Health_QA_English
收藏Hugging Face2026-04-23 更新2026-04-24 收录
下载链接:
https://huggingface.co/datasets/Kakyoin03/Health_QA_English
下载链接
链接失效反馈官方服务:
资源简介:
Health QA English数据集是一个高度结构化的医学问答数据集,包含经过提取、清理和标准化的英文医学问答对。该数据集是BRAIN HEALTH (HELIX-FT)项目的基准数据集,旨在微调大型语言模型(LLMs)以充当医疗助手。数据集包含18,876个高质量的医学问答对,每个条目包含以下字段:问题(question)、结构化问题(context_question)、答案(answer)、专业领域(speciality)、紧急程度(urgency)、提取的临床实体(entities)和问题主题标题(article_title)。数据集经过严格的评估,包括基于LLM的RAG Triad指标(如上下文相关性、忠实性、专业性和答案相关性)和经典NLP指标(如词汇多样性、重复率、语义相似度等)。
The Health QA English dataset is a highly structured medical question-answering dataset containing extracted, cleaned, and standardized English medical question-answer pairs. This dataset serves as a benchmark for the BRAIN HEALTH (HELIX-FT) project, aiming to fine-tune large language models (LLMs) to act as medical assistants. The dataset includes 18,876 high-quality medical question-answer pairs, with each entry containing the following fields: question, context_question, answer, speciality, urgency, entities, and article_title. The dataset has undergone rigorous evaluation, including LLM-based RAG Triad metrics (such as context relevance, faithfulness, professionalism, and answer relevance) and classical NLP metrics (such as lexical diversity, repetition rate, semantic similarity, etc.).
创建时间:
2026-04-23
原始信息汇总
Health QA English 数据集概述
基本信息
- 数据集名称: Health QA English
- 语言: 英语
- 许可协议: MIT
- 数据集大小: 10,000 < n < 100,000(实际包含 18,876 条高质量医疗问答对)
- 任务类型: 问答(Question-Answering)、文本生成(Text Generation)
- 数据集链接: https://huggingface.co/datasets/Kakyoin03/Health_QA_English
