FontGuard
收藏arXiv2025-04-04 更新2025-04-08 收录
下载链接:
https://github.com/KAHIMWONG/FontGuard
下载链接
链接失效反馈官方服务:
资源简介:
FontGuard数据集是由澳门大学的研究团队创建的一种字体水印技术,该技术通过深度字体模型和语言引导的对比学习来提高字体水印的鲁棒性和嵌入容量。数据集包含了经过特殊处理的字体,这些字体在视觉上与原始字体相似,但包含了隐藏的信息。该数据集的创建目的是为了提高水印技术在文本内容中的版权保护、来源追踪等问题上的应用效果。
The FontGuard Dataset is a font watermarking technology developed by a research team from the University of Macau. This technology enhances the robustness and embedding capacity of font watermarking via deep font models and language-guided contrastive learning. The dataset comprises specially processed fonts that are visually similar to their original versions but carry hidden information. The dataset was created to improve the application performance of watermarking technologies in scenarios including copyright protection and source tracing for textual content.
提供机构:
澳门大学
创建时间:
2025-04-04
原始信息汇总
FontGuard 数据集概述
数据集简介
FontGuard 是一种新颖的字体水印模型,利用字体模型和语言引导对比学习的能力。该方法通过修改隐藏的样式特征来嵌入水印,相比仅关注像素级修改的现有方法,能提供更好的字体质量。此外,该方法利用字体流形生成大量与原始字体相似的变体,提高了水印嵌入容量。解码器采用图像-文本对比学习重建嵌入位,对各种现实传输失真具有鲁棒性。
数据集内容
- 水印字体示例:提供1位水印的SimSun字体SVG文件,包含两种变体。
- 测试集:包含7种分发场景下的测试数据,每个场景包含1000个分割字符图像。
- OSNs场景测试集:WeChat、Weibo、Whatsapp、Facebook
- 跨媒体场景测试集:print_camera、screen_camera、screenshots
- 辅助文件:
bit_seq.txt:测试集的比特流真实值dec.pth:解码器检查点GB2312_CN6763.txt:字符集
数据获取与使用
- 下载地址:百度网盘 (密码: rocu)
- 使用说明:
- 更新
cfg.py中的路径 - 执行命令:
python test.py
- 更新
搜集汇总
数据集介绍
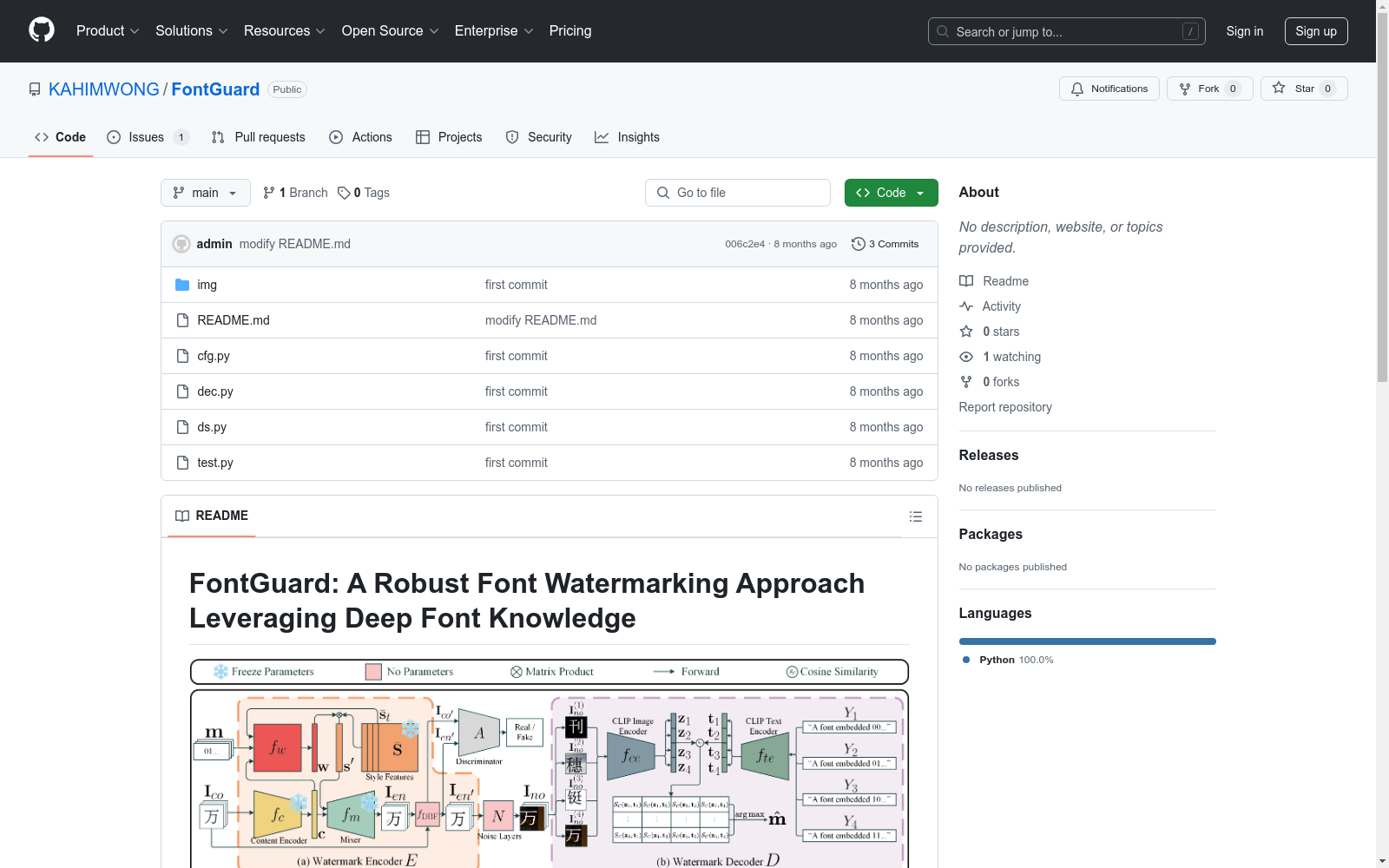
构建方式
FontGuard数据集的构建基于深度字体模型和语言引导的对比学习技术。通过修改字体的隐藏风格特征而非像素级变化,确保了水印嵌入后的字体质量。利用字体流形生成大量与原始字体相似但携带不同水印信息的变体,显著提升了嵌入容量。此外,解码器采用图像-文本对比学习框架,有效抵抗现实传输中的各类失真。
