VfxDB
收藏Hugging Face2026-04-27 更新2026-04-28 收录
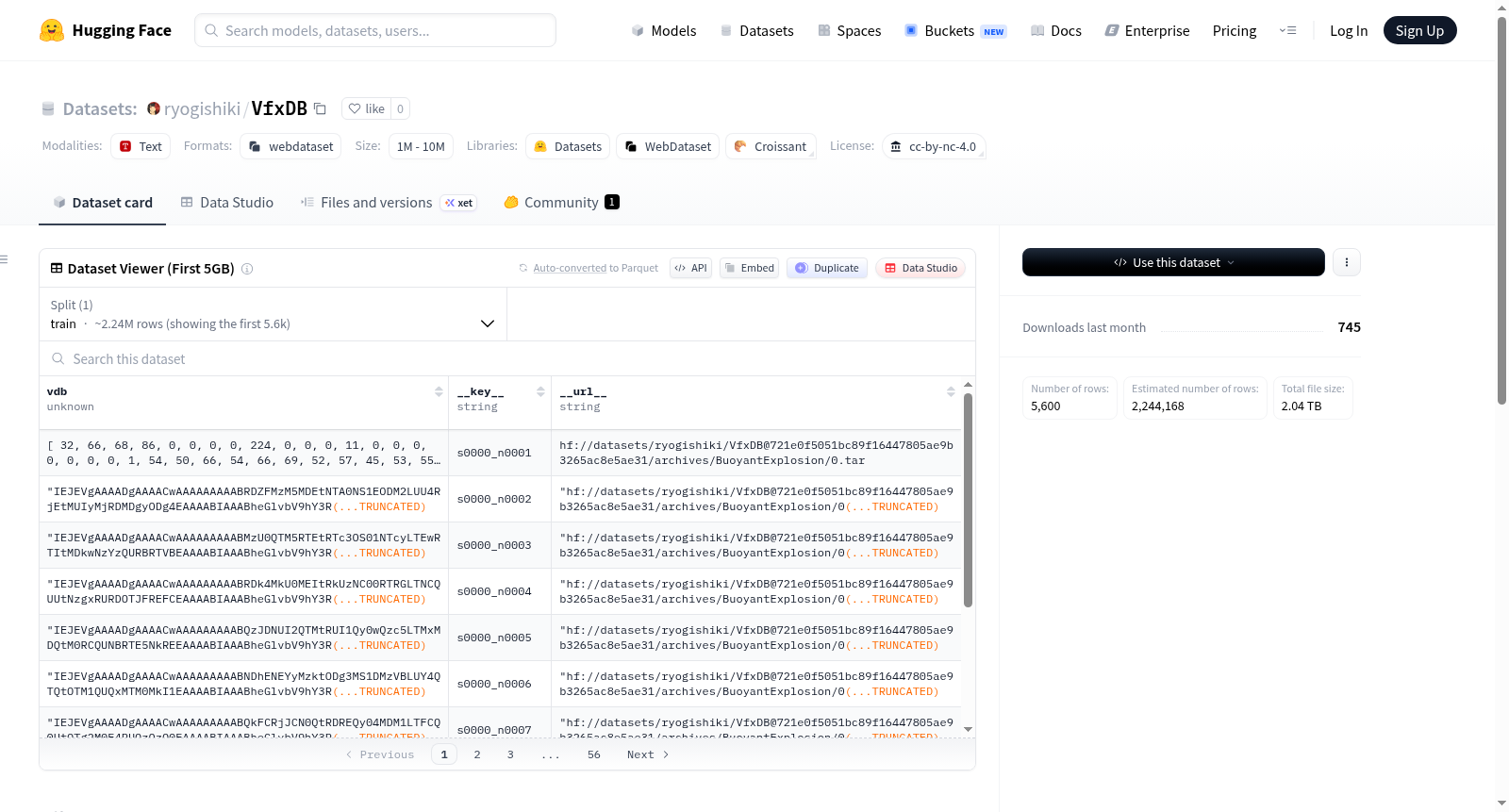
下载链接:
https://huggingface.co/datasets/ryogishiki/VfxDB
下载链接
链接失效反馈官方服务:
资源简介:
VfxDB是一个大规模高分辨率OpenVDB序列数据集,包含100万个样本,总大小约为5TB。该数据集目前正在积极构建中,预计将在SIGGRAPH 2026修订版中正式发布。数据集适用于生成建模任务,并提供了标准化的基准分割和一个用于快速验证的小型子集。数据集还包括用于稀疏体数据优化的VDB-native IO工具和数据预处理脚本。许可证为cc-by-nc-4.0。
VfxDB is a large-scale high-resolution OpenVDB sequence dataset containing 1 million samples with a total size of approximately 5TB. The dataset is currently under active construction and is expected to be officially released in the SIGGRAPH 2026 revision. The dataset is suitable for generative modeling tasks and provides standardized benchmark splits and a small subset for quick validation. The dataset also includes VDB-native IO tools and data preprocessing scripts for sparse volumetric data optimization. The license is cc-by-nc-4.0.
