PeterJinGo/GRBench
收藏Hugging Face2024-04-13 更新2024-04-19 收录
下载链接:
https://hf-mirror.com/datasets/PeterJinGo/GRBench
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
task_categories:
- question-answering
- text2text-generation
language:
- en
tags:
- chemistry
- biology
- legal
- medical
configs:
- config_name: amazon
data_files:
- split: test
path: "amazon.json"
- config_name: medicine
data_files:
- split: test
path: "medicine.json"
- config_name: physics
data_files:
- split: test
path: "physics.json"
- config_name: biology
data_files:
- split: test
path: "biology.json"
- config_name: chemistry
data_files:
- split: test
path: "chemistry.json"
- config_name: computer_science
data_files:
- split: test
path: "computer_science.json"
- config_name: healthcare
data_files:
- split: test
path: "healthcare.json"
- config_name: legal
data_files:
- split: test
path: "legal.json"
- config_name: literature
data_files:
- split: test
path: "literature.json"
- config_name: material_science
data_files:
- split: test
path: "material_science.json"
---
# GRBench
<!-- Provide a quick summary of the dataset. -->
GRBench is a comprehensive benchmark dataset to support the development of methodology and facilitate the evaluation of the proposed models for Augmenting Large Language Models with External Textual Graphs.
<!--<p align="center">
<img src="https://github.com/PeterGriffinJin/Graph-CoT/blob/main/fig/intro.png" width="400px"/>
</p>-->
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
GRBench includes 10 real-world graphs that can serve as external knowledge sources for LLMs from five domains including academic, e-commerce, literature, healthcare, and legal domains. Each sample in GRBench consists of a manually designed question and an answer, which can be directly answered by referring to the graphs or retrieving the information from the graphs as context. To make the dataset comprehensive, we include samples of different difficulty levels: easy questions (which can be answered with single-hop reasoning on graphs), medium questions (which necessitate multi-hop reasoning on graphs), and hard questions (which call for inductive reasoning with information on graphs as context).
<!--<p align="center">
<img src="https://github.com/PeterGriffinJin/Graph-CoT/blob/main/fig/data.png" width="300px"/>
</p>-->
- **Curated by:** Bowen Jin (https://peterjin.me/), Chulin Xie (https://alphapav.github.io/), Jiawei Zhang (https://javyduck.github.io/) and Kashob Kumar Roy (https://www.linkedin.com/in/forkkr/)
- **Language(s) (NLP):** English
- **License:** apache-2.0
### Dataset Sources
<!-- Provide the basic links for the dataset. -->
- **Repository:** https://github.com/PeterGriffinJin/Graph-CoT
- **Paper:** https://arxiv.org/pdf/2404.07103.pdf
- **Graph files:** https://drive.google.com/drive/folders/1DJIgRZ3G-TOf7h0-Xub5_sE4slBUEqy9
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
You can access the graph environment data for each domain here: https://drive.google.com/drive/folders/1DJIgRZ3G-TOf7h0-Xub5_sE4slBUEqy9.
Then download the question answering data for each domain:
```
from datasets import load_dataset
domain = 'amazon' # can be selected from [amazon, medicine, physics, biology, chemistry, computer_science, healthcare, legal, literature, material_science]
dataset = load_dataset("PeterJinGo/GRBench", data_files=f'{domain}.json')
```
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
Information on how the graph file looks can be found here: https://github.com/PeterGriffinJin/Graph-CoT/tree/main/data.
## Dataset Creation
More details of how the dataset is constructed can be found in Section 3 of this paper (https://arxiv.org/pdf/2404.07103.pdf).
The raw graph data sources can be found here: https://github.com/PeterGriffinJin/Graph-CoT/tree/main/data/raw_data.