数据集背景
该数据集是 BRAIN HEALTH (HELIX-FT) 项目的基线数据集,旨在用于微调大型语言模型(LLMs)以充当医疗助手。数据经过提取、清洗和标准化处理,结构高度规范化。
数据结构
每条数据包含以下字段:
- question: 患者提出的原始问题
- context_question: 结构化、摘要化的问题版本,保留症状信息
- answer: 医疗专业人员的回答
- speciality: 医学领域(如心脏病学、皮肤科)
- urgency: 分诊级别(Faible、Moyen、Fort)
- entities: 提取的临床实体(年龄、症状、疾病、药物)
- article_title: 问题上下文的主题标题
评估与验证
数据集采用 LLM-as-a-judge 评估框架,结合 Grok-4.20-Reasoning(xAI)与经典 NLP 指标进行严格评估。
1. RAG Triad 指标(Grok-4.20 评估)
| 指标 | 得分 | 说明 |
|---|---|---|
| 上下文相关性 | 4.45 / 5.0 | 捕捉患者症状的准确性高 |
| 忠实性 | 4.35 / 5.0 | 事实依据优秀 |
| 专业性 | 4.05 / 5.0 | 医学语气正式、专业 |
| 答案相关性 | 3.80 / 5.0 | 临床回答目标明确、严格 |
2. 词汇与数据多样性指标
- 类型-符号比率(TTR):问题部分为 0.0283(词汇多样性较低,体现标准医疗形式化)
- 完全重复率:18.04%(原始网络爬取数据的典型特征)
- 近似重复率(Jaccard > 80%):0.0006%
3. 自动 NLP 管道评分
- 语义相似度(余弦相似度):0.5349
- BERTScore(F1):0.8505
- 安全评分(危险关键词检测):99.2%
评估代码
数据集使用 llm_as_a_judge.py 脚本,基于 RAG Triad 框架进行指标提取,调用 Grok-4.20-reasoning 模型对问答样本进行评分。
搜集汇总
数据集介绍
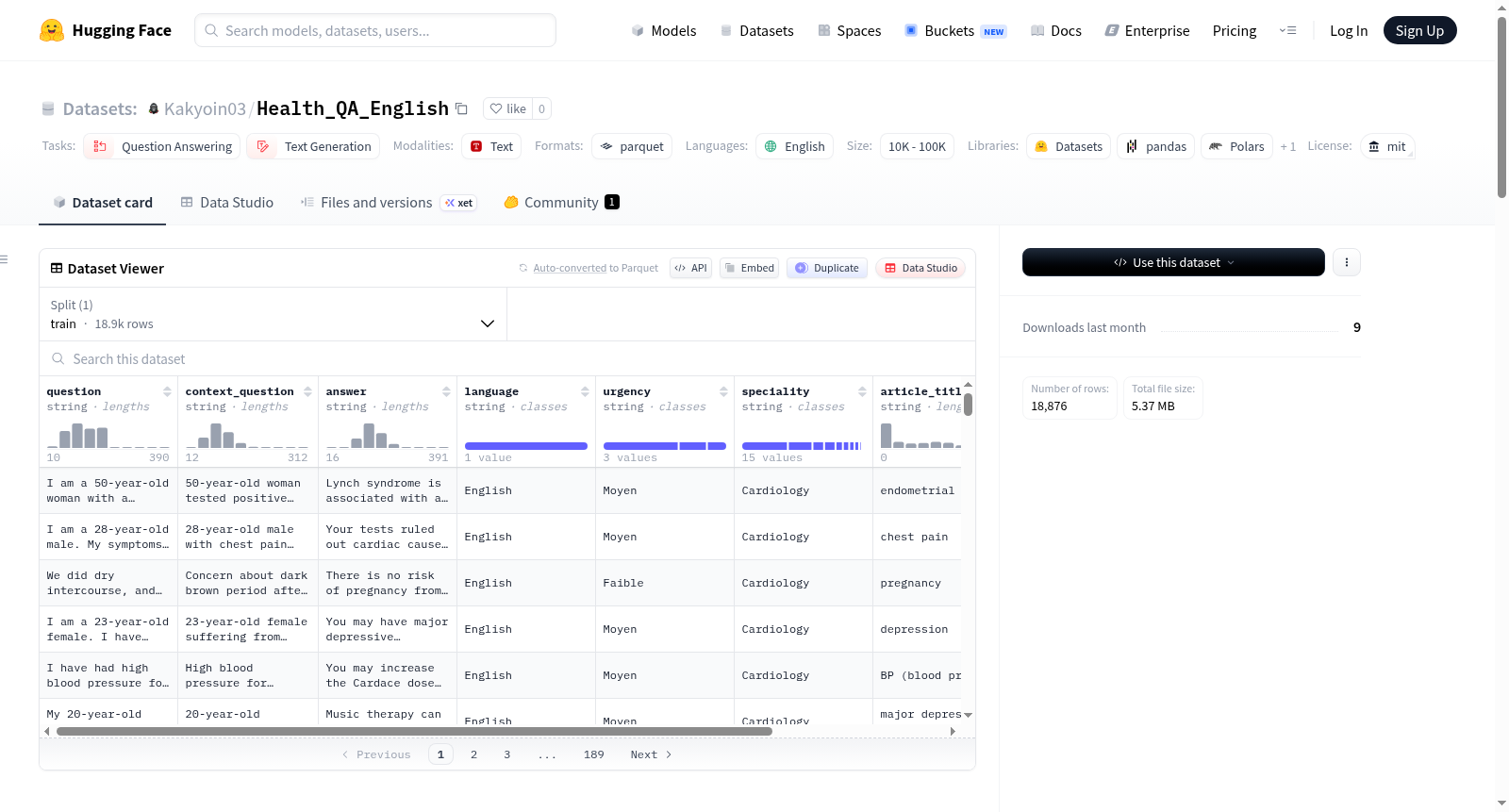
构建方式
Health_QA_English数据集源自对互联网上高度结构化的医疗问答数据的精细提取、清洗与标准化处理,最终汇聚成包含18,876条高质量英文医患问答对的语料库。每条记录均涵盖原始患者提问、经结构化处理并保留症状的上下文问题、专业医师的应答、所属医学专科(如心脏病学、皮肤科)、分诊紧急程度、提取的临床实体(如年龄、症状、疾病与药物)以及问题主题标题等字段,构建过程凸显了数据纯净度与临床实用性。
特点
本数据集在构建过程中引入了基于Grok-4.20-Reasoning模型与经典NLP指标相结合的严苛评估框架,展现出卓越的上下文相关性(4.45/5.0)、事实忠诚度(4.35/5.0)与专业规范性(4.05/5.0)。其语义相似度达0.5349,BERTScore F1值为0.8505,而安全性评分高达99.2%,极低近似重复率(Jaccard>80%仅为0.0006%)确保了数据多样性与临床应答的精准靶向。
使用方法
该数据集专为大语言模型在医疗辅助场景下的微调而设计,可直接用于问答与文本生成任务。使用者可通过HuggingFace平台加载,利用其结构化的question、context_question、answer等字段构建训练样本。随附的评估脚本llm_as_a_judge.py提供了一套基于RAG Triad框架的自动化质检流程,支持通过Grok-4.20等模型对上下文相关性、忠实度与专业性进行量化评分,便于开发者衡量模型微调效果。
