scikit-fingerprints/MoleculeNet_BACE
收藏Hugging Face2024-07-18 更新2024-07-22 收录
下载链接:
https://hf-mirror.com/datasets/scikit-fingerprints/MoleculeNet_BACE
下载链接
链接失效反馈官方服务:
资源简介:
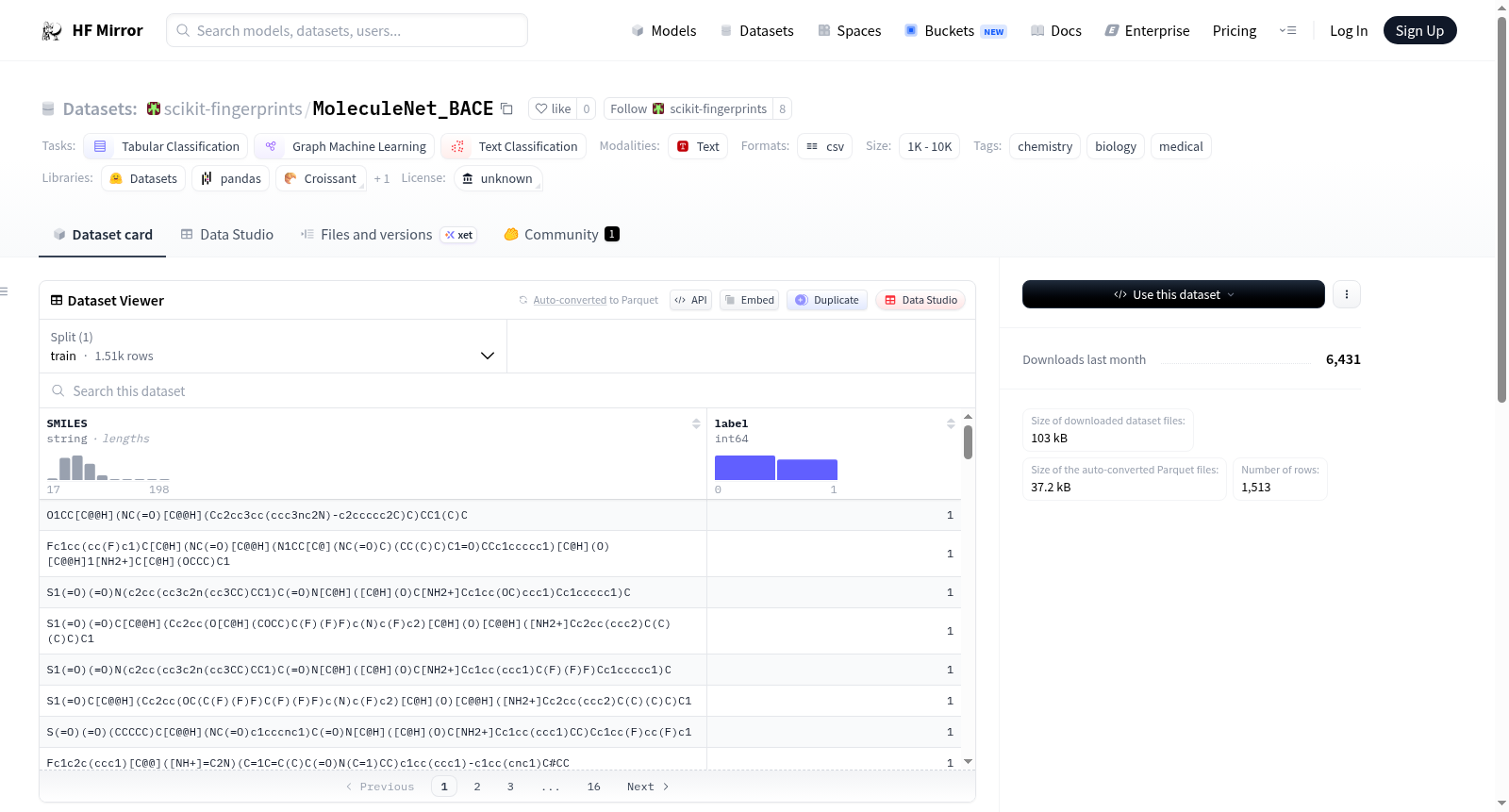
MoleculeNet BACE数据集是MoleculeNet基准的一部分,旨在通过scikit-fingerprints库使用。该数据集的任务是预测一组人类β-分泌酶1(BACE-1)抑制剂的结合结果。数据集包含1513个样本,推荐使用scaffold分割方法,并使用AUROC作为评估指标。
The MoleculeNet BACE dataset is part of the MoleculeNet benchmark and is intended to be used through the scikit-fingerprints library. The task of this dataset is to predict the binding results for a set of inhibitors of human β-secretase 1 (BACE-1). The dataset contains 1513 samples, with a recommended scaffold split and AUROC as the evaluation metric.
