dolphin
收藏魔搭社区2026-05-24 更新2024-06-08 收录
下载链接:
https://modelscope.cn/datasets/swift/dolphin
下载链接
链接失效反馈官方服务:
资源简介:
Dolphin 🐬
https://erichartford.com/dolphin
## Dataset details
This dataset is an attempt to replicate the results of [Microsoft's Orca](https://www.microsoft.com/en-us/research/publication/orca-progressive-learning-from-complex-explanation-traces-of-gpt-4/)
Our dataset consists of:
- ~1 million of FLANv2 augmented with GPT-4 completions (flan1m-alpaca-uncensored.jsonl)
- ~3.5 million of FLANv2 augmented with GPT-3.5 completions (flan5m-alpaca-uncensored.jsonl)
We followed the submix and system prompt distribution outlined in the Orca paper. With a few exceptions. We included all 75k of CoT in the FLAN-1m dataset rather than sampling that. Also, we found that many items were duplicated, so we removed duplicates, resulting in 3.5m instructs in the ChatGPT dataset.
Then we filtered out instances of alignment, refusal, avoidance, and bias, in order to produce an uncensored model upon which can be layered your personalized alignment LoRA.
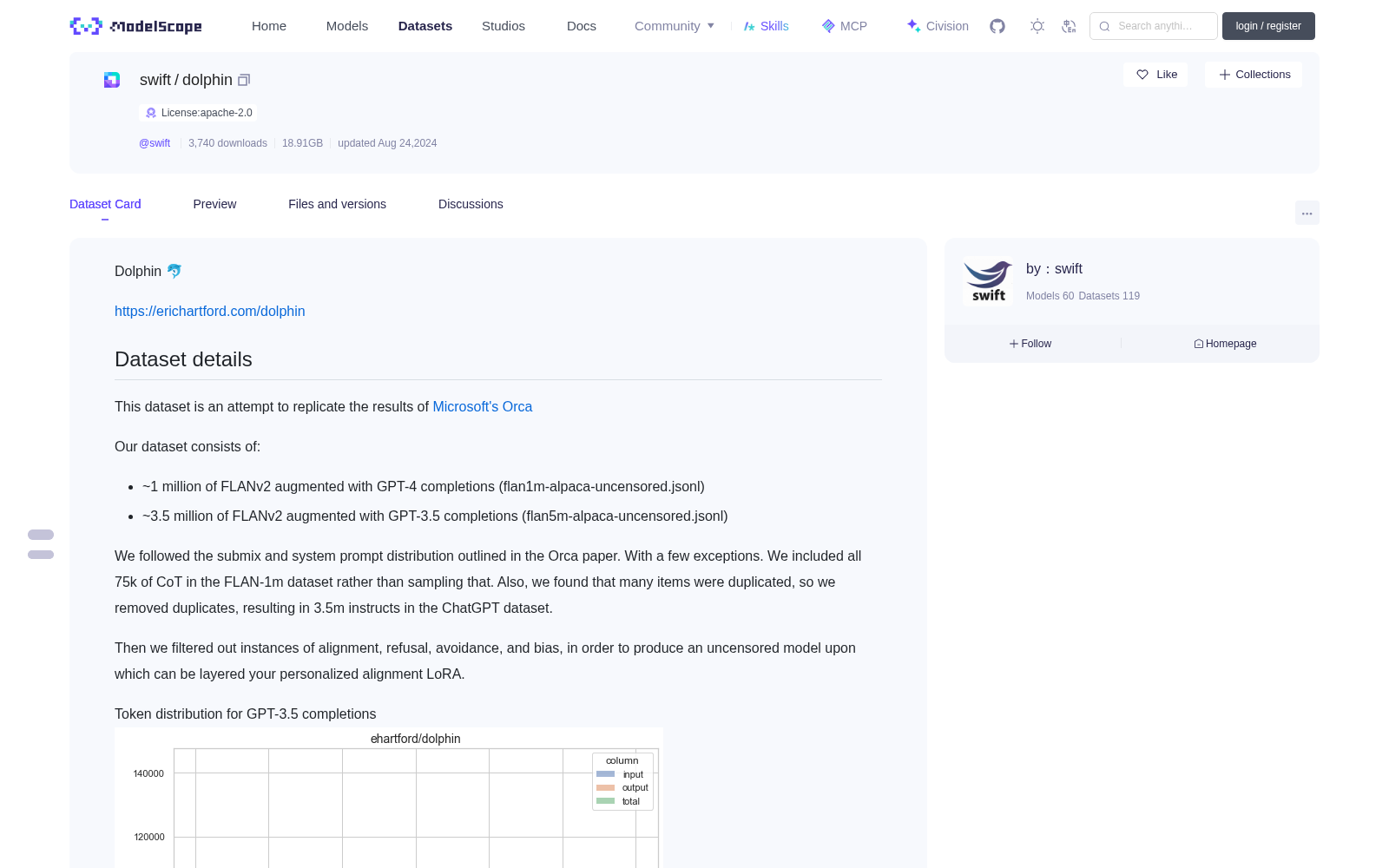
Token distribution for GPT-3.5 completions

### Loading
```python
## load GPT-4 completions
dataset = load_dataset("ehartford/dolphin",data_files="flan1m-alpaca-uncensored.jsonl")
## load GPT-3.5 completions
dataset = load_dataset("ehartford/dolphin",data_files="flan5m-alpaca-uncensored.jsonl")
```
This dataset is licensed apache-2.0 for commercial or non-commercial use.
