stanfordnlp/coqa
收藏Hugging Face2024-01-04 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/stanfordnlp/coqa
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- crowdsourced
language_creators:
- found
language:
- en
license:
- other
multilinguality:
- monolingual
size_categories:
- 1K<n<10K
source_datasets:
- extended|race
- extended|cnn_dailymail
- extended|wikipedia
- extended|other
task_categories:
- question-answering
task_ids:
- extractive-qa
paperswithcode_id: coqa
pretty_name: 'CoQA: Conversational Question Answering Challenge'
tags:
- conversational-qa
dataset_info:
features:
- name: source
dtype: string
- name: story
dtype: string
- name: questions
sequence: string
- name: answers
sequence:
- name: input_text
dtype: string
- name: answer_start
dtype: int32
- name: answer_end
dtype: int32
splits:
- name: train
num_bytes: 17953365
num_examples: 7199
- name: validation
num_bytes: 1223427
num_examples: 500
download_size: 12187487
dataset_size: 19176792
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
# Dataset Card for "coqa"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://stanfordnlp.github.io/coqa/](https://stanfordnlp.github.io/coqa/)
- **Repository:** https://github.com/stanfordnlp/coqa-baselines
- **Paper:** [CoQA: A Conversational Question Answering Challenge](https://arxiv.org/abs/1808.07042)
- **Point of Contact:** [Google Group](https://groups.google.com/forum/#!forum/coqa), [Siva Reddy](mailto:siva.reddy@mila.quebec), [Danqi Chen](mailto:danqic@cs.princeton.edu)
- **Size of downloaded dataset files:** 58.09 MB
- **Size of the generated dataset:** 19.24 MB
- **Total amount of disk used:** 77.33 MB
### Dataset Summary
CoQA is a large-scale dataset for building Conversational Question Answering systems.
Our dataset contains 127k questions with answers, obtained from 8k conversations about text passages from seven diverse domains. The questions are conversational, and the answers are free-form text with their corresponding evidence highlighted in the passage.
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Structure
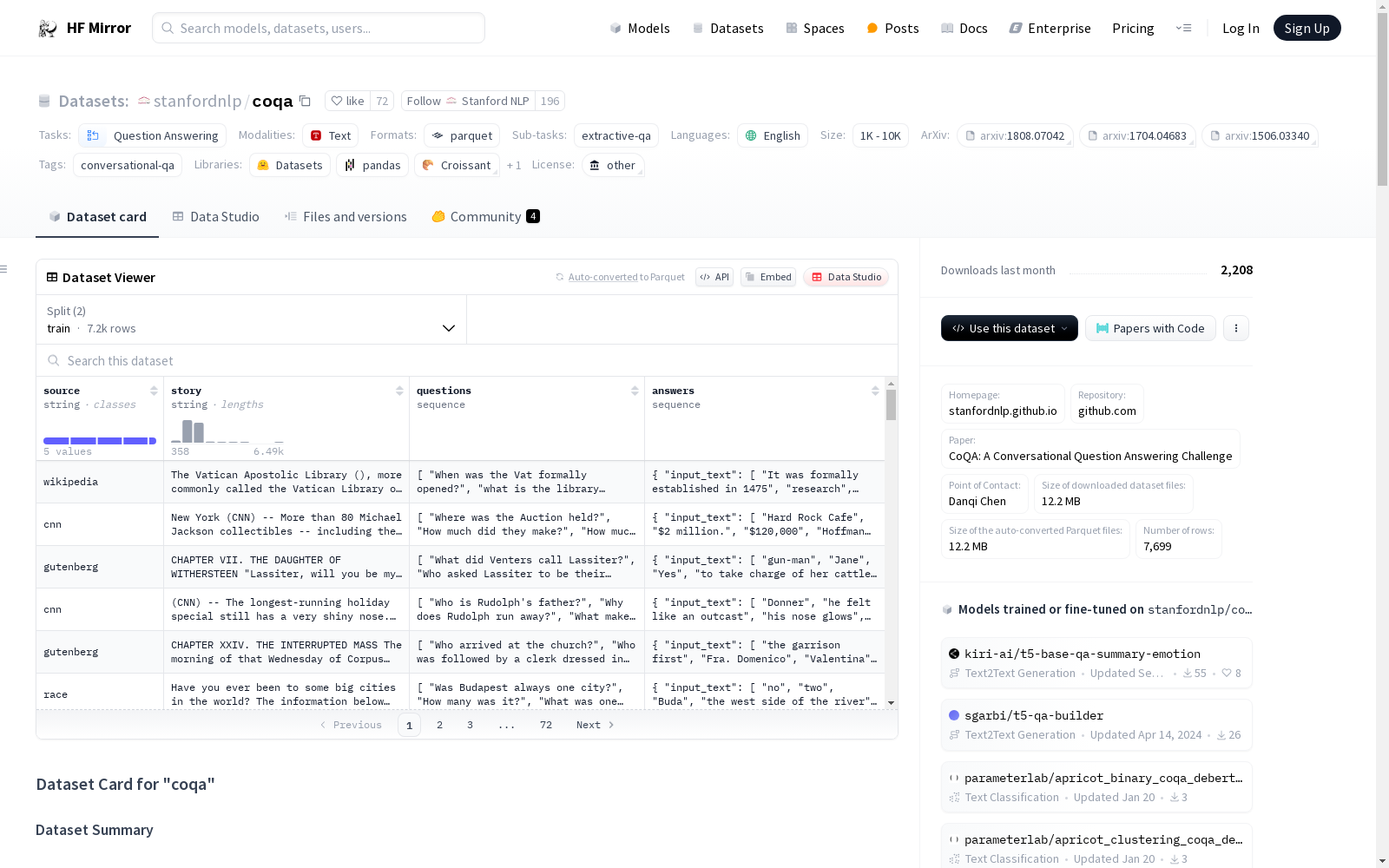
### Data Instances
#### default
- **Size of downloaded dataset files:** 58.09 MB
- **Size of the generated dataset:** 19.24 MB
- **Total amount of disk used:** 77.33 MB
An example of 'train' looks as follows.
```
This example was too long and was cropped:
{
"answers": "{\"answer_end\": [179, 494, 511, 545, 879, 1127, 1128, 94, 150, 412, 1009, 1046, 643, -1, 764, 724, 125, 1384, 881, 910], \"answer_...",
