FEA Instruction Dataset
收藏arXiv2025-05-20 更新2025-05-21 收录
下载链接:
https://github.com/953206211/FEALLM
下载链接
链接失效反馈官方服务:
资源简介:
FEA Instruction Dataset是一个新型的面部情绪分析指令数据集,旨在通过提供准确且对齐的面部情绪(FE)和面部动作单元(AU)描述以及它们之间的因果推理关系,来提高多模态大型语言模型在面部情绪分析任务中的表现。该数据集基于Aff-Wild2数据集构建,包含16,227张面部图像,其中14,892张用于训练,1,335张用于评估。数据集包含了三种类型的指令:情绪摘要、面部动作描述和情绪推理描述,以便模型能够更深入地理解和感知面部情绪。FEABench是一个新的基准测试,旨在同时评估模型在FER和AUD任务中的表现,以促进模型在两个任务上的协同发展。FEALLM是一个专门为FEA设计的多模态大型语言模型架构,它通过提取面部图像的局部特征并与视觉编码器的低级特征相结合,来增强对局部面部细节的关注,从而提高模型在FEA任务中的表现。
FEA Instruction Dataset is a novel instruction dataset for facial emotion analysis, aiming to improve the performance of multimodal large language models on facial emotion analysis tasks by providing accurately aligned descriptions of facial emotion (FE) and facial action unit (AU), as well as the causal inference relationships between them.
This dataset is constructed based on the Aff-Wild2 dataset, containing 16,227 facial images, among which 14,892 are used for training and 1,335 for evaluation.
The dataset includes three types of instructions: emotion summary, facial action description, and emotion inference description, enabling the model to gain a deeper understanding and perception of facial emotions.
FEABench is a new benchmark designed to simultaneously evaluate model performance on FER and AUD tasks, so as to promote the coordinated development of models on both tasks.
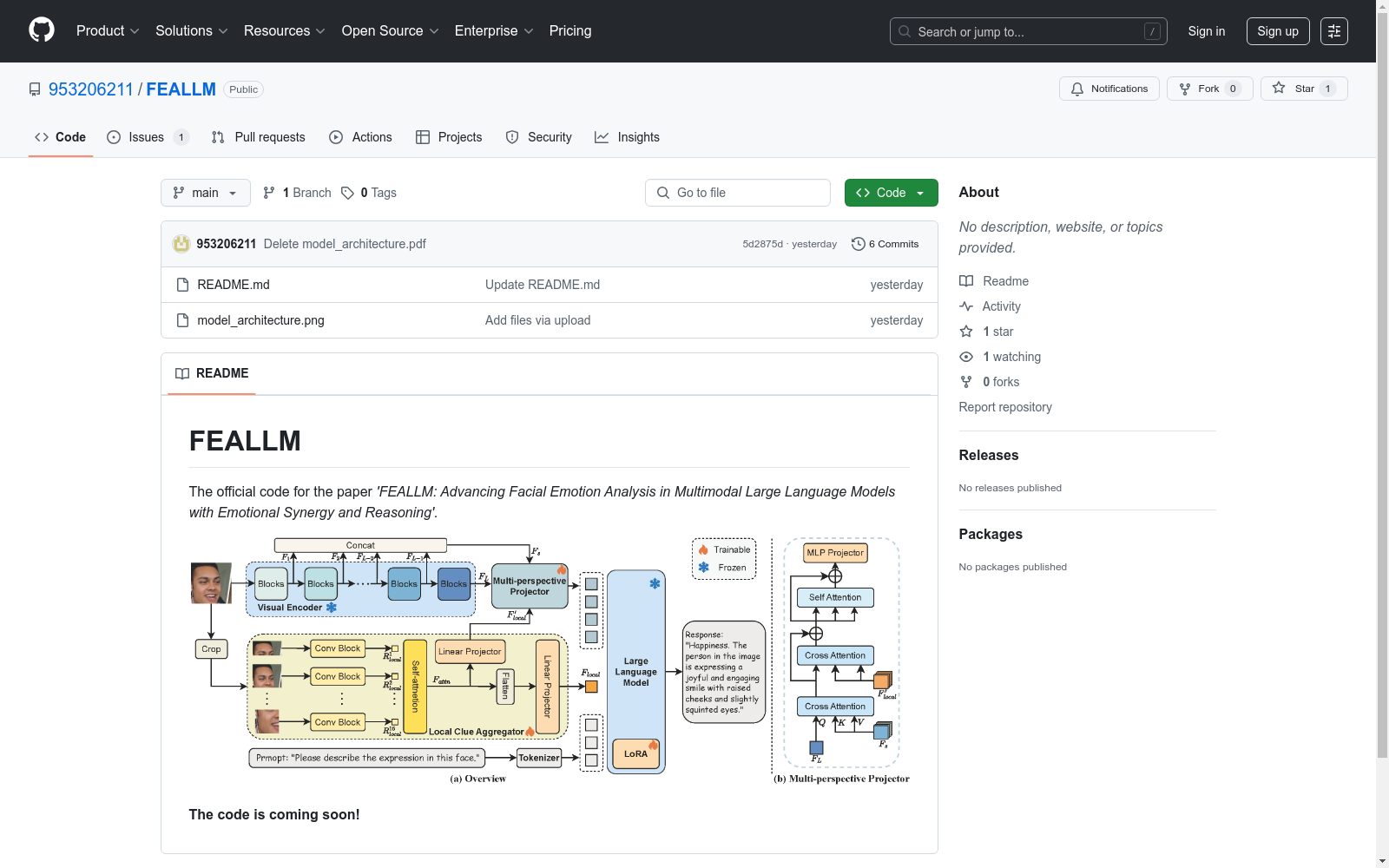
