COCO-Text
收藏arXiv2016-06-20 更新2024-06-21 收录
下载链接:
http://vision.cornell.edu/se3/coco-text
下载链接
链接失效反馈官方服务:
资源简介:
COCO-Text数据集是由捷克技术大学等机构创建,旨在推动自然图像中文本检测与识别技术的发展。该数据集基于MS COCO数据集,包含超过63,686张图像和173,589个文本标注,涵盖了从机器打印到手写的多种文本类型。创建过程中,研究者利用了先进的OCR技术和众包平台进行文本的标注和分类。COCO-Text的应用领域广泛,包括辅助技术、机器人导航和地理定位等,旨在解决复杂场景下的文本识别问题。
COCO-Text dataset was created by institutions including the Czech Technical University, aiming to advance the development of text detection and recognition technologies in natural images. Built upon the MS COCO dataset, it contains over 63,686 images and 173,589 text annotations, covering various text types ranging from machine-printed to handwritten text. During its creation, researchers utilized advanced OCR technologies and crowdsourcing platforms for text annotation and classification. COCO-Text has a wide range of application scenarios, including assistive technology, robotic navigation, geolocation and others, with the goal of addressing text recognition challenges in complex real-world scenes.
提供机构:
捷克技术大学
创建时间:
2016-01-27
搜集汇总
数据集介绍
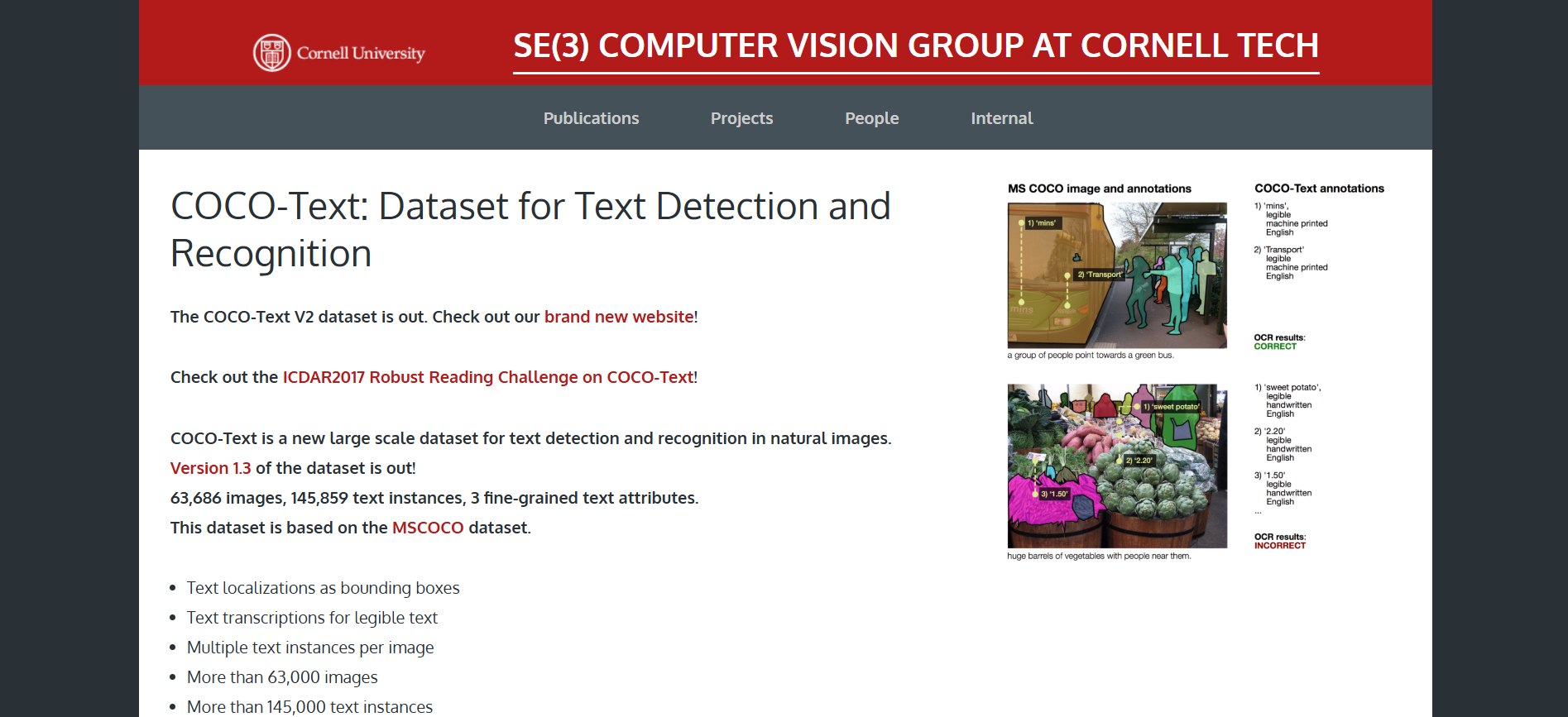
构建方式
COCO-Text数据集的构建基于广泛的自然场景图像,通过人工标注和自动识别相结合的方式,对图像中的文本进行精细化的标注。该数据集涵盖了多种语言和字体,确保了文本识别任务的多样性和挑战性。构建过程中,首先对图像进行预处理,去除噪声和无关信息,随后采用多层次的标注策略,确保文本区域的准确性和完整性。
特点
COCO-Text数据集以其丰富的文本多样性和高质量的标注著称。该数据集包含了超过60万张图像,其中标注了超过17万条文本实例。这些文本实例涵盖了从简单到复杂的各种场景,包括广告牌、书籍封面、手写笔记等。此外,数据集还提供了详细的文本属性信息,如文本方向、字体类型和语言类别,为文本识别和理解研究提供了全面的支持。
使用方法
COCO-Text数据集广泛应用于计算机视觉和自然语言处理领域,尤其适用于文本检测、识别和理解任务。研究人员可以通过该数据集训练和评估文本识别模型,提升模型在复杂场景下的性能。使用时,用户可以根据需求选择不同类型的图像和文本实例进行训练和测试,同时利用数据集提供的标注信息进行模型的精细调优。此外,COCO-Text还支持多种编程语言和深度学习框架,方便研究人员进行跨平台开发和应用。
背景与挑战
背景概述
