vista26/VistaQA
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/vista26/VistaQA
下载链接
链接失效反馈官方服务:
资源简介:
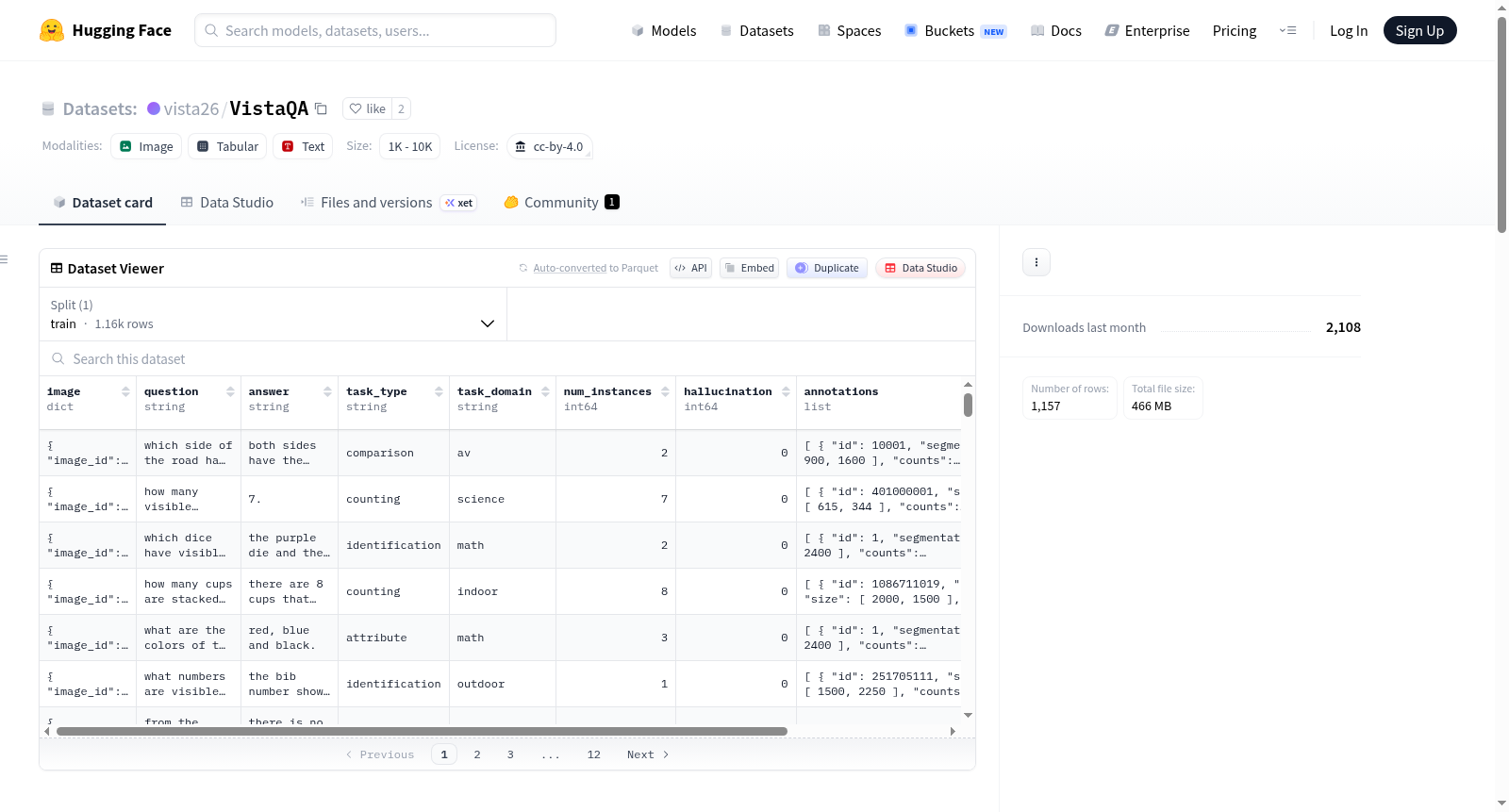
VistaQA是一个用于联合评估自由形式答案正确性和像素级视觉证据对齐的视觉问答基准。它包含1,157个专家精心挑选的样本,涵盖六种任务类型和六种视觉领域,从感知到组合和关系推理。每个样本都需要一个文本答案和相应的支持预测的分割掩码。基准还包括没有有效视觉证据的幻觉感知样本。
VistaQA is a benchmark for the joint evaluation of free-form answer correctness and pixel-level visual evidence alignment in visual question answering. It contains 1,157 expert-curated samples across six task types and six visual domains, spanning perception to compositional and relational reasoning. Each sample requires both a textual answer and corresponding segmentation masks that support the prediction. The benchmark also includes hallucination-aware samples in which no valid visual evidence exists.
