DeepPavlov/wizard_of_wikipedia_es
收藏Hugging Face2026-05-04 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/DeepPavlov/wizard_of_wikipedia_es
下载链接
链接失效反馈官方服务:
资源简介:
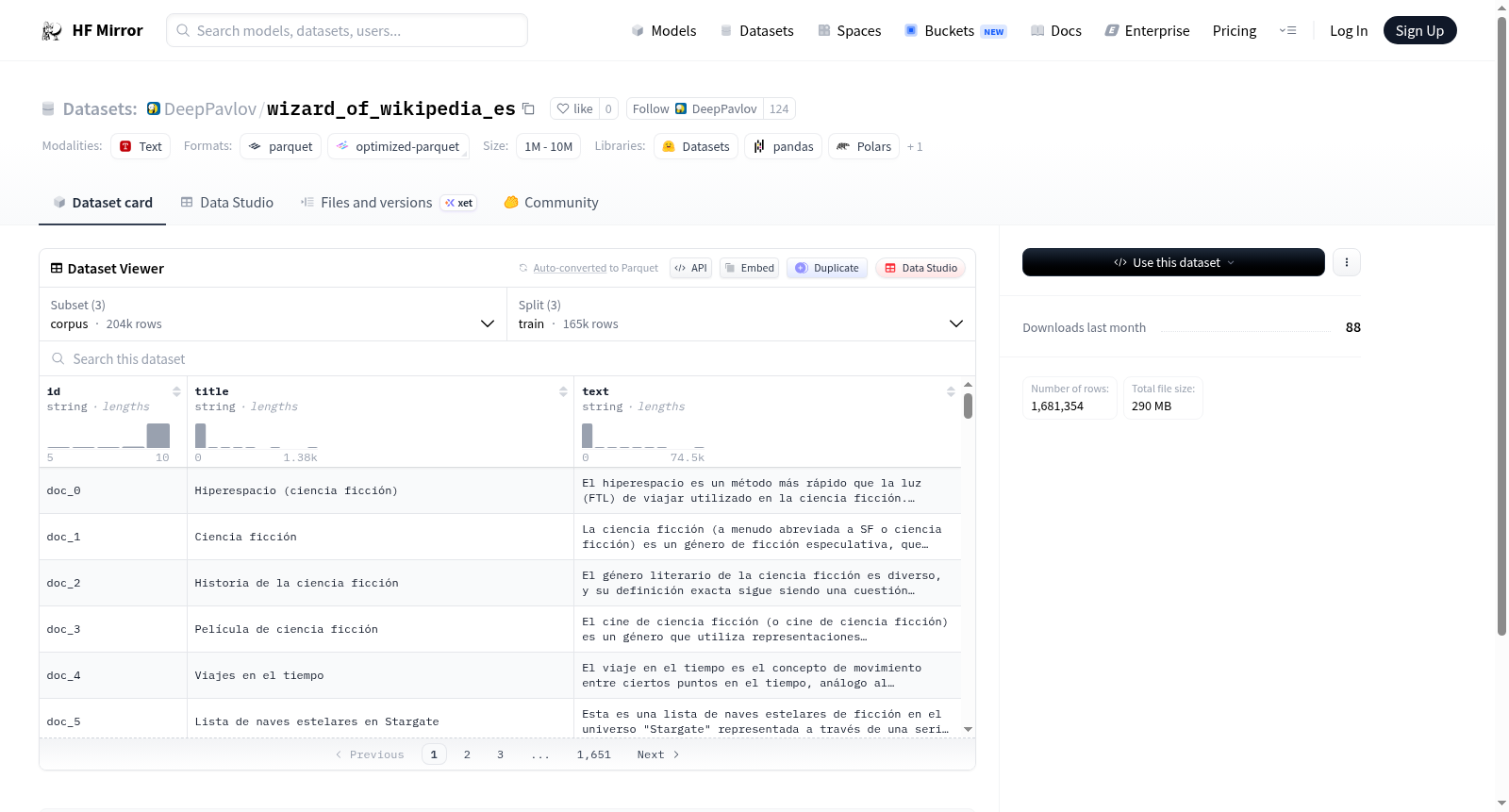
这是一个用于信息检索或对话检索任务的数据集,包含三个主要部分:1. 语料库(corpus):包含文档的ID、标题和文本内容,用于构建文档集合;2. 查询(queries):包含查询的ID、文本内容(由内容和角色组成)、人物角色(persona)和主题(topic),模拟用户查询,支持个性化检索;3. 查询-文档相关性(qrels):包含查询ID、文档ID和相关性分数,用于训练和评估检索模型。数据集分为训练、验证和测试分割,适用于构建和评估检索系统,特别是在个性化上下文中的检索任务。
This is a dataset for information retrieval or conversational retrieval tasks, consisting of three main components: 1. Corpus: includes document IDs, titles, and text content for building a document collection; 2. Queries: includes query IDs, text content (composed of content and role), persona, and topic, simulating user queries with support for personalized retrieval; 3. Query-document relevance (qrels): includes query IDs, document IDs, and relevance scores for training and evaluating retrieval models. The dataset is split into training, validation, and test sets, suitable for building and evaluating retrieval systems, particularly in personalized contexts.
