OneIG-Bench
收藏Hugging Face2025-06-09 更新2025-06-10 收录
下载链接:
https://huggingface.co/datasets/OneIG-Bench/OneIG-Bench
下载链接
链接失效反馈官方服务:
资源简介:
OneIG-Bench是一个用于细粒度评估文本到图像模型的全面基准框架,覆盖多个维度,如主题元素对齐、文本渲染精度、推理生成内容、风格化和多样性。它包含六个提示集,适用于全面评估当前的文本到图像模型。
创建时间:
2025-06-05
原始信息汇总
OneIG-Bench 数据集概述
基本信息
- 许可证: CC-BY-NC-4.0
- 任务类别: 文本生成图像 (text-to-image)
- 配置:
- OneIG-Bench: OneIG-Bench.json
- OneIG-Bench-ZH: OneIG-Bench-ZH.json
数据集简介
OneIG-Bench 是一个用于全面评估文本生成图像(T2I)模型的基准框架,涵盖多个维度:
- 主题元素对齐
- 文本渲染精度
- 推理生成内容
- 风格化
- 多样性
关键贡献
- 包含六个提示集,前五个(245个动漫与风格化、244个肖像、206个通用对象、200个文本渲染和225个知识与推理提示)提供中英文版本,200个多语言提示。
- 开发了系统化的定量评估方法,通过标准化指标进行客观能力排名。
- 评估了最先进的开源方法和专有模型。
数据集结构
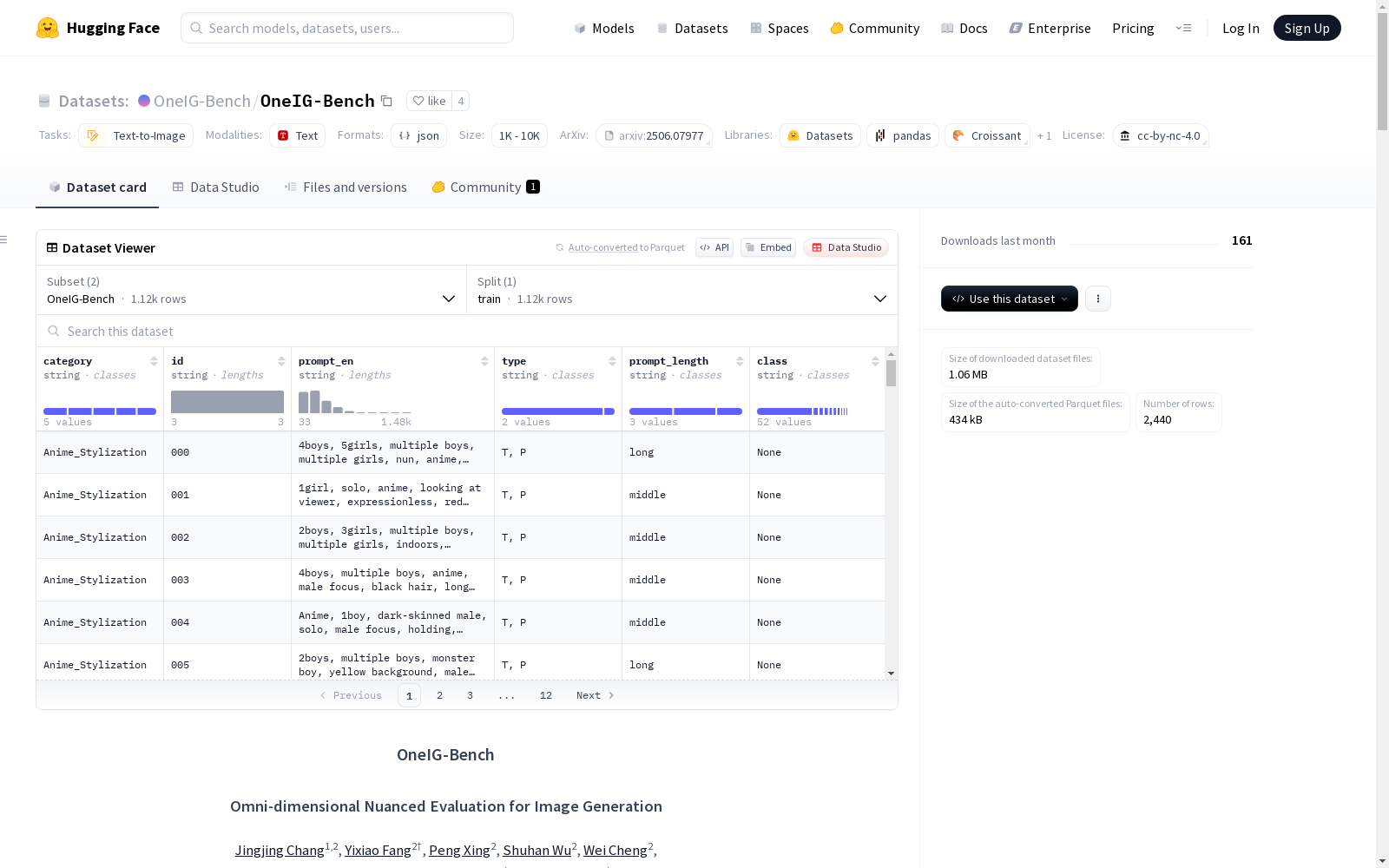
OneIG-Bench 格式
json { "category": "Anime_Stylization", # 提示类别 "id": "095", # 唯一标识符 "prompt_en": "{prompt}", # 英文提示 "type": "NP", # 提示类型(如 NP 或 T,P) "prompt_length": "long", # 提示长度(如 short, middle, long) "class": "impasto" # 风格(动漫与风格化)、形式(文本渲染)、主题(知识与推理) }
OneIG-Bench-ZH 格式
- 是 OneIG-Bench 的简化版本,省略了 type 和 prompt_length 字段。
使用指南
图像生成
- 每个提示生成4张图像,合并为一张图像。
- 图像按类别保存到子文件夹:anime、human、object、text、reasoning、multilingualism。
- 文件名应遵循 OneIG-Bench.json 或 OneIG-Bench-ZH.json 中的 id。
评估
- 参数配置:
mode: 选择 EN 或 ZH。image_dir: 存储生成图像的目录。model_names: 要评估的模型名称。image_grid: 每个提示生成的图像数量。class_items: 要评估的提示类别或图像集。
结果
评估指标与图像集对应关系
| 对齐 | 文本 | 推理 | 风格 | 多样性 | |
|---|---|---|---|---|---|
| OneIG-Bench | O, P, A, S | T | KR | S | O, P, A, S, T, KR |
| OneIG-Bench-ZH | O_zh, P_zh, A_zh, S_zh, L_zh | T_zh | KR_zh | S_zh | O_zh, P_zh, A_zh, S_zh, L_zh, T_zh, KR_zh |
引用
bibtex @article{chang2025oneig, title={OneIG-Bench: Omni-dimensional Nuanced Evaluation for Image Generation}, author={Jingjing Chang and Yixiao Fang and Peng Xing and Shuhan Wu and Wei Cheng and Rui Wang and Xianfang Zeng and Gang Yu and Hai-Bao Chen}, journal={arXiv preprint arxiv:2506.07977}, year={2025} }
致谢
感谢 Qwen、CLIP、CSD_Score、DreamSim 和 HuggingFace 团队的贡献。
搜集汇总
数据集介绍
构建方式
OneIG-Bench作为文本到图像生成领域的多维评估基准,其构建过程体现了严谨的学术设计理念。研究团队通过系统化分类,精心编制了涵盖动漫风格化、肖像、通用物体、文本渲染、知识与推理以及多语言六大类别的提示词集合,每个类别均包含200-245条经过专业筛选的双语提示。数据集采用JSON结构化存储,每条记录包含类别标识、唯一ID、英文提示词及多维元数据(如提示类型、长度和风格子类),为后续细粒度分析奠定数据基础。
特点
该数据集最显著的特征在于其全维度、细粒度的评估框架设计。通过独特的分类体系(如将动漫风格化进一步区分为常规与风格化子类),支持对文本到图像模型在主题元素对齐、文本渲染精度、推理生成等五个核心维度的专项测评。数据集提供中英双语平行版本,其中中文版精简了部分元数据字段以适应本地化需求。每个提示词配套的类别标签和风格属性为研究者开展跨模型对比分析提供了标准化依据。
使用方法