背景与挑战
背景概述
在人工智能与医疗健康交叉领域中,大规模、高质量的医学问答数据集是构建可靠医疗大语言模型(LLM)的基础资源。Health_QA_English数据集于近期由BRAIN HEALTH(HELIX-FT)项目团队创建,旨在微调LLM以充当智能医疗助手。该数据集精心收录了18,876对结构化医学问答,涵盖心内科、皮肤科等多个专科领域,并创新性地融入了分诊等级、临床实体抽取等元信息,为提升医疗对话系统的专业性和安全性提供了标准化基准。其研究核心聚焦于解决非结构化医疗问答在事实一致性、语境相关性及专业语气上的瓶颈,对推动LLM在临床辅助决策中的应用具有重要价值。
当前挑战
该数据集面临的核心挑战包括:1)领域问题的复杂性——医疗问答要求极高的事实准确性(Faithfulness得分4.35/5.0)和临床相关性(Answer Relevance仅3.80/5.0),模型需精准区分症状描述与诊疗建议,避免误导性输出;2)数据构建过程的多样性难题——原始网络爬取数据存在低词汇多样性(问题TTR=0.0283)和18.04%的精确重复,需严格的去重与标准化处理;3)安全性与伦理性挑战——尽管危险关键词检测安全分达99.2%,但医学场景下任何微小偏差都可能导致严重风险,使得评估框架需融合LLM-as-a-Judge与经典NLP指标以保障可靠性。
常用场景
经典使用场景
Health_QA_English数据集作为BRAIN HEALTH(HELIX-FT)项目的基准语料库,经典应用场景聚焦于医疗领域大语言模型的指令微调。该数据集合含18,876条高保真医学问答对,每条记录不仅包含原始医患问答,还精心设计了结构化上下文问题、临床实体标签(如年龄、症状、疾病、药物)及分诊紧急程度,为模型提供了多维度、标准化的训练信号。研究者常利用该数据集增强LLM对医疗谘询的理解能力,使其能够从非结构化的患者叙述中精准提取关键临床信息,并生成专业、安全、忠于医学事实的回应。这一基准场景奠定了将通用LLM转化为可靠医学助手的基础路径。
衍生相关工作
该数据集衍生了一系列推动医疗NLP发展的经典工作。首要影响在于推动了基于RAG(检索增强生成)框架的医学问答系统评测基准,研究者常复用该数据集的三元组结构(原始问题、结构化上下文、专业答案)构建和验证检索排序器的性能。其次,数据集中细致的实体标注(entities字段)被用于训练临床命名实体识别模型,支撑从患者主诉中自动化抽取时序症状、用药史等关键信息。此外,受该数据集“紧急度”标签启发,衍生出医疗对话分诊优先级分类任务,催生了多篇关于时序注意力机制与对话紧急度预测的研究。这些工作环环相扣,共同织就了从数据到模型再到临床落地的完整研究链条。
数据集最近研究
最新研究方向
在智能医疗与大型语言模型交叉融合的前沿疆域,Health_QA_English数据集正成为推动医学问答系统精准化与专业化的关键基石。作为BRAIN HEALTH(HELIX-FT)项目的基准数据集,它通过精细结构化处理,融合了临床实体提取、专科分类与紧急度分级等高级特征,为微调具备医学助理能力的LLM提供了高质量训练素材。当前研究热点聚焦于利用该数据集优化模型的上下文相关性与忠实度,例如借助Grok-4.20等前沿推理模型的评估框架,以提升AI在临床场景下的专业应答能力。这一探索不仅呼应了全球对可信赖医疗AI的迫切需求,更可能重塑数字健康生态,赋予机器理解症状、分诊急慢、辅助决策的变革性力量,其意义在于为人类医学知识的高效传播与智能诊疗的普惠化铺就道路。
以上内容由遇见数据集搜集并总结生成