## Citation
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
@article{jin2024graph,
title={Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs},
author={Jin, Bowen and Xie, Chulin and Zhang, Jiawei and Roy, Kashob Kumar and Zhang, Yu and Wang, Suhang and Meng, Yu and Han, Jiawei},
journal={arXiv preprint arXiv:2404.07103},
year={2024}
}
## Dataset Card Authors
Bowen Jin
## Dataset Card Contact
bowenj4@illinois.edu
许可证:Apache-2.0
任务类别:
- 问答
- 文本到文本生成
语言:
- 英语
标签:
- 化学
- 生物学
- 法学
- 医学
配置项:
- 配置名称:amazon
数据文件:
- 拆分集:测试集
路径:"amazon.json"
- 配置名称:medicine
数据文件:
- 拆分集:测试集
路径:"medicine.json"
- 配置名称:physics
数据文件:
- 拆分集:测试集
路径:"physics.json"
- 配置名称:biology
数据文件:
- 拆分集:测试集
路径:"biology.json"
- 配置名称:chemistry
数据文件:
- 拆分集:测试集
路径:"chemistry.json"
- 配置名称:computer_science
数据文件:
- 拆分集:测试集
路径:"computer_science.json"
- 配置名称:healthcare
数据文件:
- 拆分集:测试集
路径:"healthcare.json"
- 配置名称:legal
数据文件:
- 拆分集:测试集
路径:"legal.json"
- 配置名称:literature
数据文件:
- 拆分集:测试集
路径:"literature.json"
- 配置名称:material_science
数据文件:
- 拆分集:测试集
路径:"material_science.json"
# GRBench
<!-- 提供该数据集的简要概述。 -->
GRBench是一款综合性基准数据集,旨在支撑相关方法论的研发,并助力评估为大语言模型(Large Language Model)接入外部文本图谱所提出的各类模型。
<!--<p align="center">
<img src="https://github.com/PeterGriffinJin/Graph-CoT/blob/main/fig/intro.png" width="400px"/>
</p>-->
## 数据集详情
### 数据集描述
<!-- 提供该数据集更详细的说明。 -->
GRBench包含10个真实世界图谱,可作为来自学术、电商、文学、医疗、法律五大领域的大语言模型的外部知识来源。数据集中的每个样本均包含人工设计的问题与答案,可通过直接参考图谱或以图谱信息作为上下文进行检索后作答。为保障数据集的全面性,我们纳入了不同难度等级的样本:简单问题(仅需对图谱进行单跳推理即可作答)、中等难度问题(需对图谱进行多跳推理)以及困难问题(需要以图谱信息为上下文开展归纳推理)。
<!--<p align="center">
<img src="https://github.com/PeterGriffinJin/Graph-CoT/blob/main/fig/data.png" width="300px"/>
</p>-->
- **整理者:** Bowen Jin(https://peterjin.me/)、Chulin Xie(https://alphapav.github.io/)、Jiawei Zhang(https://javyduck.github.io/)以及Kashob Kumar Roy(https://www.linkedin.com/in/forkkr/)
- **自然语言处理语言:** 英语
- **许可证:** Apache-2.0
### 数据集来源
<!-- 提供该数据集的基础链接。 -->
- **代码仓库:** https://github.com/PeterGriffinJin/Graph-CoT
- **论文:** https://arxiv.org/pdf/2404.07103.pdf
