InstaNovo-P
收藏Hugging Face2025-05-14 更新2025-05-15 收录
下载链接:
https://huggingface.co/datasets/InstaDeepAI/InstaNovo-P
下载链接
链接失效反馈官方服务:
资源简介:
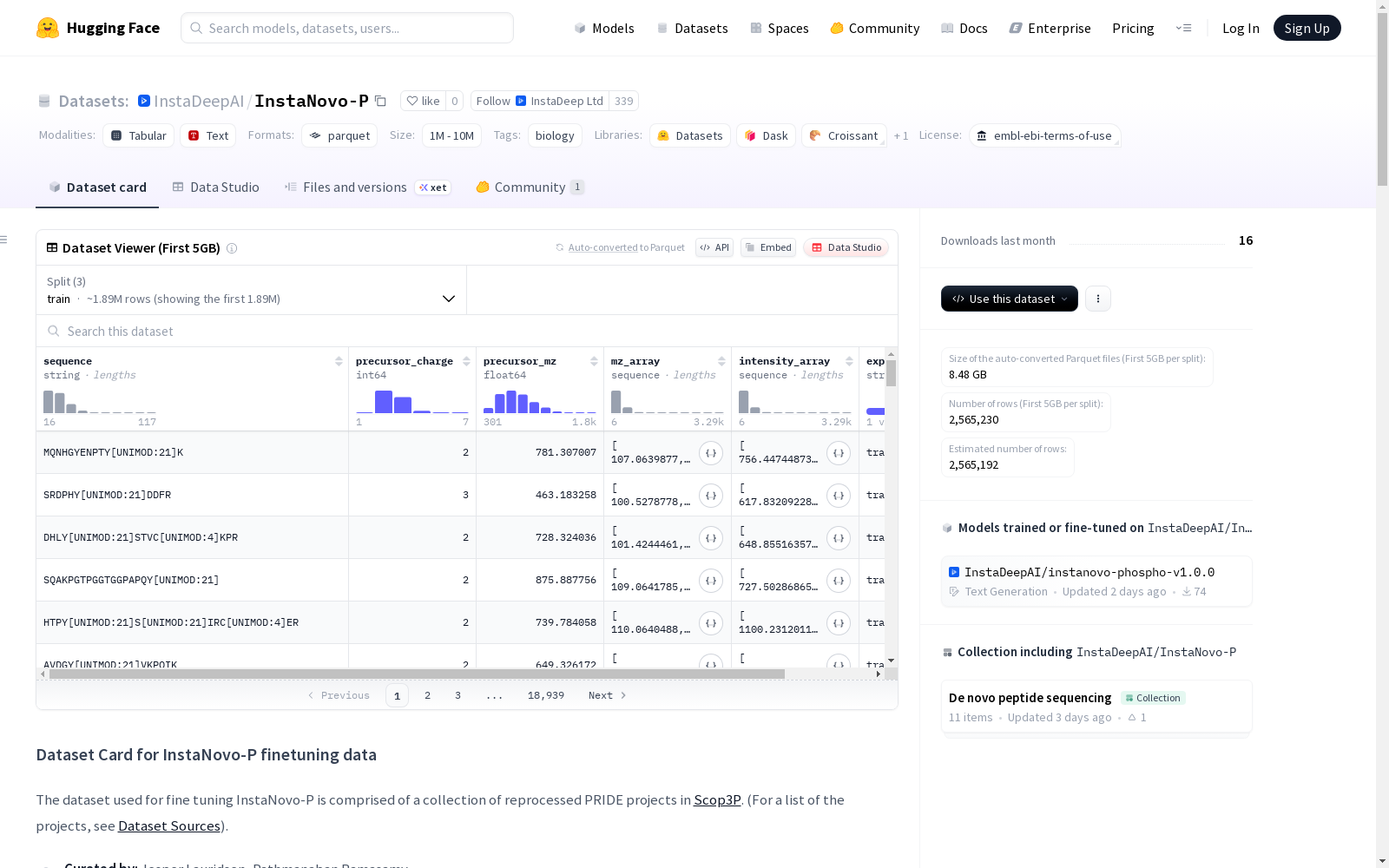
InstaNovo-P微调数据集由重新处理的PRIDE项目组成,这些项目在[Scop3P](https://pubs.acs.org/doi/10.1021/acs.jproteome.0c00306)中进行。为了只对高置信度的PSM进行微调,数据集在0.80的置信度阈值下进行筛选,减少到2,760,939 PSMs,代表74,686个独特的肽序列。大多数数据来自人类,除了[PXD005366](https://www.ebi.ac.uk/pride/archive/projects/PXD005366)和[PXD000218](https://www.ebi.ac.uk/pride/archive/projects/PXD000218),它们包含人类和鼠标的混合物。所有用于训练模型的PSM都包含至少一个磷酸化位点,而169,114个PSM(6%)包含氧化甲硫氨酸。
创建时间:
2025-05-14
搜集汇总
数据集介绍
构建方式
在蛋白质组学领域,InstaNovo-P数据集的构建依托于Scop3P框架下重新处理的PRIDE项目数据,初始包含405万条肽段谱匹配记录。为确保数据质量,研究团队采用0.80置信度阈值进行严格筛选,最终保留276万条高可信度磷酸化肽段数据,涵盖7.4万余条独特序列。通过GraphPart算法结合MMseqs2工具,以0.8同源性阈值实现了训练集、验证集与测试集的科学划分,形成200万/23万/45万的标准化数据分区。
使用方法
使用者可通过加载标准Parquet格式文件直接获取预处理完毕的数据结构,训练集、验证集与测试集已按既定比例完成划分。在实际应用中,建议优先利用质谱强度阵列与肽段序列的映射关系构建序列预测模型,通过前体电荷与质荷比参数优化特征工程。验证阶段可采用随机抽样策略降低计算负载,仅需2%的验证子集即可有效评估模型性能,该设计显著提升了大规模磷酸化肽段鉴定任务的实践效率。
背景与挑战
背景概述
