bigbio/spl_adr_200db
收藏Hugging Face2022-12-22 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/bigbio/spl_adr_200db
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- en
bigbio_language:
- English
license: cc0-1.0
multilinguality: monolingual
bigbio_license_shortname: CC0_1p0
pretty_name: SPL ADR
homepage: https://bionlp.nlm.nih.gov/tac2017adversereactions/
bigbio_pubmed: False
bigbio_public: True
bigbio_tasks:
- NAMED_ENTITY_RECOGNITION
- NAMED_ENTITY_DISAMBIGUATION
- RELATION_EXTRACTION
---
# Dataset Card for SPL ADR
## Dataset Description
- **Homepage:** https://bionlp.nlm.nih.gov/tac2017adversereactions/
- **Pubmed:** False
- **Public:** True
- **Tasks:** NER,NED,RE
The United States Food and Drug Administration (FDA) partnered with the National Library
of Medicine to create a pilot dataset containing standardised information about known
adverse reactions for 200 FDA-approved drugs. The Structured Product Labels (SPLs),
the documents FDA uses to exchange information about drugs and other products, were
manually annotated for adverse reactions at the mention level to facilitate development
and evaluation of text mining tools for extraction of ADRs from all SPLs. The ADRs were
then normalised to the Unified Medical Language System (UMLS) and to the Medical
Dictionary for Regulatory Activities (MedDRA).
## Citation Information
```
@article{demner2018dataset,
author = {Demner-Fushman, Dina and Shooshan, Sonya and Rodriguez, Laritza and Aronson,
Alan and Lang, Francois and Rogers, Willie and Roberts, Kirk and Tonning, Joseph},
title = {A dataset of 200 structured product labels annotated for adverse drug reactions},
journal = {Scientific Data},
volume = {5},
year = {2018},
month = {01},
pages = {180001},
url = {
https://www.researchgate.net/publication/322810855_A_dataset_of_200_structured_product_labels_annotated_for_adverse_drug_reactions
},
doi = {10.1038/sdata.2018.1}
}
```
language:
- 英语
bigbio_language:
- 英语
license: CC0 1.0