- **图谱文件:** https://drive.google.com/drive/folders/1DJIgRZ3G-TOf7h0-Xub5_sE4slBUEqy9
## 数据集用途
<!-- 阐述该数据集的预期使用场景相关问题。 -->
### 直接使用场景
<!-- 此部分描述该数据集的适用用例。 -->
你可通过以下链接获取各领域的图谱环境数据:https://drive.google.com/drive/folders/1DJIgRZ3G-TOf7h0-Xub5_sE4slBUEqy9。随后下载各领域的问答数据:
from datasets import load_dataset
domain = 'amazon' # 可从 [amazon, medicine, physics, biology, chemistry, computer_science, healthcare, legal, literature, material_science] 中选择
dataset = load_dataset("PeterJinGo/GRBench", data_files=f'{domain}.json')
## 数据集结构
<!-- 此部分提供数据集字段的描述,以及关于数据集结构的额外信息,例如拆分集的创建标准、数据点之间的关系等。 -->
关于图谱文件的格式详情,可参阅:https://github.com/PeterGriffinJin/Graph-CoT/tree/main/data。
## 数据集构建
更多关于该数据集构建方式的细节可参阅该论文的第3节(https://arxiv.org/pdf/2404.07103.pdf)。
原始图谱数据来源可参阅:https://github.com/PeterGriffinJin/Graph-CoT/tree/main/data/raw_data。
## 引用
<!-- 如果有介绍该数据集的论文或博客文章,应在此处提供其APA和Bibtex格式的引用信息。 -->
**BibTeX:**
@article{jin2024graph,
title={Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs},
author={Jin, Bowen and Xie, Chulin and Zhang, Jiawei and Roy, Kashob Kumar and Zhang, Yu and Wang, Suhang and Meng, Yu and Han, Jiawei},
journal={arXiv preprint arXiv:2404.07103},
year={2024}
}
## 数据集卡片作者
Bowen Jin
## 数据集卡片联系方式
bowenj4@illinois.edu
提供机构:
PeterJinGo
原始信息汇总
数据集概述
数据集名称: GRBench
数据集描述: GRBench是一个综合基准数据集,旨在支持大型语言模型与外部文本图结合的方法开发和模型评估。该数据集包含10个真实世界的图,涵盖学术、电商、文学、医疗和法律五个领域。每个样本包括一个手工设计的问题和一个答案,这些问题可以直接通过图或从图中检索信息作为上下文来回答。数据集包含不同难度级别的问题,包括简单问题(单跳图推理)、中等问题(多跳图推理)和困难问题(需要图信息作为上下文的归纳推理)。
语言: 英语
许可证: Apache-2.0
数据集配置:
- amazon:测试数据路径为"amazon.json"
- medicine:测试数据路径为"medicine.json"
- physics:测试数据路径为"physics.json"
- biology:测试数据路径为"biology.json"
- chemistry:测试数据路径为"chemistry.json"
- computer_science:测试数据路径为"computer_science.json"
- healthcare:测试数据路径为"healthcare.json"
- legal:测试数据路径为"legal.json"
- literature:测试数据路径为"literature.json"
- material_science:测试数据路径为"material_science.json"
数据集来源:
- 仓库: https://github.com/PeterGriffinJin/Graph-CoT
- 论文: https://arxiv.org/pdf/2404.07103.pdf
- 图文件: https://drive.google.com/drive/folders/1DJIgRZ3G-TOf7h0-Xub5_sE4slBUEqy9