磷酸化蛋白质组学作为后基因组时代的重要研究方向,致力于系统解析生物体内蛋白质磷酸化修饰的调控机制。InstaNovo-P数据集由Jesper Lauridsen与Pathmanaban Ramasamy等学者基于欧洲生物信息学研究所(EMBL-EBI)的PRIDE数据库构建,通过整合28项独立研究的质谱数据,形成了包含270万条高置信度磷酸化肽段序列的专项数据集。该数据集聚焦于磷酸化位点精准鉴定这一核心问题,通过Scop3P流程对原始质谱数据进行重处理,并采用GraphPart算法进行同源性分区,为深度学习模型在翻译后修饰研究领域的应用提供了标准化训练资源。
当前挑战
磷酸化肽段鉴定面临修饰位点定位模糊性与低丰度信号检测灵敏度的双重挑战。数据集构建过程中需克服原始质谱数据异质性难题,通过设定0.80置信度阈值从405万条肽段谱图匹配中筛选高质量数据,同时应对物种混合样本(人源与鼠源)带来的序列同源性干扰。在数据分区环节,基于MMseqs2的图分割算法需平衡训练集与验证集的序列多样性,而氧化甲硫氨酸等共存修饰更增加了谱图解析复杂度,这些因素共同构成了该领域数据标准化与模型泛化能力提升的技术瓶颈。
常用场景
经典使用场景
在蛋白质组学研究中,InstaNovo-P数据集作为磷酸化肽段鉴定的关键资源,其经典应用场景集中于训练深度学习模型进行肽段从头测序。该数据集通过高置信度磷酸化肽段谱图匹配数据,为模型提供了精确的质谱特征与序列对应关系,显著提升了磷酸化位点定位的准确性。研究者利用该数据集优化神经网络参数,实现了对复杂生物样本中修饰肽段的高通量解析。
解决学术问题
该数据集有效解决了磷酸化蛋白质组学中修饰位点鉴定困难的核心问题。通过整合来自28个PRIDE项目的标准化质谱数据,它克服了传统方法对已知数据库的依赖,为未知肽段发现提供了新范式。其经同源性分区处理的训练验证结构,显著降低了模型过拟合风险,推动了翻译后修饰研究从定性描述向定量分析的范式转变。
实际应用
在临床诊断与药物开发领域,该数据集支撑的模型已应用于癌症生物标志物发现。通过解析卵巢癌、前列腺癌等样本的磷酸化特征,研究人员能够识别疾病特异性信号通路异常。制药企业借此加速靶向激酶抑制剂的研发流程,同时为个体化医疗中的磷酸化动态监测提供了技术基础。
数据集最近研究
最新研究方向
在蛋白质组学领域,InstaNovo-P数据集正推动磷酸化肽段鉴定的前沿研究。该数据集整合了来自28个PRIDE项目的270万条高置信度磷酸化肽段谱图匹配,通过同源分区算法GraphPart优化数据划分,显著提升了深度学习模型在翻译后修饰位点预测中的泛化能力。当前研究聚焦于利用该数据集训练端到端序列生成模型,探索酪氨酸与丝氨酸/苏氨酸磷酸化信号通路的差异化调控机制,并与癌症生物标志物发现相结合。这一进展为精准医学中的磷酸化蛋白质组学分析提供了标准化数据基础,促进了人工智能在质谱数据解析中的创新应用。
以上内容由遇见数据集搜集并总结生成


