ROCStories
收藏arXiv2016-04-07 更新2024-06-21 收录
下载链接:
http://cs.rochester.edu/nlp/rocstories
下载链接
链接失效反馈官方服务:
资源简介:
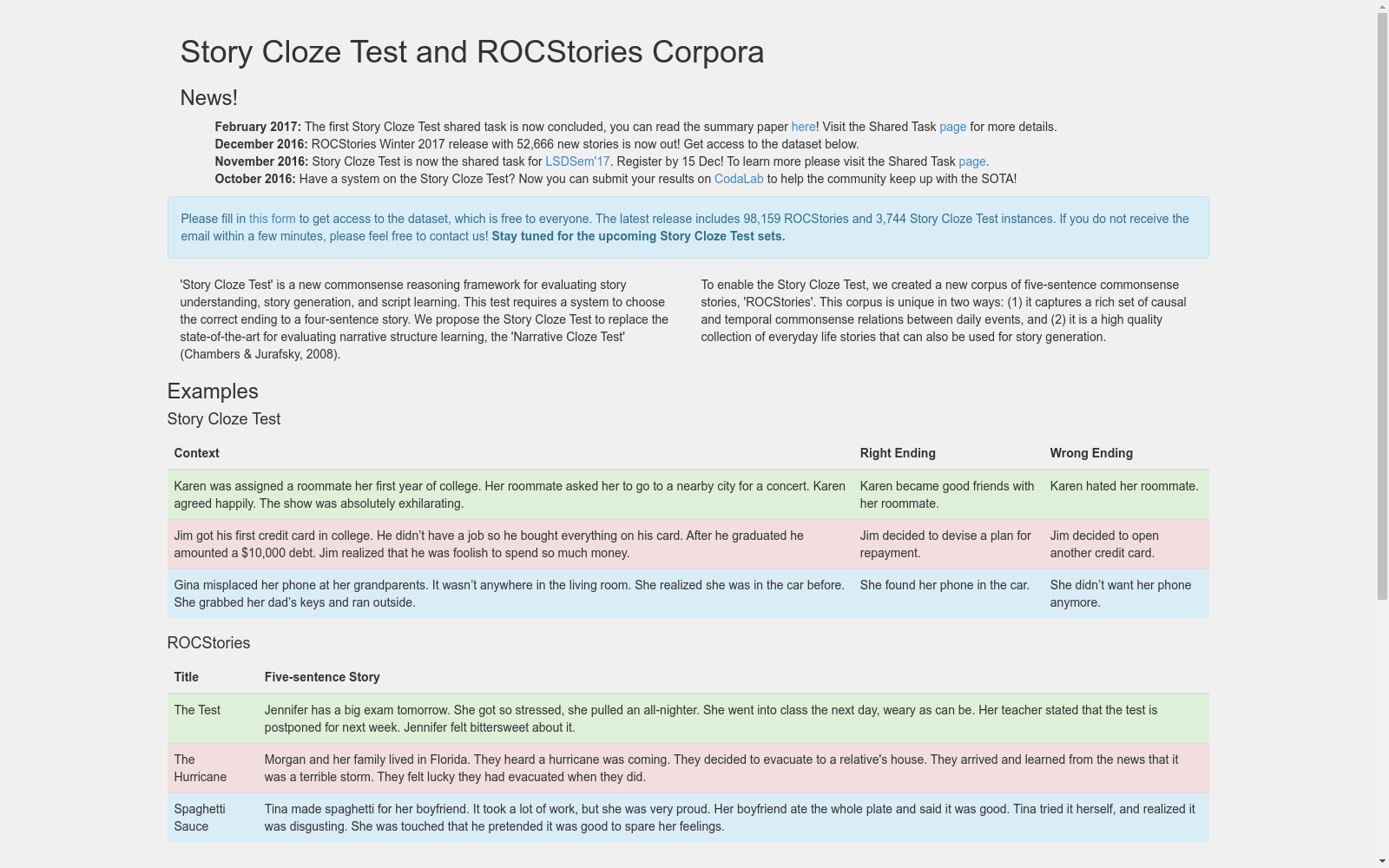
ROCStories是一个包含50,000个五句话的常识故事数据集,由罗切斯特大学创建。该数据集捕捉了日常事件间丰富的因果和时间常识关系,适用于故事生成模型的训练。数据集通过精心设计的提示和多阶段质量控制收集,旨在解决机器对日常事件常识知识的理解问题,并支持故事和脚本学习。
ROCStories is a commonsense story dataset consisting of 50,000 five-sentence stories, developed by the University of Rochester. This dataset captures rich causal and temporal commonsense relations between everyday events, and is applicable for training story generation models. The dataset was collected via carefully designed prompts and multi-stage quality control procedures, with the aim of addressing machine understanding of commonsense knowledge regarding daily events and supporting research on story and script learning.
