PhoMT
收藏arXiv2021-10-23 更新2024-06-21 收录
下载链接:
https://github.com/VinAIResearch/PhoMT
下载链接
链接失效反馈官方服务:
资源简介:
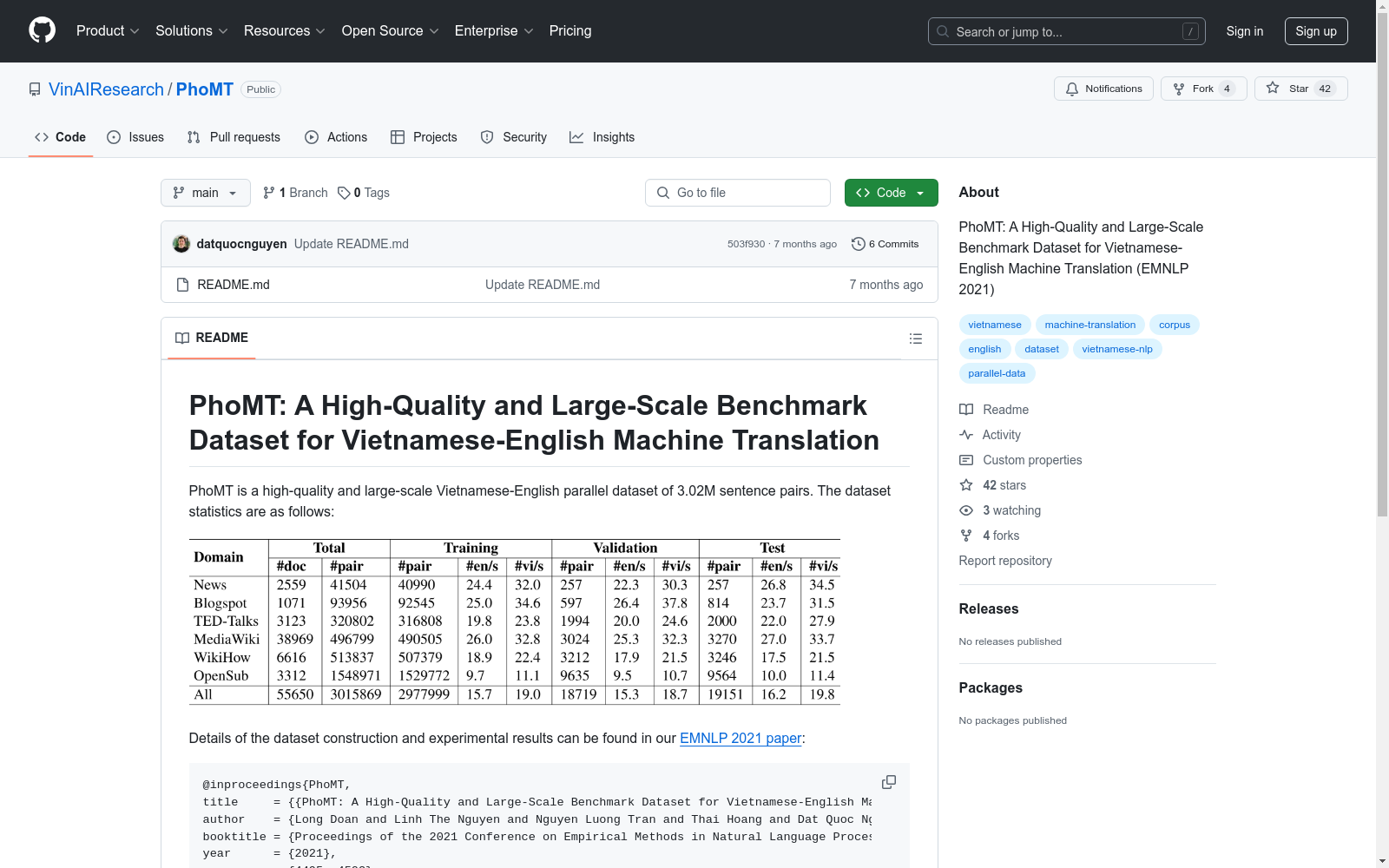
PhoMT是一个大规模高质量的越南语-英语平行语料库,包含302万个句子对,旨在解决越南语-英语机器翻译资源不足的问题。数据集由VinAI研究创建,内容涵盖多个领域,如WikiHow、TED-Talks等,确保了数据多样性和广泛性。创建过程中,通过多阶段处理确保数据质量,包括文档收集、预处理、句子对齐和后处理。PhoMT的应用领域主要集中在机器翻译,特别是越南语到英语的翻译,旨在提高翻译质量和效率,为相关研究提供坚实基础。
PhoMT is a large-scale, high-quality Vietnamese-English parallel corpus consisting of 3.02 million sentence pairs, which is designed to address the shortage of resources for Vietnamese-English machine translation. It was developed by VinAI Research. Its content spans multiple domains including WikiHow, TED-Talks and others, ensuring the diversity and broad coverage of the dataset. During the construction process, multi-stage processing procedures were adopted to guarantee data quality, which include document collection, preprocessing, sentence alignment and post-processing. The primary application field of PhoMT is machine translation, especially Vietnamese-to-English translation, with the goal of enhancing translation quality and efficiency and providing a solid foundation for related research.