创建时间:
2026-04-17
原始信息汇总
根据您提供的数据集详情页面内容,以下是关于 VfxDB 数据集的总结:
数据集概述
- 名称:VfxDB (Visual Effects Database)
- 许可证:CC BY-NC 4.0(知识共享-非商业使用 4.0 国际许可)
- 规模:超过 1TB,具体包含约 100 万样本,总大小约为 5TB
- 当前状态:正在积极构建中,计划于 SIGGRAPH 2026 发布最终版本
数据集内容与特点
- 数据类型:高分辨率 OpenVDB 序列(稀疏体数据)
- 数据规模:100 万样本,约 5TB
- 发布计划:
- 优先发布:标准化基准测试集划分(Standardized Benchmark Splits)和用于快速验证的迷你子集(mini-subset)
- 完整数据集将在正式截止日期前完全开放访问
配套资源(待发布)
- 代码库:
- 端到端评估流程(Evaluation Pipeline)
- VDB 原生 IO 工具(针对稀疏体数据优化)
- 文档:
- 安装指南
- 环境配置(含 Docker 容器)
- 使用示例
- 数据处理:
- VDB 原生 IO 工具及数据预处理脚本
- 数据集使用示例
当前进展 (截至 2026 年 4 月)
- [ ] 数据集同步进展中:约 5TB 的 100 万样本正在上传至托管服务器
- [ ] 代码库正在完善:端到端评估流程和 VDB 原生 IO 工具正在优化
- [ ] 文档待集成:安装指南、环境配置和使用示例即将完成
- [ ] 数据集使用示例待上传
注意:所有材料(包括完整数据集和生成建模框架)将在正式发布截止日期前完全开放访问。
搜集汇总
数据集介绍
构建方式
VfxDB是一个面向视觉特效领域的大规模开源数据集,专为支持生成式建模算法在复杂稀疏体积数据上的训练与评估而构建。其构建过程覆盖了来自工业级视觉特效管线的一百万个高分辨率OpenVDB序列样本,总数据量接近5TB,充分反映了真实影视特效场景中体积数据的多样性与复杂性。目前该数据集正在经由高性能服务器进行系统性同步上传,并优先释放标准化基准分割与供快速验证的小型子集,以确保科研社区能够高效获取并使用。
特点
VfxDB的核心特点在于其空前的规模与专业化的数据形态。一百万样本、约5TB的数据体量使其成为视觉特效领域目前已知的同类数据集中最为庞大的存在。所有数据均采用OpenVDB这一行业标准格式存储,天然适配稀疏体积数据的特性,兼顾存储效率与读取性能。该数据集不仅提供完整的训练与评测样本,还计划配套推出专为稀疏数据优化的VDB原生IO工具与端到端评估管线,极大提升了在视觉特效生成任务中的实用性与可复现性。
使用方法
使用VfxDB时,用户可借助其即将发布的VDB原生IO工具与数据预处理脚本高效加载高分辨率稀疏体积序列。数据集提供了标准化的基准分割,便于直接应用于生成模型的训练与对比评估。为了简化环境配置,官方还将提供完整的Docker容器与安装指南。当前,用户可通过优先释放的迷你子集快速验证模型的运行准确性,待全部数据与代码框架正式发布后,即可开展完整的大规模生成式体积建模实验与性能评测。
背景与挑战
背景概述
VfxDB是一个面向计算机图形学与视觉特效领域的大规模三维体积数据集,由研究团队为SIGGRAPH 2026构建,旨在解决高精度体积数据在生成式建模中的稀缺问题。该数据集包含约100万个样本,总容量约5TB,以OpenVDB格式存储高分辨率稀疏体积序列,服务于动态烟雾、火焰、云层等特效的深度学习研究。VfxDB的创建标志着体积数据标准化基准的建立,有望推动神经渲染、物理仿真及生成对抗网络在影视工业中的落地应用,对提升视觉特效的真实感与自动化水平具有深远意义。
当前挑战
VfxDB面临的核心挑战在于三大方面:首先,领域问题层面,现有模型难以从稀疏、高维的体积场中学习连续物理演化,数据集通过百万级样本推动生成式模型突破时间相干性与细节保真度。其次,构建过程中,超大规模数据(5TB)的同步与托管面临存储与带宽瓶颈,团队需优先发布标准化基准分割与微型子集以加速验证。最后,配套工具链的完善,包括VDB-native IO工具与端到端评估管线的优化,对于降低社区使用门槛至关重要,直接决定数据集的实践影响力。
常用场景
经典使用场景
VfxDB数据集专为大规模稀疏体积数据生成任务而设计,其经典使用场景聚焦于利用深度生成模型(如扩散模型或隐式神经表示)对百万级高分辨率OpenVDB序列进行建模与合成。研究者可基于该数据集的标准基准划分,训练能够捕捉复杂流体、烟云或爆炸等物理现象的时序体积生成器,从而在视觉特效与动态体积仿真领域实现突破性进展。
解决学术问题
该数据集解决了稀疏体积数据领域缺乏大规模、高保真基准的长期困境,填补了传统体积数据集规模小且缺乏时序连贯性的研究空白。通过提供约5TB的标准化样本,VfxDB推动了生成模型在三维体积序列上的可扩展性研究,并使得验证非均匀网格下的时空一致性生成算法成为可能,为稀疏体素表示的统计学习奠定了数据基础。
衍生相关工作
VfxDB的出现催生了一系列后续经典工作,包括基于流匹配的稀疏体积扩散框架(如VDB-Diff)、面向非结构化网格的Transformer架构(如VoxelFormer),以及结合物理模拟的神经场约束方法。此外,研究人员还开发了面向OpenVDB原生格式的高效IO库,并提出了针对大规模体素数据的混合压缩方案,进一步拓展了该数据集在生成式人工智能与计算机图形学交叉领域的影响力。
以上内容由遇见数据集搜集并总结生成