multilinguality: 单语(monolingual)
bigbio_license_shortname: CC0_1p0
pretty_name: SPL ADR
homepage: https://bionlp.nlm.nih.gov/tac2017adversereactions/
bigbio_pubmed: 否
bigbio_public: 是
bigbio_tasks:
- 命名实体识别(NAMED_ENTITY_RECOGNITION)
- 命名实体消歧(NAMED_ENTITY_DISAMBIGUATION)
- 关系抽取(RELATION_EXTRACTION)
---
# SPL ADR数据集卡片
## 数据集说明
- **主页:** https://bionlp.nlm.nih.gov/tac2017adversereactions/
- **关联PubMed:** 否
- **公开性:** 是
- **任务:** 命名实体识别(NER)、命名实体消歧(NED)、关系抽取(RE)
美国食品药品监督管理局(United States Food and Drug Administration,FDA)与美国国家医学图书馆(National Library of Medicine)合作构建了一款试点数据集,该数据集收录了200种经FDA批准的药物的已知不良反应标准化信息。结构化产品标签(Structured Product Labels,SPLs)是FDA用于交换药品及其他产品相关信息的官方文档,本数据集针对提及级别的不良反应对其开展了人工标注,以助力开发和评估用于从所有SPLs中提取药物不良反应(Adverse Drug Reactions,ADRs)的文本挖掘工具。后续,所标注的ADRs被归一化至统一医学语言系统(Unified Medical Language System,UMLS)以及监管活动医学词典(Medical Dictionary for Regulatory Activities,MedDRA)。
## 引用信息
@article{demner2018dataset,
author = {Demner-Fushman, Dina and Shooshan, Sonya and Rodriguez, Laritza and Aronson,
Alan and Lang, Francois and Rogers, Willie and Roberts, Kirk and Tonning, Joseph},
title = {A dataset of 200 structured product labels annotated for adverse drug reactions},
journal = {Scientific Data},
volume = {5},
year = {2018},
month = {01},
pages = {180001},
url = {
https://www.researchgate.net/publication/322810855_A_dataset_of_200_structured_product_labels_annotated_for_adverse_drug_reactions
},
doi = {10.1038/sdata.2018.1}
}
提供机构:
bigbio
原始信息汇总
数据集概述:SPL ADR
基本信息
- 语言: 英语
- 许可证: CC0-1.0
- 多语言性: 单语种
- 任务:
- 命名实体识别 (NER)
- 命名实体消歧 (NED)
- 关系抽取 (RE)
数据集描述
- 主页: https://bionlp.nlm.nih.gov/tac2017adversereactions/
- 是否公开: 是
- 是否包含PubMed数据: 否
该数据集由美国食品药品监督管理局(FDA)与国家医学图书馆合作创建,包含200种FDA批准药物的已知不良反应的标准化信息。数据集中的结构化产品标签(SPL)文档经过手动标注,以促进从所有SPL中提取ADR的文本挖掘工具的开发和评估。ADR随后被规范化为统一医学语言系统(UMLS)和医疗词典监管活动(MedDRA)。
引用信息