"questions": "[\"When was the Vat formally opened?\", \"what is the library for?\", \"for what subjects?\", \"and?\", \"what was started in 2014?\", \"ho...",
"source": "wikipedia",
"story": "\"The Vatican Apostolic Library (), more commonly called the Vatican Library or simply the Vat, is the library of the Holy See, l..."
}
```
### Data Fields
The data fields are the same among all splits.
#### default
- `source`: a `string` feature.
- `story`: a `string` feature.
- `questions`: a `list` of `string` features.
- `answers`: a dictionary feature containing:
- `input_text`: a `string` feature.
- `answer_start`: a `int32` feature.
- `answer_end`: a `int32` feature.
### Data Splits
| name |train|validation|
|-------|----:|---------:|
|default| 7199| 500|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
CoQA contains passages from seven domains. We make five of these public under the following licenses:
- Literature and Wikipedia passages are shared under [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/) license.
- Children's stories are collected from [MCTest](https://www.microsoft.com/en-us/research/publication/mctest-challenge-dataset-open-domain-machine-comprehension-text/) which comes with [MSR-LA](https://github.com/mcobzarenco/mctest/blob/master/data/MCTest/LICENSE.pdf) license.
- Middle/High school exam passages are collected from [RACE](https://arxiv.org/abs/1704.04683) which comes with its [own](http://www.cs.cmu.edu/~glai1/data/race/) license.
- News passages are collected from the [DeepMind CNN dataset](https://arxiv.org/abs/1506.03340) which comes with [Apache](https://github.com/deepmind/rc-data/blob/master/LICENSE) license.
### Citation Information
```
@article{reddy-etal-2019-coqa,
title = "{C}o{QA}: A Conversational Question Answering Challenge",
author = "Reddy, Siva and
Chen, Danqi and
Manning, Christopher D.",
journal = "Transactions of the Association for Computational Linguistics",
volume = "7",
year = "2019",
address = "Cambridge, MA",
publisher = "MIT Press",
url = "https://aclanthology.org/Q19-1016",
doi = "10.1162/tacl_a_00266",
pages = "249--266",
}
```
### Contributions
Thanks to [@patrickvonplaten](https://github.com/patrickvonplaten), [@lewtun](https://github.com/lewtun), [@thomwolf](https://github.com/thomwolf), [@mariamabarham](https://github.com/mariamabarham), [@ojasaar](https://github.com/ojasaar), [@lhoestq](https://github.com/lhoestq) for adding this dataset.
