CompoundQA
收藏arXiv2024-11-15 更新2024-11-19 收录
下载链接:
http://arxiv.org/abs/2411.10163v1
下载链接
链接失效反馈官方服务:
资源简介:
CompoundQA 是由上海财经大学和南方科技大学等机构联合创建的一个用于评估大型语言模型(LLMs)处理复合问题的基准数据集。该数据集包含1500个复合问题,涵盖语言理解、推理和知识三个维度,分为事实陈述、因果关系、假设分析、比较选择和评估建议五种类型。数据集通过复合问题合成框架(CQ-Syn)生成,并经过人工审核确保质量。CompoundQA 旨在解决实际应用中用户常提出的复合问题,评估和提升 LLMs 在复杂交互场景中的表现。
CompoundQA is a benchmark dataset jointly created by Shanghai University of Finance and Economics, Southern University of Science and Technology, and other institutions for evaluating large language models (LLMs) in handling compositional questions. It contains 1,500 compositional questions spanning three dimensions: language understanding, reasoning, and knowledge, and is categorized into five types: factual statements, causal relationships, hypothetical analysis, comparative choices, and evaluative suggestions. The dataset is generated via the Compositional Question Synthesis framework (CQ-Syn) and undergoes manual review to ensure data quality. CompoundQA aims to address the compositional questions frequently raised by users in real-world applications, as well as to evaluate and enhance the performance of LLMs in complex interaction scenarios.
提供机构:
上海财经大学, 南方科技大学, 香港中文大学, 复旦大学
创建时间:
2024-11-15
搜集汇总
数据集介绍
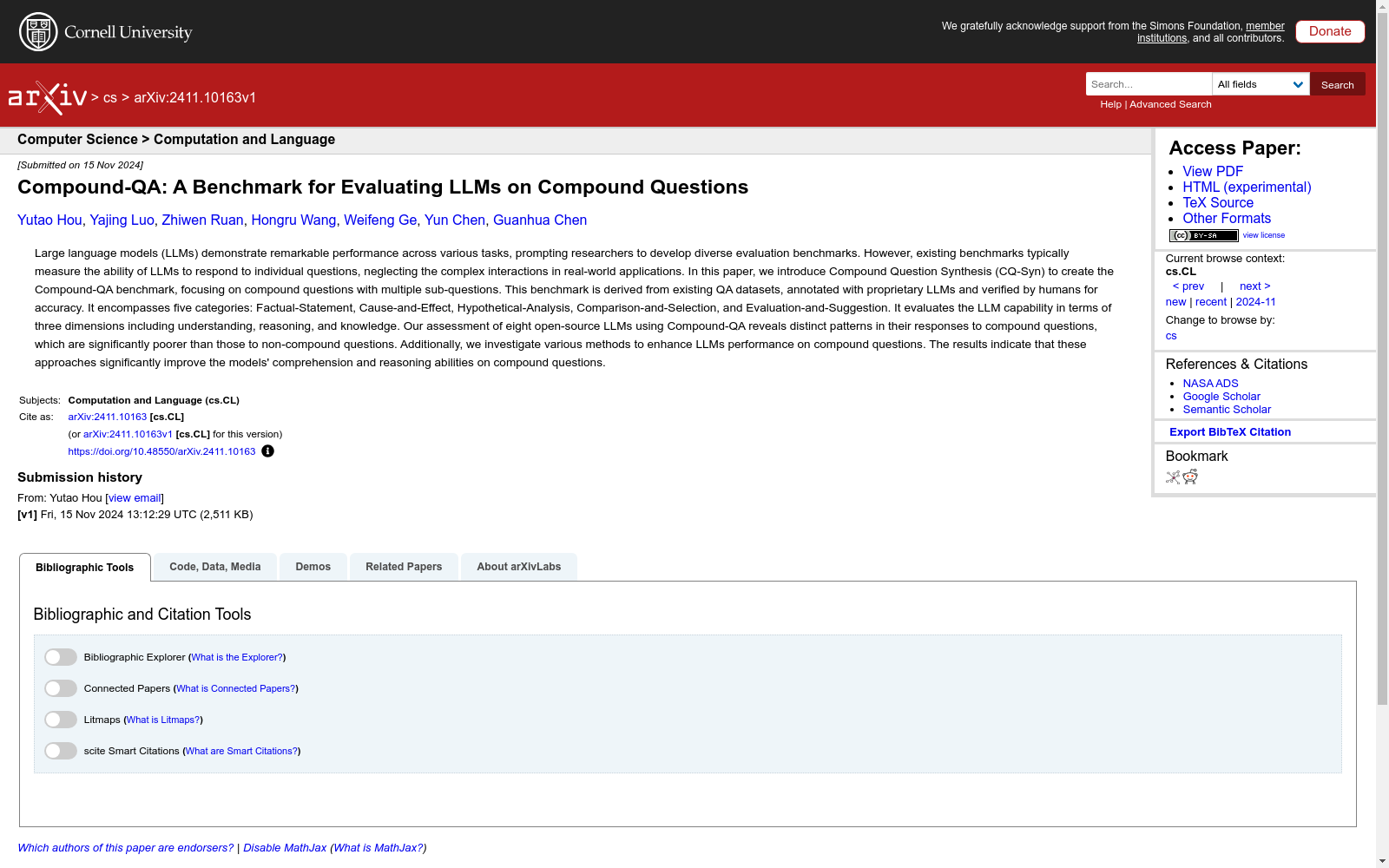
构建方式
CompoundQA数据集通过引入复合问题合成(CQ-Syn)框架构建,该框架利用大型语言模型(LLM)生成和细化复合问题。这些复合问题包含多个子问题,涵盖事实陈述、因果关系、假设分析、比较选择和评估建议五种类型。生成的问题经过关键词过滤和LLM验证,确保其准确性和相关性。最终,每个复合问题都由人工进行审查和修订,以确保数据集的高质量。
使用方法
CompoundQA数据集主要用于评估大型语言模型在处理复合问题时的表现。研究者可以通过该数据集测试模型在不同类型复合问题上的理解、推理和知识能力。使用时,可以将数据集分为训练集和测试集,对模型进行微调或直接评估。此外,数据集还可以用于开发新的模型增强策略,以提高模型在处理复合问题时的性能。