数据集使用:
- 数据集适用于直接使用,用户可以根据需要下载特定领域的问答数据。
数据集结构:
- 图文件的详细信息可在https://github.com/PeterGriffinJin/Graph-CoT/tree/main/data查看。
数据集创建:
- 数据集的构建细节在论文的第3节中描述,原始图数据来源可在https://github.com/PeterGriffinJin/Graph-CoT/tree/main/data/raw_data找到。
引用信息:
- 论文引用信息以BibTeX格式提供。
搜集汇总
数据集介绍
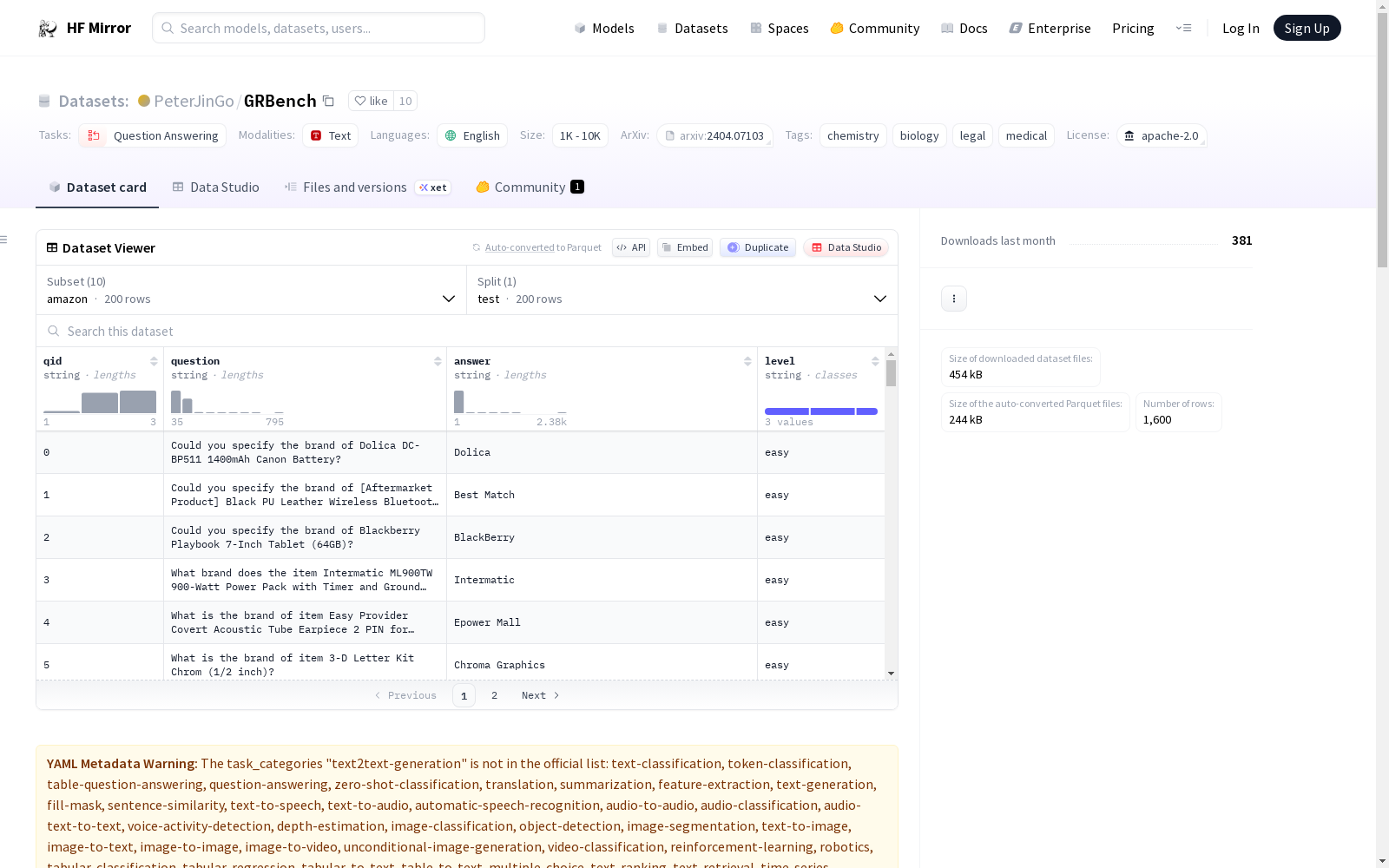
构建方式
在知识图谱与自然语言处理交叉领域,GRBench数据集通过整合来自学术、电子商务、文学、医疗及法律五大领域的十个真实世界图结构数据构建而成。其构建过程涉及从原始图数据中提取结构化知识,并基于此设计涵盖不同推理难度的人工标注问答对。具体而言,每个样本包含一个精心设计的问题及其答案,这些问题被划分为简单、中等和困难三个层次,分别对应单跳推理、多跳推理以及需要归纳推理的复杂场景,从而系统性地评估大语言模型在图知识增强下的表现。
特点
GRBench数据集的核心特点在于其跨领域覆盖的广泛性与问题设计的层次性。该数据集囊括了从亚马逊产品网络到医学、物理、生物学等专业领域的多样化图结构,确保了知识源的丰富性与现实代表性。其问题设置依据推理复杂度进行细致分级,不仅考察模型对图信息的直接检索能力,更强调在多跳路径和归纳语境下的深层推理。这种结构化设计为评估图增强语言模型提供了标准化且具有挑战性的基准环境。
使用方法
使用GRBench时,研究者需首先从指定存储库下载对应领域的图环境数据作为外部知识源。随后,通过Hugging Face的datasets库加载特定领域的问答数据文件,例如选择'amazon'、'medicine'等配置名称。数据加载后,可将图结构信息与问答对结合,构建评估流程,以测试模型能否有效利用图上下文进行准确回答。该数据集适用于端到端的评估框架,支持对图增强推理方法的系统性验证与比较。
背景与挑战
背景概述
在人工智能与自然语言处理领域,大型语言模型(LLMs)的兴起推动了知识增强与推理能力的研究。GRBench数据集由Bowen Jin、Chulin Xie、Jiawei Zhang和Kashob Kumar Roy等研究人员于2024年创建,旨在为增强大型语言模型的外部文本图推理提供基准支持。该数据集覆盖学术、电子商务、文学、医疗和法律等多个领域,包含十个真实世界图结构作为外部知识源,核心研究问题聚焦于如何通过图结构进行单跳、多跳及归纳推理,以提升模型在复杂问答任务中的表现,对推动图增强语言模型的方法论发展与评估具有重要影响力。
当前挑战
GRBench数据集致力于解决图增强语言模型在跨领域问答中的推理挑战,包括如何有效整合外部图知识以支持不同难度级别的问题,如单跳推理、多跳推理及需要上下文归纳的复杂问题。在构建过程中,研究人员面临多重挑战:一是从多样化的真实世界图数据中提取并结构化知识,确保数据覆盖多个领域且具有代表性;二是设计人工标注的问题与答案对,需平衡不同推理难度,同时保证答案可通过图检索或推理直接获得;三是处理图数据的异构性与规模,以构建统一且可访问的基准环境,这对数据集的完整性与实用性提出了较高要求。
常用场景
经典使用场景
在自然语言处理与图结构知识融合的前沿领域,GRBench数据集为评估大型语言模型在图增强推理能力方面提供了标准化的测试平台。该数据集通过涵盖学术、电子商务、文学、医疗和法律等多个领域的真实世界图结构,构建了包含易、中、难三个层次的问答任务,经典使用场景集中于测试模型如何利用外部图知识进行单跳、多跳及归纳推理,从而推动图增强语言模型的方法论发展与性能比较。
实际应用
在实际应用层面,GRBench数据集能够助力开发智能问答系统、专业领域辅助决策工具以及知识图谱增强的对话代理。例如,在医疗领域,模型可借助该数据集中的图结构知识进行疾病诊断推理;在法律领域,则可辅助案例检索与条款解释。这些应用显著提升了人工智能在复杂专业场景下的准确性与可靠性,推动了行业智能化转型。
衍生相关工作
围绕GRBench数据集,已衍生出多项经典研究工作,其中最具代表性的是与其同源的“Graph Chain-of-Thought”方法,该方法提出了在图结构上进行思维链推理的新框架。此外,该数据集还激发了后续研究在图增强语言模型预训练、多跳推理优化以及跨领域知识迁移等方面的探索,为图与自然语言处理的交叉学科发展奠定了坚实基础。
以上内容由遇见数据集搜集并总结生成


