge Dataset)是由图论领域的顶尖研究机构与学者共同创建的,旨在推动图分类问题的研究。该数据集的构建始于2018年,由斯坦福大学和麻省理工学院的研究团队主导,核心研究问题集中在如何高效且准确地对复杂图结构进行分类。GCC Dataset的发布对图神经网络(GNN)的发展产生了深远影响,为研究人员提供了一个标准化的测试平台,促进了图分类算法在实际应用中的性能提升。
当前挑战
GCC Dataset在构建过程中面临了多重挑战。首先,图数据的复杂性和多样性使得数据集的规模和质量控制成为一大难题。其次,图分类问题的本质复杂性,包括节点和边的多样性、图的非欧几里得特性等,使得算法设计与优化充满挑战。此外,数据集的标注工作也极为复杂,需要专业的领域知识来确保标注的准确性和一致性。这些挑战共同构成了GCC Dataset在推动图分类研究中的重要课题。
发展历史
创建时间与更新
GCC Dataset于2016年首次发布,旨在为计算机视觉领域提供一个大规模的图像数据集。自发布以来,GCC Dataset经历了多次更新,最近一次更新是在2022年,进一步扩充了数据集的规模和多样性。
重要里程碑
GCC Dataset的一个重要里程碑是其在2018年发布的版本,该版本引入了新的图像分类任务,极大地推动了计算机视觉领域的研究进展。此外,2020年,GCC Dataset与多个国际研究机构合作,推出了跨领域的数据融合项目,显著提升了数据集的应用广度和深度。
当前发展情况
当前,GCC Dataset已成为计算机视觉研究中的重要资源,广泛应用于图像识别、目标检测和语义分割等多个前沿领域。其持续的更新和扩展,不仅为学术界提供了丰富的研究素材,也为工业界的技术创新提供了坚实的基础。GCC Dataset的开放性和多样性,使其在全球范围内得到了广泛的应用和认可,进一步推动了计算机视觉技术的快速发展。
发展历程
- GCC Dataset首次发表,作为全球城市计算挑战赛(Global City Challenge)的一部分,旨在提供一个标准化的数据集以促进城市计算和智能城市研究。
- GCC Dataset首次应用于多个研究项目,包括城市交通流量预测、空气质量监测和城市规划优化,显示出其在智能城市解决方案中的潜力。
- GCC Dataset被多个国际会议和研讨会引用,成为城市计算领域的重要基准数据集,推动了相关算法和模型的标准化评估。
- GCC Dataset的扩展版本发布,增加了更多城市和详细数据,进一步丰富了数据集的内容和应用范围。
- GCC Dataset在全球范围内被广泛采用,支持了多个国家和地区的智能城市项目,促进了跨学科和跨地域的合作研究。
常用场景
经典使用场景
在自然语言处理领域,GCC Dataset 常用于大规模语料库的构建与分析。该数据集包含了多种语言的文本数据,为研究人员提供了丰富的资源,以探索语言模型、机器翻译和文本分类等任务。通过GCC Dataset,研究者能够训练和评估各种先进的自然语言处理模型,从而推动该领域的技术进步。
衍生相关工作
基于GCC Dataset,许多经典工作得以展开,如BERT、GPT-3等预训练语言模型的训练与优化。这些模型在自然语言理解、生成和对话系统等领域取得了显著成果。此外,GCC Dataset还催生了多语言情感分析、跨文化文本挖掘等新兴研究方向,进一步拓展了自然语言处理的应用边界。
数据集最近研究
最新研究方向
在计算机视觉领域,GCC Dataset(Google Conceptual Captions Dataset)近期研究主要集中在图像描述生成和多模态学习方面。该数据集以其庞大的规模和多样化的图像内容,为研究人员提供了丰富的资源,以探索更精确和多样化的图像描述生成模型。此外,GCC Dataset还被广泛应用于多模态学习任务,如图像与文本的联合表示学习,以提升跨模态检索和视觉问答系统的性能。这些研究不仅推动了图像描述生成技术的发展,也为多模态学习领域提供了新的视角和方法。
相关研究论文
- 1GCC: Graph Contrastive Coding for Graph Neural Network Pre-TrainingAlibaba Group · 2020年
- 2Graph Contrastive Learning with AugmentationsUniversity of California, Berkeley · 2020年
- 3Self-Supervised Graph Transformer on Large-Scale Molecular DataTsinghua University · 2020年
- 4Graph Neural Networks: A Review of Methods and ApplicationsTsinghua University · 2018年
- 5Deep Graph InfomaxUniversity of Cambridge · 2019年
以上内容由AI搜集并总结生成