COCO-Text数据集,由Boris Babenko和Ming-Ming Cheng于2016年创建,是计算机视觉领域中一个重要的文本检测与识别资源。该数据集基于COCO(Common Objects in Context)数据集构建,包含超过63,000张图像和超过173,000个文本实例,涵盖了多种语言和字体风格。COCO-Text的推出,极大地推动了文本检测与识别技术的发展,为研究人员提供了一个标准化的基准,以评估和比较不同算法的性能。其丰富的标注信息和多样化的场景,使得该数据集在自然场景文本识别、光学字符识别(OCR)以及多语言文本处理等领域具有广泛的应用前景。
当前挑战
尽管COCO-Text数据集在文本检测与识别领域具有重要地位,但其构建和应用过程中仍面临诸多挑战。首先,数据集中的文本实例多样性极高,包括不同字体、大小、颜色和背景复杂度,这增加了算法在实际应用中的泛化难度。其次,自然场景中的文本常常受到遮挡、模糊和光照不均等因素的影响,导致文本检测和识别的准确性下降。此外,数据集的标注过程复杂且耗时,如何提高标注效率和准确性也是一个亟待解决的问题。最后,随着多语言文本处理需求的增加,如何扩展数据集以涵盖更多语言和书写系统,也是一个重要的研究方向。
发展历史
创建时间与更新
COCO-Text数据集于2016年首次发布,旨在为文本检测和识别任务提供一个标准化的基准。该数据集的最新版本于2019年更新,引入了更多的标注和改进的注释质量。
重要里程碑
COCO-Text的发布标志着文本检测和识别领域的一个重要里程碑。它不仅提供了大规模的图像和文本标注,还引入了多种语言和复杂场景的文本实例,极大地推动了相关算法的发展。此外,COCO-Text还促进了多任务学习方法的研究,使得模型能够在同一数据集上同时进行文本检测和识别任务。
当前发展情况
当前,COCO-Text数据集已成为文本检测和识别领域的重要基准之一,广泛应用于学术研究和工业应用中。其丰富的标注和多样化的场景使得研究人员能够开发出更加鲁棒和高效的算法。此外,COCO-Text的持续更新和扩展也确保了其在不断变化的计算机视觉领域中的相关性和实用性。通过提供高质量的数据集,COCO-Text为推动文本处理技术的发展做出了重要贡献。
发展历程
- COCO-Text数据集首次发表,由Boris Epshtein等人提出,旨在为文本检测和识别任务提供一个大规模、多样化的数据集。
- COCO-Text数据集首次应用于文本检测和识别领域的研究,成为该领域的重要基准数据集之一。
- COCO-Text数据集的第二版发布,增加了更多的标注信息和数据样本,进一步提升了其在文本识别任务中的应用价值。
- COCO-Text数据集被广泛应用于多个国际会议和竞赛中,如CVPR和ICDAR,推动了文本检测和识别技术的发展。
- COCO-Text数据集的第三版发布,引入了更多的语言种类和场景多样性,增强了其在多语言和复杂场景下的适用性。
常用场景
经典使用场景
在计算机视觉领域,COCO-Text数据集以其丰富的文本标注信息,成为自然场景文本检测与识别任务的经典基准。该数据集包含了超过63,000张图像,涵盖了多种语言和字体风格的文本实例,为研究人员提供了一个全面且多样化的测试平台。通过利用COCO-Text,研究者们能够开发和评估各种先进的文本检测与识别算法,从而推动这一领域的技术进步。
解决学术问题
COCO-Text数据集在解决自然场景文本识别的学术研究问题上发挥了重要作用。它不仅提供了大规模的标注数据,还涵盖了多种复杂场景,如低分辨率、遮挡和多语言文本,这使得研究者能够针对实际应用中的挑战进行深入研究。通过该数据集,学术界得以验证和改进现有的文本识别模型,推动了相关算法在准确性和鲁棒性方面的显著提升。
衍生相关工作
基于COCO-Text数据集,许多相关的经典工作得以展开。例如,研究者们开发了多种先进的文本检测与识别算法,如基于深度学习的文本检测网络和多任务学习框架,这些算法在COCO-Text上的表现显著优于传统方法。此外,COCO-Text还激发了关于多语言文本识别和复杂场景下文本检测的研究,推动了整个计算机视觉领域在这一方向上的深入探索。
以上内容由遇见数据集搜集并总结生成


