有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
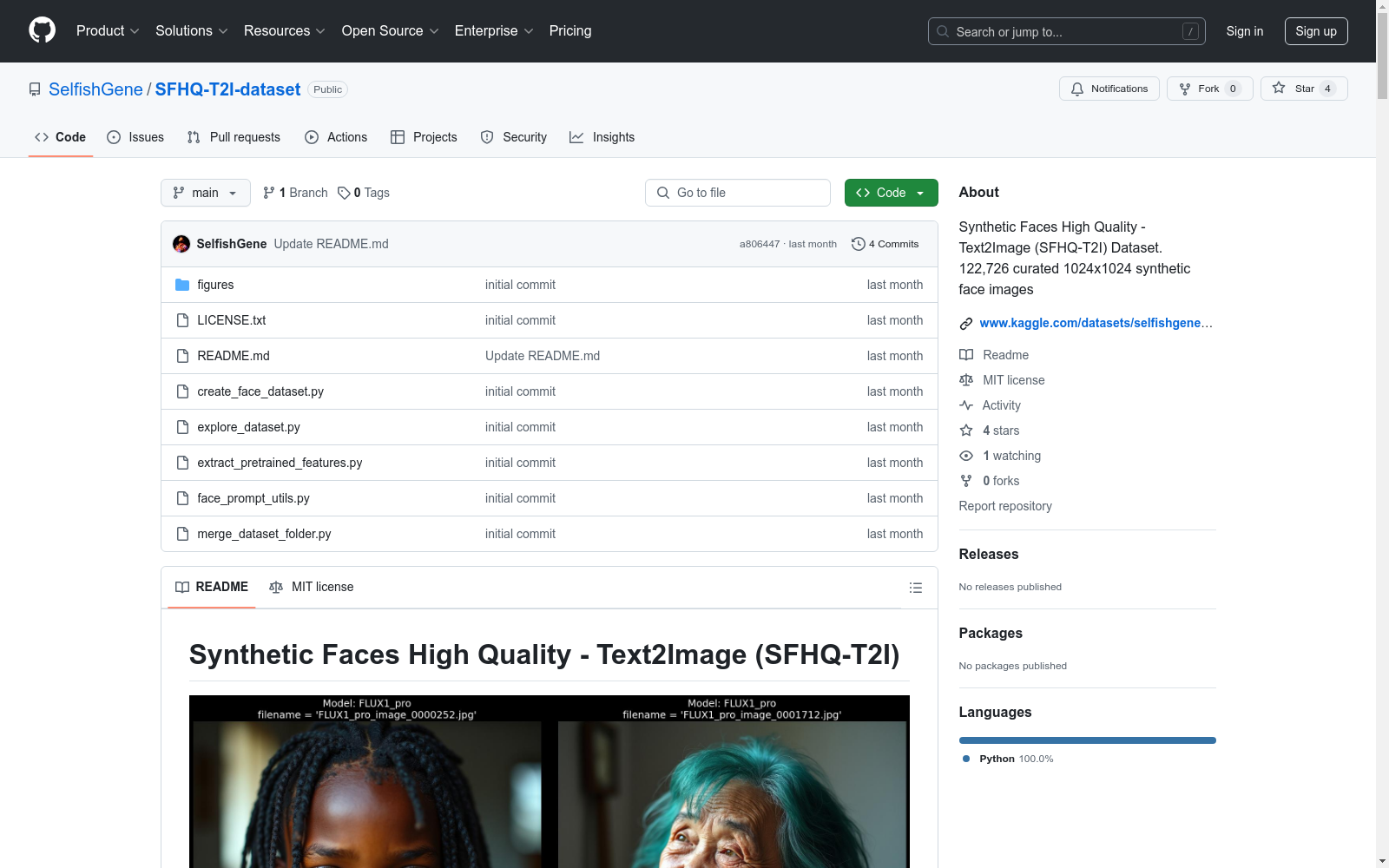
create_face_dataset.py: 生成数据集的脚本explore_dataset.py: 数据集基本探索性数据分析脚本extract_pretrained_features.py: 提取预训练OpenCLIP模型特征的工具face_prompt_utils.py: 自动生成多样化面部提示的工具merge_dataset_folder.py: 合并多个数据集文件夹的脚本figures/ 文件夹包含数据集的各种可视化explore_dataset.py 展示了如何加载数据集、可视化图像分布、绘制提示长度分布、使用CLIP特征进行文本搜索face_prompt_utils.py 生成高度多样化的提示引用格式:
@misc{david_beniaguev_2024_SFHQ_T2I, title={Synthetic Faces High Quality - Text 2 Image (SFHQ-T2I) Dataset}, author={David Beniaguev}, year={2024}, url={https://github.com/SelfishGene/SFHQ-T2I-dataset}, publisher={GitHub}, DOI={10.34740/kaggle/dsv/9548853}, }
中国区域教育数据库
该数据集包含了中国各区域的教育统计数据,涵盖了学校数量、学生人数、教师资源、教育经费等多个方面的信息。
www.moe.gov.cn 收录
中国气象数据
本数据集包含了中国2023年1月至11月的气象数据,包括日照时间、降雨量、温度、风速等关键数据。通过这些数据,可以深入了解气象现象对不同地区的影响,并通过可视化工具揭示中国的气温分布、降水情况、风速趋势等。
github 收录
Fruits-360
一个高质量的水果图像数据集,包含多种水果的图像,如苹果、香蕉、樱桃等,总计42345张图片,分为训练集和验证集,共有64个水果类别。
github 收录
Traditional-Chinese-Medicine-Dataset-SFT
该数据集是一个高质量的中医数据集,主要由非网络来源的内部数据构成,包含约1GB的中医各个领域临床案例、名家典籍、医学百科、名词解释等优质内容。数据集99%为简体中文内容,质量优异,信息密度可观。数据集适用于预训练或继续预训练用途,未来将继续发布针对SFT/IFT的多轮对话和问答数据集。数据集可以独立使用,但建议先使用配套的预训练数据集对模型进行继续预训练后,再使用该数据集进行进一步的指令微调。数据集还包含一定比例的中文常识、中文多轮对话数据以及古文/文言文<->现代文翻译数据,以避免灾难性遗忘并加强模型表现。
huggingface 收录
Breast Cancer Dataset
该项目专注于清理和转换一个乳腺癌数据集,该数据集最初由卢布尔雅那大学医学中心肿瘤研究所获得。目标是通过应用各种数据转换技术(如分类、编码和二值化)来创建一个可以由数据科学团队用于未来分析的精炼数据集。
github 收录