背景与挑战
背景概述
CompoundQA数据集由上海财经大学、南方科技大学、香港中文大学和复旦大学的研究人员于2024年创建,旨在评估大型语言模型(LLMs)处理复合问题的能力。复合问题是指在一个查询中包含多个子问题,这些子问题在现实应用中常常相互关联。CompoundQA数据集通过Compound Question Synthesis(CQ-Syn)框架生成,该框架利用LLMs生成和细化复合问题,并通过人工审查确保其准确性。数据集涵盖五个类别:事实陈述、因果关系、假设分析、比较与选择以及评估与建议,旨在从理解、推理和知识三个维度评估LLMs的能力。
当前挑战
CompoundQA数据集面临的挑战主要集中在两个方面:一是解决领域问题,即如何有效处理复合问题,这类问题在现实应用中普遍存在,要求模型能够理解并逐一回答多个相互关联的子问题;二是构建过程中遇到的挑战,包括生成高质量复合问题的难度、确保生成的复合问题符合特定类别的要求,以及通过人工验证确保数据集的准确性和可靠性。此外,模型在处理复合问题时容易出现子问题遗漏、上下文干扰和子问题引用模糊等问题,这些问题都需要进一步研究和优化。
常用场景
经典使用场景
CompoundQA 数据集的经典使用场景在于评估大型语言模型(LLMs)处理复合问题的能力。复合问题通常包含多个子问题,这些子问题在单个查询中相互关联。通过使用 CompoundQA,研究人员可以系统地测试模型在理解、推理和知识方面的表现,特别是在处理包含多个子问题的复杂查询时。这种评估有助于揭示模型在实际应用中处理复杂交互的能力,尤其是在人机对话和基于代理的场景中。
解决学术问题
CompoundQA 数据集解决了现有基准测试中忽视的一个关键学术问题,即大型语言模型在处理复合问题时的表现。现有的基准测试主要关注模型对单个问题的响应能力,而忽略了现实应用中用户常常在一个查询中提出多个相关问题的情况。通过引入 CompoundQA,研究人员能够更全面地评估模型在处理复杂查询时的理解、推理和知识能力,从而推动对模型性能的深入理解和改进。
实际应用
在实际应用中,CompoundQA 数据集有助于提升大型语言模型在多轮对话和复杂查询处理中的表现。例如,在客户服务、教育辅导和智能助手等领域,用户往往在一次对话中提出多个相关问题。通过使用 CompoundQA 进行训练和评估,模型能够更好地理解和响应这些复合问题,从而提高用户体验和系统效率。此外,该数据集还可用于开发和优化面向复杂任务的智能代理,提升其在实际应用中的适应性和准确性。
数据集最近研究
最新研究方向
在自然语言处理领域,大型语言模型(LLMs)的评估基准不断发展,以应对其在复杂任务中的表现。最近的研究方向集中在开发能够处理复合问题的评估基准,如CompoundQA。该数据集通过合成包含多个子问题的复合问题,旨在评估LLMs在理解、推理和知识方面的能力。研究者们通过对比不同LLMs在处理复合问题时的表现,发现这些模型在应对复合问题时存在显著的性能下降。此外,研究还探讨了通过监督微调和其他增强方法来提升LLMs处理复合问题的能力,这为未来提升LLMs在复杂交互场景中的表现提供了新的研究方向。
相关研究论文
- 1Compound-QA: A Benchmark for Evaluating LLMs on Compound Questions上海财经大学, 南方科技大学, 香港中文大学, 复旦大学 · 2024年
以上内容由遇见数据集搜集并总结生成