# 「CoQA」数据集元信息
annotations_creators: 标注创作者(annotations_creators):众包(crowdsourced)
language_creators: 数据生成方式(language_creators):源自现有公开文本(found)
language: 语言(language):英语(en)
license: 许可证(license):其他(other)
multilinguality: 多语言属性(multilinguality):单语言(monolingual)
size_categories: 样本规模(size_categories):1000 < 样本数量 < 10000
source_datasets: 源数据集(source_datasets):扩展RACE数据集、扩展CNN/Daily Mail数据集、扩展维基百科数据集及其他扩展数据集
task_categories: 任务类别(task_categories):问答任务(question-answering)
task_ids: 任务子类型(task_ids):抽取式问答(extractive-qa)
paperswithcode_id: PapersWithCode 标识符(paperswithcode_id):coqa
pretty_name: 数据集展示名:「CoQA:会话问答挑战数据集」(CoQA: Conversational Question Answering Challenge)
tags: 标签(tags):会话问答(conversational-qa)
dataset_info:
特征字段:
- `source`:字符串类型,数据来源标识
- `story`:字符串类型,参考文本段落
- `questions`:字符串序列,会话式问题列表
- `answers`:嵌套序列特征,包含`input_text`(答案文本)、`answer_start`(答案起始索引)、`answer_end`(答案结束索引)三个int32类型子字段
splits: 数据划分:
- 训练集(train):字节数17953365,样本量7199
- 验证集(validation):字节数1223427,样本量500
download_size: 下载总大小:12187487字节
dataset_size: 生成后数据集总大小:19176792字节
configs: 配置项:默认配置(default),数据文件路径:训练集对应`data/train-*`,验证集对应`data/validation-*`
# 「CoQA」数据集卡片
## 目录
- [数据集概述](#dataset-description)
- [数据集摘要](#dataset-summary)
- [支持任务与排行榜](#supported-tasks-and-leaderboards)
- [语言](#languages)
- [数据集结构](#dataset-structure)
- [数据实例](#data-instances)
- [数据字段](#data-fields)
- [数据划分](#data-splits)
- [数据集构建](#dataset-creation)
- [构建初衷](#curation-rationale)
- [源数据](#source-data)
- [标注流程](#annotations)
- [个人与敏感信息](#personal-and-sensitive-information)
- [数据集使用注意事项](#considerations-for-using-the-data)
- [数据集的社会影响](#social-impact-of-dataset)
- [偏见讨论](#discussion-of-biases)
- [其他已知局限性](#other-known-limitations)
- [附加信息](#additional-information)
- [数据集维护者](#dataset-curators)
- [许可证信息](#licensing-information)
- [引用信息](#citation-information)
- [贡献致谢](#contributions)
## 数据集概述
- **官网**:[https://stanfordnlp.github.io/coqa/](https://stanfordnlp.github.io/coqa/)
- **代码仓库**:https://github.com/stanfordnlp/coqa-baselines
- **相关论文**:[《CoQA: A Conversational Question Answering Challenge》](https://arxiv.org/abs/1808.07042)
- **联系方式**:[谷歌群组](https://groups.google.com/forum/#!forum/coqa)、Siva Reddy(邮箱:siva.reddy@mila.quebec)、Danqi Chen(邮箱:danqic@cs.princeton.edu)
- **下载数据集文件大小**:58.09 MB
- **生成后数据集大小**:19.24 MB
- **总磁盘占用**:77.33 MB
### 数据集摘要
CoQA是用于构建会话问答系统的大规模数据集。本数据集包含127,000个带答案的问题,源自7个不同领域文本段落的8,000段对话。所有问题均为会话式问题,答案为自由格式文本,且答案对应的证据段落已在原文中标注。
### 支持任务与排行榜
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 语言
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 数据集结构
### 数据实例
#### 默认配置
- **下载数据集文件大小**:58.09 MB
- **生成后数据集大小**:19.24 MB
- **总磁盘占用**:77.33 MB
以下为训练集的一个数据示例(内容过长已裁剪):
本示例因过长已被截断:
{
"answers": "{"answer_end": [179, 494, 511, 545, 879, 1127, 1128, 94, 150, 412, 1009, 1046, 643, -1, 764, 724, 125, 1384, 881, 910], "answer_...",
"questions": "["When was the Vat formally opened?", "what is the library for?", "for what subjects?", "and?", "what was started in 2014?", "ho...",
"source": "wikipedia",
"story": ""The Vatican Apostolic Library (), more commonly called the Vatican Library or simply the Vat, is the library of the Holy See, l..."