FEALLM is a multimodal large language model architecture specially designed for FEA. It enhances the attention to local facial details by extracting local features of facial images and combining them with the low-level features of visual encoders, thereby improving the model's performance on FEA tasks.
提供机构:
天津大学, 香港科技大学(广州), 拉彭兰塔-拉赫蒂工业大学 LUT, 大湾区大学, 东南大学, 西安交通大学
创建时间:
2025-05-20
原始信息汇总
FEALLM 数据集概述
基本信息
- 数据集名称:FEALLM
- 相关论文:FEALLM: Advancing Facial Emotion Analysis in Multimodal Large Language Models with Emotional Synergy and Reasoning
- 代码状态:即将发布(The code is coming soon!)
研究内容
- 研究领域:多模态大语言模型中的面部情绪分析
- 关键技术:情感协同与推理(Emotional Synergy and Reasoning)
模型架构
- 架构图示:包含模型架构图(model_architecture.png),展示了FEALLM的整体设计。
备注
- 当前代码尚未发布,请关注更新。
搜集汇总
数据集介绍
构建方式
FEA Instruction Dataset的构建基于Aff-Wild2数据集,该数据集包含了丰富的面部表情(FE)和动作单元(AU)标注。研究人员从中选取了16,227张面部图像,确保每张图像均包含FE和AU标注。为了提升数据质量,标注过程由多位领域专家验证,确保了标注的可靠性。此外,借助GPT-4o生成结构化文本描述,包括情感摘要、面部运动描述和情感推理描述,并通过验证确保与原始标注的一致性。最终,数据集分为训练集(14,892张图像)和评估集(1,335张图像),以评估模型的泛化能力。
特点
FEA Instruction Dataset的特点在于其多层次的标注和推理能力。它不仅提供了精确对齐的FE和AU描述,还创新性地引入了情感推理指令,建立了从AU到FE的因果关系。这种设计使得模型能够理解不同面部肌肉运动如何影响特定情感状态,从而提升情感分析的深度和可解释性。此外,数据集的多样性和广泛覆盖(包括七种基本情感类别和12种AU)确保了其在复杂真实场景中的适用性。
使用方法
FEA Instruction Dataset的使用方法主要包括训练和评估两个阶段。在训练阶段,研究人员可以利用该数据集对多模态大语言模型(MLLM)进行指令微调,使其学习FE和AU的表示及其内在关联。评估阶段则通过FEABench基准测试,同时考察模型在FER和AUD任务上的表现。具体操作包括使用随机采样的指令模板(如“请描述这张脸的表情”或“请描述这张脸的动作单元”)生成响应,并通过准确率(FER)和F1分数(AUD)量化模型性能。此外,该数据集还支持零样本评估,以验证模型在未见数据上的泛化能力。