提供机构:
scikit-fingerprints
原始信息汇总
MoleculeNet BACE 数据集概述
基本信息
- 数据集名称: MoleculeNet BACE
- 任务类别:
- 表格分类
- 图机器学习
- 文本分类
- 标签:
- 化学
- 生物学
- 医学
- 数据集大小: 1K<n<10K
- 配置:
- 配置名称: default
- 数据文件:
- 分割: train
- 路径: "bace.csv"
任务描述
- 任务: 预测人类β-分泌酶1(BACE-1)抑制剂的结合结果
- 任务类型: 分类
- 总样本数: 1513
- 推荐分割: scaffold
- 推荐评估指标: AUROC
搜集汇总
数据集介绍
构建方式
在计算化学与药物发现领域,MoleculeNet_BACE数据集聚焦于β-分泌酶1(BACE-1)抑制剂的结合活性预测。该数据集源自Subramanian等人的研究,通过实验测定1513个化合物对BACE-1的结合结果,构建了一个二分类任务。数据以CSV格式存储,涵盖分子结构信息与对应的结合标签,并遵循MoleculeNet基准的标准框架,确保其在分子机器学习中的可比性与可复现性。
特点
该数据集的核心特点在于其专一性,专注于BACE-1抑制剂的结合活性分类,为阿尔茨海默病相关药物研究提供关键数据支撑。数据集规模适中,包含1513个样本,推荐使用基于分子骨架(scaffold)的划分方式,以模拟真实药物发现中结构多样性的挑战。评估指标采用AUROC,契合分类任务的性能衡量需求,同时数据集成于scikit-fingerprints库,便于与指纹特征提取工具无缝衔接。
使用方法
使用该数据集时,建议通过scikit-fingerprints库加载数据,以利用其内置的分子指纹转换与预处理功能。研究人员可基于CSV文件中的分子SMILES字符串,结合分类算法构建预测模型,重点探索结构特征与结合活性间的关联。数据集的骨架划分策略要求模型具备良好的泛化能力,适用于评估分子表示学习方法在药物虚拟筛选中的效能。
背景与挑战
背景概述
在计算化学与药物发现领域,分子性质预测是加速新药研发的关键环节。MoleculeNet_BACE数据集作为MoleculeNet基准的重要组成部分,由Zhenqin Wu等研究人员于2018年构建,专注于人类β-分泌酶1(BACE-1)抑制剂的结合活性分类问题。该数据集收录了1513个样本,旨在通过机器学习方法评估化合物与靶点的相互作用,为阿尔茨海默病等神经退行性疾病的治疗提供分子层面的筛选依据,推动了分子机器学习在生物医药领域的应用与发展。
当前挑战
该数据集的核心挑战在于准确预测BACE-1抑制剂的结合活性,这涉及复杂的分子结构与生物活性间的非线性关系,要求模型能有效捕捉化学键、官能团等细微特征。在构建过程中,数据来源于实验测量,需处理分子多样性不足、样本分布不均衡以及支架分割带来的泛化性难题,同时确保数据质量与一致性,以支持稳健的机器学习模型训练与评估。
常用场景
经典使用场景
在计算化学与药物发现领域,MoleculeNet_BACE数据集作为分子机器学习的重要基准,其经典应用场景聚焦于β-分泌酶1(BACE-1)抑制剂的结合活性预测。研究者常利用该数据集构建分类模型,通过分子指纹或图神经网络等表征方法,评估抑制剂与靶蛋白的结合能力。这一过程不仅验证了机器学习算法在化学信息学中的泛化性能,还为高通量虚拟筛选提供了可靠的数据支撑,推动了计算机辅助药物设计的高效发展。
解决学术问题
该数据集有效应对了分子性质预测中的关键学术挑战,特别是小分子药物与靶点相互作用的数据稀缺性问题。通过提供精确标注的BACE-1抑制剂结合结果,它助力研究者探索定量构效关系模型,优化特征选择与表示学习策略,从而提升预测模型的准确性与可解释性。其意义在于为分子机器学习建立了标准化评估框架,加速了人工智能在化学生物学交叉领域的理论创新与方法突破。
衍生相关工作
围绕该数据集衍生的经典工作丰富多样,包括基于图卷积网络的分子表征学习、迁移学习在跨靶点预测中的应用,以及多任务框架下的活性优化研究。例如,MoleculeNet基准中的多项研究引用了BACE数据,推动了DeepChem等开源工具的发展。这些工作不仅拓展了化学信息学的算法边界,还为后续蛋白质-配体相互作用数据库的构建提供了方法论借鉴。
以上内容由遇见数据集搜集并总结生成