}
### 数据字段
所有数据划分的字段格式保持一致:
#### 默认配置
- `source`:字符串类型特征,表示数据来源。
- `story`:字符串类型特征,即参考文本段落。
- `questions`:字符串列表类型特征,为会话式问题序列。
- `answers`:字典类型特征,包含以下子字段:
- `input_text`:字符串类型特征,即答案文本内容。
- `answer_start`:int32类型特征,即答案在参考文本中的起始索引位置。
- `answer_end`:int32类型特征,即答案在参考文本中的结束索引位置。
### 数据划分
| 划分名称 | 训练集样本量 | 验证集样本量 |
|-------|----:|---------:|
| 默认配置 | 7199 | 500 |
## 数据集构建
### 构建初衷
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 源数据
#### 初始数据收集与标准化
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### 源语言生产者是谁?
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 标注流程
#### 标注过程
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### 标注者是谁?
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 个人与敏感信息
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 数据集使用注意事项
### 数据集的社会影响
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 偏见讨论
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 其他已知局限性
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 附加信息
### 数据集维护者
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 许可证信息
CoQA包含7个领域的文本段落,其中5个领域的文本已公开,许可证规则如下:
- 文学作品与维基百科段落采用CC BY-SA 4.0协议共享。
- 儿童故事源自[MCTest](https://www.microsoft.com/en-us/research/publication/mctest-challenge-dataset-open-domain-machine-comprehension-text/)数据集,采用[MSR-LA](https://github.com/mcobzarenco/mctest/blob/master/data/MCTest/LICENSE.pdf)许可证。
- 初高中考试段落源自[RACE](https://arxiv.org/abs/1704.04683)数据集,采用其[自有许可证](http://www.cs.cmu.edu/~glai1/data/race/)。
- 新闻段落源自DeepMind的[CNN/Daily Mail数据集](https://arxiv.org/abs/1506.03340),采用[Apache](https://github.com/deepmind/rc-data/blob/master/LICENSE)许可证。
### 引用信息
bibtex
@article{reddy-etal-2019-coqa,
title = "{C}o{QA}: A Conversational Question Answering Challenge",
author = "Reddy, Siva and
Chen, Danqi and
Manning, Christopher D.",
journal = "Transactions of the Association for Computational Linguistics",
volume = "7",
year = "2019",
address = "Cambridge, MA",
publisher = "MIT Press",
url = "https://aclanthology.org/Q19-1016",
doi = "10.1162/tacl_a_00266",
pages = "249--266",
}
### 贡献致谢
感谢[@patrickvonplaten](https://github.com/patrickvonplaten)、[@lewtun](https://github.com/lewtun)、[@thomwolf](https://github.com/thomwolf)、[@mariamabarham](https://github.com/mariamabarham)、[@ojasaar](https://github.com/ojasaar)、[@lhoestq](https://github.com/lhoestq)为本数据集的收录工作提供贡献。
提供机构:
stanfordnlp
