PoliWAM
收藏Hugging Face2025-08-03 更新2025-08-04 收录
下载链接:
https://huggingface.co/datasets/LingoIITGN/PoliWAM
下载链接
链接失效反馈官方服务:
资源简介:
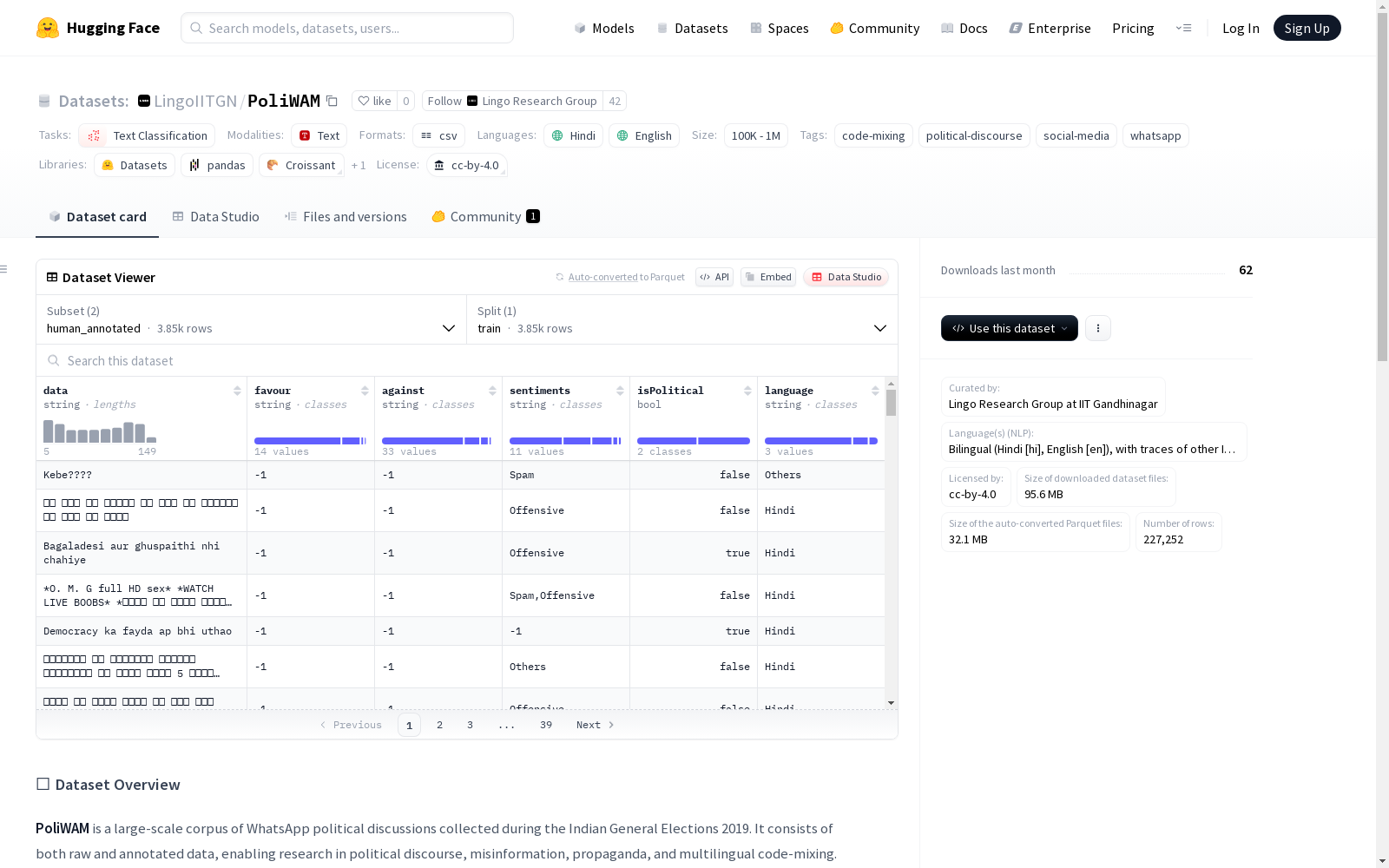
PoliWAM是一个收集自2019年印度大选期间WhatsApp政治讨论的大型双语文本语料库,包括原始数据和人工注释数据。它支持对政治话语、错误信息、宣传以及多语言代码混合的研究。语料库中包含223,000条消息,涵盖281个公开政治群组,涉及约31,000个独立用户。数据集的一部分(3,848条消息)经过了人工标注,标注内容包括政治倾向、语言组成、恶意意图以及党派倾向性。语料库语言为印地语和英语,并含有其他印度语言的少量痕迹。
创建时间:
2025-07-30
原始信息汇总
PoliWAM 数据集概述
基本信息
- 许可证: cc-by-4.0
- 任务类别: 文本分类
- 标签:
- 代码混合
- 政治讨论
- 社交媒体
- 语言: 印地语 (hi)、英语 (en)
- 规模: 1M < n < 10M
数据集配置
- human_annotated:
- 数据文件: WhatsApp_annotated_dataset.csv
- 分割: train
- raw:
- 数据文件: Raw/msg.csv
- 分割: train
数据集详情
- 总消息数: 223,000
- 群组数: 281 个公共政治群组
- 用户数: ~31,000 个唯一用户
- 标注子集: 3,848 条消息,标注内容包括:
- 政治倾向
- 语言组成
- 恶意意图
- 对特定政党的倾向
语言信息
- 主要语言: 双语 (印地语、英语)
- 其他语言痕迹: 马拉地语、古吉拉特语、孟加拉语等印度语言
免责声明
此数据集包含从公共 WhatsApp 群组收集的真实政治讨论内容,可能包含偏见、冒犯性或潜在有害内容,如仇恨言论、错误信息或政治宣传。数据集严格用于学术研究,使用时需采取适当的伦理保障和内容审核策略。
引用
如需使用此数据集,请引用以下文献:
@inproceedings{srivastava-singh-2021-poliwam, title = "{P}oli{WAM}: An Exploration of a Large Scale Corpus of Political Discussions on {W}hats{A}pp Messenger", author = "Srivastava, Vivek and Singh, Mayank", editor = "Xu, Wei and Ritter, Alan and Baldwin, Tim and Rahimi, Afshin", booktitle = "Proceedings of the Seventh Workshop on Noisy User-generated Text (W-NUT 2021)", month = nov, year = "2021", address = "Online", publisher = "Association for Computational Linguistics", url = "https://aclanthology.org/2021.wnut-1.15/", doi = "10.18653/v1/2021.wnut-1.15", pages = "120--130" }
联系方式
- 研究组: Lingo Research Group at IIT Gandhinagar