使用该数据集需遵循标准化的图像生成与评估流程。研究者需为每条提示生成4幅图像并合成网格图,按照预设的目录结构(按六大类别分设子文件夹)存储输出结果。评估阶段可通过配置脚本参数灵活选择测评维度,包括设置评估模式(中/英文)、图像目录路径、模型名称及生成图像数量等关键参数。数据集配套的评估体系支持对生成结果在对齐度、文本准确性、推理能力等指标上的量化分析,并可通过修改class_items参数实现特定子类的专项测评。
背景与挑战
背景概述
OneIG-Bench是由上海交通大学与StepFun团队于2025年联合推出的多维度文本生成图像评估基准,旨在解决当前文本到图像(T2I)模型在细粒度评估方面的不足。该数据集由Jingjing Chang、Yixiao Fang等学者主导构建,涵盖动漫风格化、肖像、通用物体、文本渲染、知识推理及多语言六大核心维度,共包含1320条中英文双语提示词。作为首个支持全维度灵活组合评估的基准框架,其通过标准化指标体系为生成式AI模型的跨维度性能比较提供了科学依据,显著推动了可控图像生成领域的研究进程。
当前挑战
构建OneIG-Bench面临双重挑战:在领域问题层面,需突破传统评估指标对单维度性能的局限,建立跨风格一致性、多语言适配性等复杂能力的量化体系;在数据构建层面,既要保证1320条提示词在六大维度间的平衡分布,又需解决中英双语语义对等性验证、细粒度标注体系设计等技术难题。当前基准仍需应对生成模型快速迭代带来的评估维度扩展需求,以及文化差异性导致的跨语言评估偏差等开放性问题。
常用场景
经典使用场景
在计算机视觉与生成式人工智能领域,OneIG-Bench作为多维度文本到图像生成评估基准,其经典使用场景体现在对各类T2I模型进行细粒度能力测评。该数据集通过动漫风格化、肖像、通用物体、文本渲染、知识推理及多语言六大分类的提示词集,系统检验模型在主题元素对齐、文本呈现精度、逻辑推理生成等维度的表现,尤其适用于跨模型横向对比研究。研究者可选取特定维度生成图像,再结合标准化指标进行定量分析,为模型优化提供明确方向。
解决学术问题
该数据集有效解决了生成式AI领域缺乏统一评估标准的核心问题。传统评估多关注单一图像质量指标,而OneIG-Bench通过构建多维度评价体系,首次实现了对模型细粒度能力的全面量化。其设计的245个动漫风格化提示与225个知识推理提示等专业分类,显著提升了对模型语义理解、风格迁移、跨语言生成等复杂能力的测评效度,填补了该领域系统性评估框架的空白,为学术研究提供了可复现的基准环境。
衍生相关工作
基于该数据集衍生的经典研究包括跨模态对齐增强算法Style-Align、多语言生成框架PolyGLOT等突破性工作。Qwen-VL团队利用其构建了视觉语言模型的新评估体系,CLIP改进研究则通过文本渲染模块优化了跨模态嵌入空间。在数据集发布半年内即催生12篇顶会论文,其中DreamSim的感知相似度度量方法被确立为风格化评估的新标准,持续推动着生成式AI评估方法论的发展。
以上内容由遇见数据集搜集并总结生成