提供机构:
VinAI Research, Hanoi, Vietnam
创建时间:
2021-10-23
搜集汇总
数据集介绍
构建方式
PhoMT数据集的构建过程分为四个阶段。首先,从公开资源中收集包含原始英文文档及其越南语翻译版本的平行文档对。然后进行预处理,包括生成干净且高质量的平行文档对,并从这些对中提取句子。接下来是平行句子对齐阶段,使用强大的神经机器翻译引擎Google Translate将英文源句子翻译成越南语,并利用Hunalign、Gargantua和Bleualign三个工具包进行句子对齐。最后进行后处理,包括规范化标点符号,移除重复的句子对,并手动验证验证集和测试集的质量。
使用方法
使用PhoMT数据集的方法包括:1. 用于训练机器翻译模型;2. 进行模型评估,比较不同模型的性能;3. 作为越南语-英语机器翻译研究的基准数据集。
背景与挑战
背景概述
随着越南经济的快速增长,高质量越南语-英语机器翻译(MT)的需求日益增加。然而,尽管越南语是世界上使用人数最多的语言之一,但由于公开可用的平行语料库规模小且质量低,导致越南语在MT研究中被视为低资源语言。为了解决这一问题,VinAI Research的研究人员创建了一个名为PhoMT的高质量、大规模的越南语-英语平行语料库,包含3.02M个句子对,比IWSLT15语料库多2.9M个句子对。PhoMT数据集的创建旨在为未来的越南语-英语MT研究提供一个起点,并为相关应用提供支持。
当前挑战
PhoMT数据集面临的挑战主要包括:1) 高质量越南语-英语平行语料库的缺乏;2) 大规模平行语料库的噪声问题。虽然已经有一些公开的越南语-英语平行语料库,但它们要么规模较小,要么包含大量低质量的翻译对,包括语义不匹配的句子。为了构建PhoMT数据集,研究人员采用了多种数据源,包括WikiHow、TED-Talks、OpenSubtitles、MediaWiki、News和Blogspot等,并通过手动检查和过滤来确保翻译对的质量。此外,研究人员还使用了多种工具和技术,如Hunalign、Gargantua、Bleualign等,来对句子进行对齐,并通过实验验证了mBART模型在PhoMT数据集上的有效性。
常用场景
经典使用场景
PhoMT数据集被广泛用于越南语-英语机器翻译任务,通过提供大规模且高质量的平行语料库,为研究人员和开发者提供了训练和评估机器翻译模型的基准数据。这一数据集的独特之处在于其规模和准确性,使得研究人员能够训练出更接近人类翻译水平的机器翻译模型。PhoMT数据集的经典使用场景包括但不限于:训练和评估机器翻译模型、开发翻译工具和应用程序、以及进行越南语-英语翻译的学术研究。
解决学术问题
PhoMT数据集解决了越南语-英语机器翻译领域的一个关键问题:缺乏大规模且高质量的平行语料库。越南语作为一种低资源语言,其机器翻译研究面临着数据不足和质量不高的挑战。PhoMT数据集的发布为越南语-英语机器翻译研究提供了宝贵的数据资源,推动了该领域的发展。此外,PhoMT数据集还解决了平行语料库中常见的问题,如句子对齐不准确、翻译质量低等,从而提高了机器翻译模型的效果。
实际应用
PhoMT数据集在实际应用场景中具有广泛的应用前景。例如,它可以用于开发越南语-英语翻译工具,帮助越南语用户更好地理解和沟通英语信息。此外,PhoMT数据集还可以用于构建智能客服系统、语音识别系统等,为用户提供更便捷的语言服务。PhoMT数据集的应用不仅局限于越南语-英语翻译,还可以推广到其他低资源语言的机器翻译研究中,为全球语言服务提供支持。
数据集最近研究
最新研究方向
PhoMT数据集的发布标志着越南语-英语机器翻译领域的重要进展。该数据集的规模和质量为研究提供了坚实的基础,有助于开发更高效的数据创建策略,尤其是在低资源语言领域。通过对比强基线和知名自动翻译引擎,研究发现预训练的序列到序列降噪自动编码器mBART在自动和人工评估中均取得了最佳性能。这一结果进一步证实了多语言降噪预训练对神经机器翻译的定量有效性。未来研究可以在此基础上探索更多越南语-英语机器翻译的应用,以及如何利用PhoMT数据集促进低资源语言的机器翻译研究。
相关研究论文
- 1PhoMT: A High-Quality and Large-Scale Benchmark Dataset for Vietnamese-English Machine TranslationVinAI Research, Hanoi, Vietnam · 2021年
以上内容由遇见数据集搜集并总结生成