- 邮箱: lingo@iitgn.ac.in
搜集汇总
数据集介绍
构建方式
PoliWAM数据集的构建基于2019年印度大选期间从281个公共政治WhatsApp群组中采集的实时对话数据,采用混合方法学框架进行系统化整理。研究团队通过自动化爬取技术获取原始消息后,由语言学专家对3,848条代表性样本进行四维度人工标注,涵盖政治倾向、语言构成、恶意意图及政党倾向等关键特征,原始数据与标注数据分别以CSV格式存储,形成1M到10M规模的双语语料库。
特点
该数据集的核心价值体现在其独特的政治话语时空特性与多语言混合特征上。作为首个聚焦WhatsApp政治讨论的大规模语料库,其22.3万条消息完整保留了印度多语言社会语境下的代码混合现象,包含印地语、英语及其他印度语言的有机交织。标注子集通过精细的类别体系揭示了政治传播中的立场表达模式,特别适合研究数字时代政治传播的演化规律、多语言环境下的语义表征以及虚假信息检测等前沿课题。
使用方法
研究者可通过HuggingFace平台获取两种结构化数据配置:原始消息集适用于无监督学习或数据挖掘,而人工标注集支持监督式文本分类任务。使用时应特别注意数据伦理规范,建议配合内容过滤机制处理可能存在的敏感信息。典型应用场景包括构建政治立场分类器、多语言代码混合分析模型,或结合时序特征研究选举周期中的舆论演变,引用时需遵循CC-BY-4.0许可协议并参照指定文献格式。
背景与挑战
背景概述
PoliWAM数据集由印度理工学院甘地纳加尔分校的Lingo研究小组于2021年构建,旨在探索2019年印度大选期间WhatsApp平台上的政治讨论动态。作为首个大规模政治话语语料库,该数据集收录了28个公共政治群组中超过22万条双语对话,涵盖印地语和英语的代码混合现象。其标注子集对3848条消息进行了政治倾向、语言构成、恶意意图等多维度人工标注,为计算社会科学和自然语言处理领域提供了研究政治传播、虚假信息和社会网络行为的重要资源。该数据集的发布填补了非正式政治话语分析的数据空白,对理解数字时代的政治传播生态具有开创性意义。
当前挑战
PoliWAM数据集面临的核心挑战体现在研究与应用两个维度。在学术层面,政治话语的多标签分类需解决代码混合文本中语言特征与政治语义的耦合问题,且恶意意图识别需克服隐晦表达与语境依赖的解析难题。数据构建过程中,研究团队需应对即时通讯数据的动态性、用户匿名性带来的伦理审查压力,以及多语言混杂导致的标注一致性控制等操作挑战。此外,原始数据包含的敏感内容要求研究者建立严格的内容过滤机制,这对数据集的合规使用提出了更高要求。
常用场景
经典使用场景
在政治传播学与计算社会科学领域,PoliWAM数据集为研究者提供了独特的分析视角。该数据集捕捉了2019年印度大选期间WhatsApp平台上的实时政治对话,其标注子集特别适用于探究多语言混杂环境下的政治立场表达模式。研究者可基于3,848条人工标注数据,深入分析政治倾向与语言特征之间的关联,或构建政治立场分类模型。
实际应用
在现实应用中,PoliWAM数据集的价值体现在多个维度。政策制定者可借助该数据集开发早期预警系统,识别潜在的虚假信息传播模式。社交媒体平台能基于其恶意内容标注改进内容审核算法。政治分析师则可通过语言特征分析,把握不同选民群体的沟通偏好,为竞选策略提供数据支持。
衍生相关工作
该数据集已催生多项重要研究成果。在ACL 2021会议上发表的基准论文建立了政治立场分类框架,后续研究则扩展至多语言虚假信息检测模型的构建。部分学者结合该数据集开发了新型的代码混合文本处理技术,另有工作聚焦于跨文化政治传播比较研究,推动了计算社会科学与NLP的交叉创新。
以上内容由遇见数据集搜集并总结生成