提供机构:
罗切斯特大学
创建时间:
2016-04-07
搜集汇总
数据集介绍
构建方式
ROCStories数据集通过精心设计的众包方法构建,旨在收集高质量的五句日常故事。研究团队在Amazon Mechanical Turk平台上招募了大量工作者,通过多轮试点测试和质量控制,确保故事的连贯性和现实性。每个故事都要求包含明确的开始和结束,且每句话不超过70个字符,以避免冗余信息。最终,数据集包含了50,000个高质量的五句故事,这些故事充满了日常事件之间的因果和时间关系。
使用方法
ROCStories数据集可用于多种自然语言处理任务,包括故事理解和故事生成。研究者可以通过分析故事中的因果和时间关系,开发更深层次的语言理解模型。此外,数据集还可用于训练故事生成模型,以生成符合常识逻辑的连贯故事。为了评估模型的性能,研究者可以使用Story Cloze Test,该测试要求模型从两个可能的结尾中选择正确的结尾,从而评估其对故事深层理解的能力。
背景与挑战
背景概述
ROCStories数据集由罗切斯特大学、美国海军学院、微软研究院和弗吉尼亚理工学院的研究人员于2016年创建,旨在解决常识性故事理解中的核心问题。该数据集包含50,000个五句式常识性故事,强调日常事件之间的因果和时间关系,为故事理解和脚本学习提供了一个高质量的资源。ROCStories的独特之处在于其丰富的因果和时间关系,以及适用于故事生成的高质量日常故事集合。该数据集的创建填补了自然语言处理领域中缺乏系统评估框架的空白,推动了更深层次的语言理解研究。
当前挑战
ROCStories数据集面临的挑战主要集中在两个方面:一是如何从日常事件中提取和表示复杂的因果和时间关系,这需要先进的语义表示技术;二是构建过程中如何确保故事的高质量和一致性,特别是在通过众包平台收集数据时,如何有效过滤和验证故事的合理性。此外,该数据集的评估框架Story Cloze Test也提出了新的挑战,要求模型不仅能够识别事件序列,还需理解故事的整体语境和常识性逻辑,这对现有的浅层语言理解模型构成了重大挑战。
常用场景
经典使用场景
ROCStories数据集的经典使用场景在于评估和提升自然语言理解系统对常识故事的理解能力。通过提供大量五句式的日常故事,该数据集允许研究者设计和测试模型在故事完形填空任务中的表现,即从两个可能的结尾中选择最合适的结尾。这种任务不仅要求模型理解故事的上下文,还需要具备一定的常识推理能力,从而选择符合逻辑和情境的结尾。
解决学术问题
ROCStories数据集解决了自然语言处理领域中一个长期存在的问题,即如何有效地评估和提升系统对常识故事的理解能力。传统的评估方法往往依赖于浅层的语言理解技术,难以捕捉故事中的深层逻辑和因果关系。ROCStories通过引入Story Cloze Test,提供了一个更为系统和严格的评估框架,促使研究者开发能够进行深度语义理解和常识推理的模型,从而推动了自然语言理解技术的发展。
实际应用
ROCStories数据集在实际应用中具有广泛的前景,特别是在教育、娱乐和虚拟助手等领域。例如,在教育领域,该数据集可以用于开发智能辅导系统,帮助学生理解和分析故事结构,提升阅读理解能力。在娱乐产业,它可以用于生成更具吸引力和逻辑连贯的故事情节,增强用户体验。此外,虚拟助手和聊天机器人也可以利用该数据集进行训练,以更好地理解和回应用户的日常故事和情境。
数据集最近研究
最新研究方向
在自然语言处理领域,ROCStories数据集的最新研究方向主要集中在故事理解和脚本学习的深度模型开发上。随着对常识性知识和事件因果关系理解的深入,研究者们致力于构建能够捕捉复杂叙事结构的模型。这些模型不仅需要理解事件的表面信息,还需掌握其背后的逻辑和时间顺序。此外,研究还关注于如何通过大规模数据集的训练,提升模型在故事生成和理解任务中的表现,从而推动自然语言处理技术在更广泛应用场景中的落地。
相关研究论文
- 1A Corpus and Evaluation Framework for Deeper Understanding of Commonsense Stories罗切斯特大学 · 2016年
以上内容由遇见数据集搜集并总结生成