背景与挑战
背景概述
FEA Instruction Dataset是由天津大学、香港科技大学(广州)等机构的研究团队于2025年提出的,旨在推动多模态大语言模型(MLLMs)在面部情感分析(Facial Emotion Analysis, FEA)领域的应用。该数据集基于Aff-Wild2数据集构建,包含16,227张带有面部表情(FE)和动作单元(AU)标注的面部图像,并通过GPT-4o生成情感摘要、面部运动描述和情感推理描述三类指令数据。FEA Instruction Dataset首次实现了FE与AU描述的精确对齐,并建立了两者之间的因果推理关系,显著提升了模型在情感感知和推理任务中的表现。该数据集的推出为情感计算领域提供了新的研究工具,推动了MLLMs在复杂情感分析任务中的应用。
当前挑战
FEA Instruction Dataset面临的挑战主要包括两方面:领域问题的挑战和构建过程的挑战。在领域问题方面,传统方法在面部情感分析中存在可解释性差、泛化能力有限的问题,而现有MLLMs由于缺乏专门的训练语料,难以捕捉面部表情与动作单元之间的复杂关系。在构建过程中,数据标注的可靠性是关键挑战,以往依赖工具或GPT生成缺失标签的方法可能导致噪声标签,影响数据质量。此外,如何有效对齐FE和AU描述,并建立两者之间的推理关系,也是数据集构建中的难点。这些挑战需要通过精确的专家标注、创新的指令生成方法以及多模态特征融合技术来解决。
常用场景
经典使用场景
FEA Instruction Dataset 在面部情绪分析(Facial Emotion Analysis, FEA)领域中被广泛用于训练和评估多模态大语言模型(Multimodal Large Language Models, MLLMs)。该数据集通过提供精确对齐的面部表情(Facial Expressions, FEs)和动作单元(Action Units, AUs)描述,并建立两者之间的因果关系推理关系,显著提升了模型在情绪感知和推理任务中的表现。经典使用场景包括面部表情识别(FER)和动作单元检测(AUD),这些任务在心理学研究、人机交互和心理健康评估等领域具有重要应用价值。
解决学术问题
FEA Instruction Dataset 解决了传统面部情绪分析方法在可解释性、泛化能力和推理能力方面的局限性。通过提供多层次的标注数据和推理指令,该数据集帮助模型理解面部肌肉运动与情绪状态之间的内在联系,从而提升了模型在复杂情绪分析任务中的表现。此外,该数据集还推动了多模态大语言模型在情绪计算领域的应用,填补了现有研究中缺乏专门情绪分析数据集的空白。
衍生相关工作
FEA Instruction Dataset 催生了一系列相关研究工作,包括 FEALLM 模型的提出和 FEABench 基准的建立。这些工作进一步推动了多模态大语言模型在情绪分析领域的发展。例如,Emo-LLaMA 和 Emotion-LLaMA 等研究基于该数据集的标注范式,探索了指令调优在情绪识别中的应用。此外,该数据集还启发了对浅层特征和局部特征在情绪分析中作用的研究,为后续模型架构设计提供了重要参考。
以上内容由遇见数据集搜集并总结生成