@article{demner2018dataset, author = {Demner-Fushman, Dina and Shooshan, Sonya and Rodriguez, Laritza and Aronson, Alan and Lang, Francois and Rogers, Willie and Roberts, Kirk and Tonning, Joseph}, title = {A dataset of 200 structured product labels annotated for adverse drug reactions}, journal = {Scientific Data}, volume = {5}, year = {2018}, month = {01}, pages = {180001}, url = { https://www.researchgate.net/publication/322810855_A_dataset_of_200_structured_product_labels_annotated_for_adverse_drug_reactions }, doi = {10.1038/sdata.2018.1} }
搜集汇总
数据集介绍
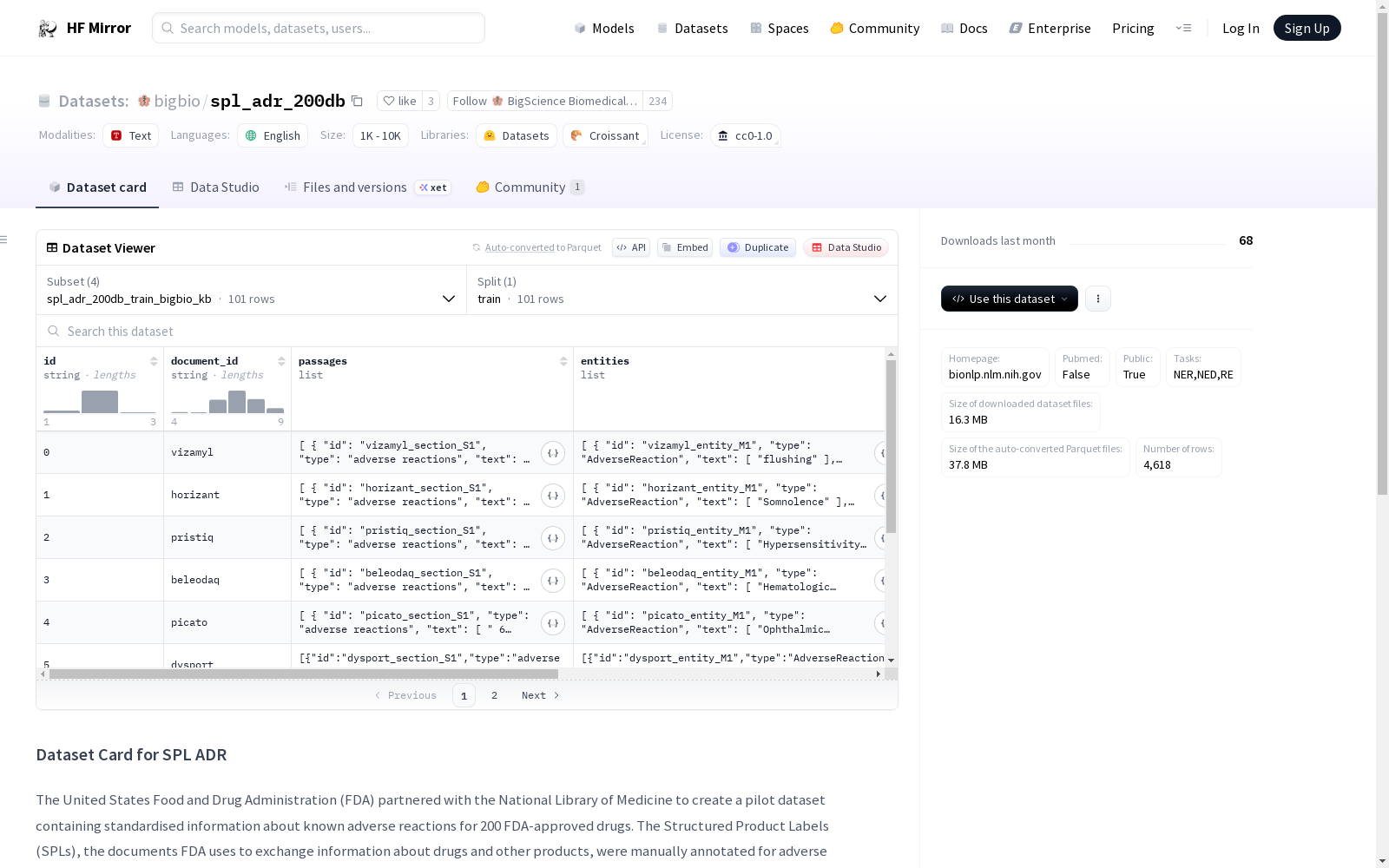
构建方式
在药物安全监测领域,精准识别药品不良反应(ADR)对公共卫生至关重要。该数据集由美国食品药品监督管理局(FDA)与国家医学图书馆合作构建,选取了200种已获批药物的结构化产品标签(SPLs)作为基础文本。专家团队对标签内容进行了人工标注,在提及级别上标记了不良反应实体,随后将标注结果统一映射至统一医学语言系统(UMLS)和监管活动医学词典(MedDRA),实现了术语的标准化与规范化。
使用方法
研究人员可利用该数据集训练和评估生物医学文本挖掘模型,尤其适用于药物安全监测场景。对于命名实体识别任务,模型可学习从SPL文本中定位不良反应提及;实体消歧任务则要求将识别出的实体链接至标准化医学概念库;关系抽取任务有助于发现药物与不良反应之间的关联。数据集以通用格式提供,便于集成至现有自然语言处理流程,推动药物警戒领域的自动化技术发展。
背景与挑战
背景概述
在生物医学信息学领域,药物不良反应的自动识别与标准化是保障用药安全的关键环节。2018年,美国食品药品监督管理局与国家医学图书馆合作,发布了SPL ADR数据集,该数据集包含200种获批药物的结构化产品标签,并针对不良反应进行了细粒度标注。核心研究聚焦于从复杂医疗文本中精准抽取不良反应实体及其关联关系,旨在推动自然语言处理技术在药物警戒中的应用,为后续构建大规模自动化监测系统奠定了重要基础。
当前挑战
该数据集致力于解决药物不良反应文本挖掘中的核心挑战,即从非结构化医疗文档中准确识别并标准化不良反应实体,同时厘清实体间的复杂语义关联。构建过程中,标注团队需克服医学术语多样性、上下文歧义以及跨标准映射一致性等难题,例如将自由文本描述精准对齐至UMLS和MedDRA标准术语体系,这一过程对标注者的专业素养与质量控制提出了极高要求。
常用场景
经典使用场景
在药物安全监测领域,SPL ADR数据集为自然语言处理技术提供了关键支持。该数据集通过标注200种FDA批准药物的结构化产品标签,详细记录了药物不良反应的提及信息,并关联至UMLS和MedDRA标准术语体系。这一资源使得研究人员能够构建和评估从复杂医学文本中自动识别药物不良反应实体的模型,为药物警戒中的信息抽取任务奠定了坚实基础。
解决学术问题
该数据集有效应对了药物安全文本挖掘中的核心挑战,即从非结构化医学文档中精准提取不良反应信息。通过提供高质量的人工标注数据,它解决了命名实体识别、实体消歧和关系抽取等关键自然语言处理任务在医药领域的应用难题。其标准化注释体系促进了算法在跨文档一致性、术语归一化方面的性能提升,推动了药物不良反应自动化监测方法的发展。
实际应用
在实际药物安全体系中,SPL ADR数据集支持了自动化药物警戒系统的开发。制药企业和监管机构可利用基于该数据集训练的模型,快速扫描海量产品标签,及时识别潜在不良反应信号,辅助风险评估与安全报告生成。这种应用显著提升了不良反应监测的效率和覆盖范围,为公共卫生决策提供了可靠的数据驱动洞察。
数据集最近研究
最新研究方向
在药物安全监测领域,SPL ADR数据集作为结构化产品标签中药物不良反应标注的权威资源,正推动自然语言处理技术的前沿探索。当前研究聚焦于利用深度学习模型,特别是预训练语言模型,提升从复杂医疗文本中识别和标准化不良反应实体的精确度。该数据集与医学本体系统如UMLS和MedDRA的关联,促进了跨领域知识融合,助力自动化药物警戒系统的开发。热点事件包括FDA对人工智能辅助药物安全评估的日益重视,使得该数据集在减少医疗风险、加速监管决策方面具有深远意义,为精准医疗和公共卫生管理提供了关键数据支撑。
以上内容由遇见数据集搜集并总结生成