原始信息汇总
数据集概述
数据集基本信息
- 名称: CoQA: Conversational Question Answering Challenge
- 语言: 英语 (en)
- 许可证: 其他
- 多语言性: 单语
- 大小: 1K<n<10K
- 任务类别: 问答 (question-answering)
- 任务ID: extractive-qa
- 标签: 对话式问答 (conversational-qa)
数据集结构
数据字段
- source: 字符串类型
- story: 字符串类型
- questions: 字符串序列
- answers: 字典类型,包含以下字段:
input_text: 字符串类型answer_start: 整数类型 (int32)answer_end: 整数类型 (int32)
数据分割
- 训练集: 7199个样本
- 验证集: 500个样本
数据集创建
源数据
- 扩展源:
- race
- cnn_dailymail
- wikipedia
- other
许可证信息
- 文学和维基百科段落: CC BY-SA 4.0
- 儿童故事: MSR-LA
- 中学/高中考试段落: 自定义
- 新闻段落: Apache
引用信息
@article{reddy-etal-2019-coqa, title = "{C}o{QA}: A Conversational Question Answering Challenge", author = "Reddy, Siva and Chen, Danqi and Manning, Christopher D.", journal = "Transactions of the Association for Computational Linguistics", volume = "7", year = "2019", address = "Cambridge, MA", publisher = "MIT Press", url = "https://aclanthology.org/Q19-1016", doi = "10.1162/tacl_a_00266", pages = "249--266", }
搜集汇总
数据集介绍
构建方式
CoQA数据集的构建基于大规模的对话式问题回答场景,其核心在于模拟真实对话中的问答互动。数据集由斯坦福大学自然语言处理团队采用众包的方式,从七个不同领域的文本篇章中收集并构建而成,涵盖了文学、新闻、儿童故事、考试文本等多个方面。数据集中的每个问题都与前一个问题存在上下文关联,形成了一个连贯的对话流,同时,每个问题的答案都是自由形式的文本,并在原文中标注了对应的证据位置。
特点
CoQA数据集的特点在于其对话性和上下文相关性。它包含了127k个问题和答案,这些问题和答案是来自8k个对话的互动。数据集的问题设计贴近实际对话场景,答案不仅包括提取式回答,还包括了自由形式的回答,这使得数据集在构建对话式问答系统时具有更高的实用价值。此外,数据集还提供了详细的标注信息,包括答案在文本中的起始和结束位置,有助于精确评估模型的性能。
使用方法
使用CoQA数据集时,用户可以根据自己的需求选择训练集或验证集。数据集以JSON格式存储,其中包含了问题的序列、答案的文本及其在原文中的位置信息。用户可以通过解析JSON文件来加载和预处理数据,进而将其用于训练或评估对话式问答模型。为了方便使用,HuggingFace提供了相应的数据集处理工具,用户可以利用这些工具快速集成数据集到自己的模型训练流程中。
背景与挑战
背景概述
CoQA(Conversational Question Answering)数据集是由斯坦福大学自然语言处理团队于2019年创建的,主要研究人员包括Siva Reddy和Danqi Chen等。该数据集旨在推动会话式问题回答系统的研究,包含127k个问题及其答案,源自8k个关于七个不同领域文本段落的对话。这些问题具有对话性质,答案为自由文本形式,并在段落中标注了相应的证据。CoQA数据集的构建为相关领域提供了宝贵的研究资源,对会话式问答技术的发展起到了积极的推动作用。
当前挑战
该数据集在构建过程中遇到的挑战主要包括:1)如何确保问题与答案的连贯性和相关性,以符合实际对话场景的需求;2)如何处理和标注大量文本数据,保证数据质量;3)数据集涵盖了多个领域,如何平衡不同领域的数据分布,提高模型的泛化能力。在所解决的领域问题上,CoQA数据集面临的挑战包括:如何设计有效的模型结构来处理对话中的上下文信息,以及如何准确识别并定位答案在文本中的位置。
常用场景
经典使用场景
在自然语言处理领域,CoQA数据集被广泛应用于构建对话式问题回答系统。该数据集提供了一个对话环境,其中的问题与答案相互关联,形成了一个连贯的对话流程,这有助于模型理解上下文信息,从而提高问题回答的准确性。
解决学术问题
CoQA数据集解决了传统问题回答系统中忽略上下文信息的问题。它通过提供连续对话的形式,使研究者能够专注于开发能够理解对话上下文的模型,这对于提升机器理解自然语言的能力具有重要意义。此外,该数据集的多样性和规模也为研究如何处理多领域知识提供了丰富的资源。
衍生相关工作
基于CoQA数据集,研究者们开展了一系列相关工作,包括但不限于对话式问答的模型架构设计、上下文理解算法改进、以及对话系统的评估指标研究等。这些工作进一步推动了对话式人工智能技术的发展。
以上内容由遇见数据集搜集并总结生成