提供机构:
vista26
搜集汇总
数据集介绍
构建方式
VistaQA数据集的构建始于对视觉问答领域中联合评估文本答案正确性与像素级视觉证据对齐这一关键需求的深刻洞察。研究者精心遴选了1157个样本,这些样本跨越了从基础感知到复杂组合与关系推理的六种任务类型,并覆盖了AV、室内、室外、机器人、数学和科学六大视觉领域。每个样本均由领域专家手工标注,不仅提供了自由形式的文本答案,还为核心预测提供了对应的分割掩码作为视觉支撑。尤为重要的是,为检验模型的幻觉检测能力,数据集特意纳入了部分样本,这些样本的答案虽看似合理,但在图像中并不存在有效的视觉证据,从而构建了一个全面而严谨的评估基准。
特点
VistaQA数据集的核心特色在于其双重评估维度,它率先将答案的语义正确性与支撑性视觉证据的像素级对齐度相融合,为VQA模型提供了一种更贴近真实视觉理解需求的评测范式。其丰富的任务类型,包括属性识别、目标检测、OCR、计数、空间推理与比较,全面覆盖了视觉推理的不同层次。同时,跨领域的视觉域设计确保了评估的泛化性。尤其值得关注的是其幻觉感知机制,通过设置是否包含有效视觉证据的标记(hallucination字段),数据集能够精准测试模型在信息缺失或矛盾场景下的鲁棒性,这是现有基准所不具备的独特优势。
使用方法
使用VistaQA数据集时,用户需将每张图片(.jpg或.png)与其同名的JSON格式注释文件配对加载。JSON文件中包含了问题的文本描述、标准答案、任务类型和领域标签,以及一系列以RLE编码格式存储的分割掩码,这些掩码构成了支持答案的视觉证据。评估模型时,不仅需要衡量生成的自由形式答案与标准答案的语义匹配度,还需对比模型输出的注意力或分割结果与给定的像素级证据的吻合程度。对于hallucination标记为1的样本,模型应能正确辨识出视觉证据的缺失。研究者可以通过调整答案准确性证据一致性两项指标的权重,来全面衡量其VQA系统的综合性能。
背景与挑战
背景概述
视觉问答(VQA)领域在近年来取得了显著进展,但现有基准大多局限于评估答案的文本准确性,忽视了模型提供像素级视觉证据对齐的能力,这限制了模型可解释性与可信度的发展。为弥合这一鸿沟,VistaQA数据集应运而生。该数据集由研究团队于近期创建,核心研究问题在于实现自由形式答案正确性与像素级视觉证据一致性的联合评估。VistaQA包含1,157个专家精选样本,覆盖六种任务类型(属性、识别、OCR、计数、空间、比较)与六个视觉领域(AV、室内、室外、机器人、数学、科学),从感知到组合与关系推理,全面考验模型的深层理解能力。该数据集对推动可解释视觉推理的研究具有重要影响力,为构建更可靠的VQA模型提供了标准化的评估框架。
当前挑战
VistaQA所解决的领域问题核心挑战在于,传统VQA评估仅关注答案文本,而忽略了模型决策所依赖的视觉依据,导致模型在幻觉或错误推理时无法被有效识别。为应对此挑战,数据集中特别引入了幻觉感知样本,其中不存在有效视觉证据,迫使模型必须学会证据缺失时的正确回应。在构建过程中,团队面临多重挑战:需精准定义六种任务类型的像素级标注标准,确保标注员在复杂场景(如遮挡、计数)中一致地标注支撑证据;处理大规模图像中分割掩码的精细化与一致性,尤其是在密集目标或重叠区域;同时平衡样本的覆盖面与质量,仅1,157个精选样本就需兼顾多样性、难度与领域代表性,这对专家标注的准确性与时间成本提出了极高要求。
常用场景
经典使用场景
VistaQA数据集为视觉问答领域引入了一种全新的评价范式,其经典使用场景在于同时衡量模型生成的自由形式答案的准确性以及与之对应的像素级视觉证据的匹配程度。通过精心设计的1,157个专家标注样本,该数据集跨越了属性识别、计数、空间推理等六种任务类型,并覆盖室内外场景、机器人视觉、数学与科学图表等多个视觉领域。研究者可以利用这一基准,系统评估模型在提供正确答案的同时,是否能够输出精确的分割掩码来支撑其预测,从而推动视觉问答系统从“仅求答案正确”向“解释性推理”的纵深方向发展。
实际应用
在实际应用层面,VistaQA所倡导的联合评估范式直接服务于对可靠性要求极高的视觉问答系统。例如,在医疗影像辅助诊断中,模型不仅需要给出病变类型的答案,还必须通过分割掩码指明病灶位置,以便医生验证结果的合理性;在自动驾驶场景中,对“路标是否被树枝遮挡”这类问题的回答需伴随明确的视觉证据,方能确保决策的可信度。此外,在机器人交互、教育辅助和科学图表分析等场景中,该数据集提供的评估框架能够帮助开发者检测模型是否存在“胡言乱语”式的幻觉行为,从而过滤不可靠输出,提升系统的安全性和用户体验。
衍生相关工作
VistaQA的发布催生了一系列富有启发性的后续研究工作。围绕该基准,研究者们开始探索将视觉定位能力与问答推理深度融合的模型架构,例如设计端到端的定位-回答联合网络,以及引入注意力机制与分割解码器协同优化的方法。同时,该数据集中幻觉样本的引入激发了针对视觉问答中证据缺失场景的专项研究,衍生出诸如“无证据拒绝回答”、“视觉事实性检测”等子任务。此外,一些工作将VistaQA的像素级证据标注思想拓展至视频问答、多轮对话等更复杂的交互场景,推动了视觉语言理解领域向更具可解释性和事实一致性的方向演进。
以上内容由遇见数据集搜集并总结生成