提供机构:
DeepPavlov
搜集汇总
数据集介绍
构建方式
该数据集以Wizard of Wikipedia英文数据集为基础,通过机器翻译或人工翻译技术,将其转换至西班牙语语境,构建了面向西班牙语的知识驱动型对话系统训练资源。数据组织为三个核心配置:语料库(corpus)收纳了16.5万条训练样本,每条包含唯一标识符、主题标题及段落文本,为模型提供领域知识支撑;查询集(queries)保留了对话历史、角色设定与主题标签,以多轮交互格式呈现;相关性判断集(qrels)则编码了查询与语料间的关联得分,用于训练检索模块。三个配置均按训练、验证与测试集划分,确保了研发流程的严谨性。
使用方法
使用时,数据集可通过HuggingFace Datasets库按配置名称灵活加载,例如选择'corpus'、'queries'或'qrels'以满足不同实验需求。对于对话生成任务,研究者可利用queries配置中的对话历史与角色信息,将问题与上下文拼接后输入序列到序列模型进行微调;面向检索任务,则利用qrels配置中的相关性得分训练排序模型,或使用corpus作为知识库构建密集向量索引。数据集预设的分裂文件结构(train、validation、test)适配标准评估流程,用户无需额外划分即可直接进入模型训练与效果验证阶段。
背景与挑战
背景概述
wizard_of_wikipedia_es数据集是大型英文知识驱动对话数据集Wizard of Wikipedia的西班牙语翻译版本,由来自多个机构的研究人员创建,旨在为非英语语言社区提供高质量的知识对话资源。该数据集构建于2022年,核心研究问题在于探索如何将基于知识的开放域对话系统从英语迁移至低资源语言场景,其影响力体现在为西班牙语自然语言处理领域提供了首个大规模、多轮知识对话训练语料,推动了跨语言对话系统的研究与发展。
当前挑战
该数据集面临的核心挑战包括:1) 解决跨语言知识对话中的知识匮乏问题,即西班牙语环境下缺乏高质量的结构化知识库与对话数据,导致模型难以有效融合外部知识进行推理生成;2) 构建过程中需处理机器翻译带来的语义失真与语域不匹配,尤其是一词多义、俚语和百科知识的准确转化极为困难;3) 数据质量平衡问题,需要在保持原始对话结构完整性与目标语言自然度之间取得平衡,避免评估偏差。
常用场景
经典使用场景
Wizard of Wikipedia (西班牙语版) 数据集是为知识驱动型对话系统研究而构建的经典资源,其核心用途在于训练和评估能够主动引用外部知识进行对话的智能体。研究者利用该数据集中的对话历史与结构化知识文本,构建检索增强生成模型,实现对话回复与知识事实的深度绑定。常见的实验范式包括基于检索的对话生成与基于知识图谱的语义对齐,该数据集提供了丰富的对话上下文与对应的维基百科段落,使得模型能够在多轮对话中持续跟踪话题并生成信息密集的回应。其构成涵盖了对话查询、知识语料库及相关性标签,为跨语言对话理解与生成任务提供了标准化的训练与评测平台。
解决学术问题
该数据集面向的核心学术挑战是如何在开放域对话中有效整合外部知识以提升回复的信息性与事实准确性。传统对话模型常因忽视外部知识产生空泛或错误的答复,而Wizard of Wikipedia系列通过提供显式标注的知识链接路径,使研究者能够探索知识检索、上下文对齐与事实一致性控制等关键问题。它直接推动了知识增强型对话系统在长尾知识推理、多源信息融合以及跨语言迁移学习等方面的发展。这一数据集的西班牙语版本进一步填补了非英语场景下的研究空白,为验证多语言对话模型的泛化能力与知识迁移效率提供了重要基准,在自然语言处理领域产生了深远影响。
实际应用
在实际应用层面,该数据集为构建智能客服、教育辅导助手和知识问答机器人提供了关键支撑。例如,在智能客服场景中,模型可以依据用户问题即时检索产品手册或操作指南中的相关段落,生成附有事实依据的回答,从而显著降低误导性信息的输出概率。在教育领域,基于该数据集训练的对话代理能够针对学生提出的概念性问题,从维基百科等权威来源中提取解释并组织成连贯的对话,实现个性化辅助教学。此外,在面向西班牙语用户的内容推荐与虚拟助手产品中,该数据集同样可用于增强系统对实时知识的引用能力,提升交互的自然度与可信赖性。
数据集最近研究
最新研究方向
面向西班牙语知识驱动的开放域对话系统研究。该数据集作为英文Wizard of Wikipedia的西语版本,为跨语言对话智能提供了关键资源。当前前沿研究聚焦于利用其三层结构(包含查询、语料库及相关性标注)训练能主动检索并融合结构化知识的对话模型,尤其在检索增强生成(RAG)框架下探索多轮对话中的知识溯源与动态整合。随着多语言大模型在拉美地区的广泛应用,该数据集成为评估模型在非英语场景下进行知识性对话的基准,推动了多模态混合检索、跨语言知识对齐以及对话交互中事实一致性等热点问题的深入探究,对弥合语言鸿沟、构建全球可用的对话代理具有奠基意义。
以上内容由遇见数据集搜集并总结生成