特点
FontGuard数据集在多个维度展现出卓越特性:1) 高保真性:通过风格特征扰动而非像素修改,水印字体与原始字体的视觉差异极小(LPIPS降低52.7%);2) 强鲁棒性:在合成失真、跨媒体传输和社交网络传播场景下,解码准确率分别领先现有技术5.4%、7.4%和5.8%;3) 泛化能力:支持未经训练的未见字体水印生成,突破传统方法需重新训练的局限。
使用方法
该数据集的使用遵循三阶段流程:1) 编码阶段将消息映射为风格特征偏移,通过预训练字体模型生成水印字体库;2) 传输阶段模拟现实信道失真,包含像素级噪声、空间变换及复杂背景叠加等增强;3) 解码阶段采用CLIP框架提取视觉-文本特征相似度,实现失真环境下的可靠信息提取。用户可通过调整位容量参数(BPC)平衡嵌入容量与鲁棒性,最高支持单字符4比特嵌入。
背景与挑战
背景概述
FontGuard数据集由澳门大学的研究团队于2025年提出,旨在解决AI生成内容(AIGC)时代下的版权保护与来源追溯问题。该数据集聚焦于字体水印技术,通过深度字体知识与语言引导的对比学习,实现了在文本内容中嵌入不可见水印信息的能力。作为多媒体取证领域的重要突破,FontGuard通过修改字体隐藏样式特征而非像素级扰动,显著提升了水印字体的视觉质量与嵌入容量,其解码准确率在合成、跨媒体和社交媒体失真场景下分别超越现有技术5.4%、7.4%和5.8%。该研究获得澳门科学技术发展基金等多项资助,相关代码与数据集已在GitHub开源。
当前挑战
FontGuard需应对两大核心挑战:在领域层面,传统字体水印方法存在嵌入容量低(如单字符仅0.5-1比特)、抗真实场景失真能力弱(如打印拍摄、社交媒体压缩)以及依赖精确字符分割等问题;在构建层面,研究团队需解决字体流形建模的复杂性、CLIP解码器初始训练不收敛的难题,以及保持生成字体视觉一致性与高容量嵌入的平衡。特别地,跨媒体传输中的几何变形与低分辨率字体导致的水印信息丢失,以及复杂背景干扰下的鲁棒解码,构成了技术实现的关键瓶颈。
常用场景
经典使用场景
FontGuard数据集在多媒体安全领域具有广泛的应用价值,尤其在文本水印技术方面表现突出。该数据集通过深度学习模型生成高质量的水印字体,能够有效嵌入信息并确保版权保护和内容可追溯性。其经典使用场景包括电子文档的版权标记、敏感信息的完整性验证以及AI生成内容的来源追踪。FontGuard通过修改字体的隐藏样式特征而非像素级变动,显著提升了水印字体的视觉质量和嵌入容量,使其在学术研究和实际应用中均展现出卓越性能。
实际应用
FontGuard数据集在实际应用中表现出强大的适应性和实用性。其生成的文本水印可广泛应用于商业合同、政府文件和学术论文等需要绝对句子完整性的场景。通过替换原始字体为扰动版本,FontGuard能够在文档中嵌入大量信息,同时保持内容的视觉一致性。该技术特别适用于跨媒体传输和在线社交网络分享的文档,能够有效抵抗打印拍摄、屏幕拍摄等复杂失真。此外,FontGuard的背景增强技术使其能够处理带有复杂背景的文档,进一步提升了实际应用中的鲁棒性和可靠性。
衍生相关工作
FontGuard数据集衍生了一系列相关研究工作,推动了文本水印技术的进步。基于其核心思想,研究人员开发了多种改进方法,如结合风格提示的解码器优化和风格一致性损失的引入,进一步提升了水印的视觉质量和解码准确性。FontGuard-GEN作为其扩展模型,能够为未见过的字体生成水印,展示了强大的泛化能力。此外,该数据集还启发了在自然语言处理、多媒体取证等领域的交叉应用,如文档完整性验证和AI生成内容溯源等。这些衍生工作不仅丰富了文本水印技术的研究范畴,也为相关领域的实际应用提供了有力支持。
以上内容由遇见数据集搜集并总结生成