We currently plan to release Dolphin on:
- Xgen 7b 8k
- LLaMA 13b (Non-commercial)
- MPT 30b 8k
- LLaMA 33b (Non-commercial)
- Falcon 40b
- LLaMA 65b (Non-commercial)
The Dolphin models that are released will be subject to the license of the foundational model on which it is trained. (LLaMA releases will be non-commercial)
I would like to thank the motley crew of Open Source AI/ML engineers who have worked beside me in this endeavor. Including:
- Wing "Caseus" Lian and NanoBit of OpenAccess AI Collective
- Rohan
- Teknium
- Pankaj Mathur
- Tom "TheBloke" Jobbins for quantizing and amplifying
- Special thanks to EdenCoder and chirper.ai for mentorship and financial sponsorship.
- Special thanks to Kilkonie for his very valued mentorship.
- All the other people in the Open Source AI community who have taught me and helped me along the way.
海豚(Dolphin)数据集
项目主页:https://erichartford.com/dolphin
## 数据集详情
本数据集旨在复现[微软Orca(Orca)](https://www.microsoft.com/en-us/research/publication/orca-progressive-learning-from-complex-explanation-traces-of-gpt-4/)的研究成果。
本数据集包含:
- 约100万条经GPT-4(GPT-4)补全增强的FLANv2数据集(文件名为"flan1m-alpaca-uncensored.jsonl")
- 约350万条经GPT-3.5(GPT-3.5)补全增强的FLANv2数据集(文件名为"flan5m-alpaca-uncensored.jsonl")
我们遵循了Orca论文中规定的子混合(submix)与系统提示词分布框架,但存在少量例外:我们未对FLAN-1m数据集中的7.5万条思维链(Chain-of-Thought,CoT)样本进行采样,而是完整保留了全部样本。此外,我们发现存在大量重复样本,因此对其进行了去重处理,最终在ChatGPT数据集中保留了350万条指令样本。
随后,我们过滤掉了包含对齐(alignment)、拒绝生成、回避及偏见的样本,以构建一个无审查的模型底座,可在此之上叠加您的个性化对齐低秩自适应(Low-Rank Adaptation,LoRA)模块。
### GPT-3.5补全样本的Token分布

### 加载方式
python
## 加载GPT-4补全数据集
dataset = load_dataset("ehartford/dolphin",data_files="flan1m-alpaca-uncensored.jsonl")
## 加载GPT-3.5补全数据集
dataset = load_dataset("ehartford/dolphin",data_files="flan5m-alpaca-uncensored.jsonl")
本数据集采用Apache-2.0许可证,可用于商业或非商业用途。
我们目前计划基于以下基座模型发布Dolphin系列模型:
- Xgen 7B 8K上下文窗口版本
- LLaMA 13B(非商业用途)
- MPT 30B 8K上下文窗口版本
- LLaMA 33B(非商业用途)
- Falcon 40B
- LLaMA 65B(非商业用途)
所有发布的Dolphin模型将遵循其训练所用基座模型的许可证协议(LLaMA基座衍生模型仅可用于非商业用途)。
在此,我谨向在本项目中与我并肩协作的开源AI/ML工程师团队致以感谢,他们包括:
- OpenAccess AI Collective的Wing「Caseus」Lian与NanoBit
- Rohan
- Teknium
- Pankaj Mathur
- Tom「TheBloke」Jobbins,感谢其完成模型量化与推广工作
- 特别感谢EdenCoder与chirper.ai提供的指导与资金赞助
- 特别感谢Kilkonie提供的宝贵指导
- 以及开源AI社区中所有曾在学习与实践过程中给予我指导与帮助的同仁。
提供机构:
maas创建时间:
2024-06-06
搜集汇总
数据集介绍
背景与挑战
背景概述
Dolphin数据集旨在复现微软Orca的研究成果,包含约100万条基于FLANv2增强的GPT-4补全和约350万条GPT-3.5补全数据,经过去重和过滤以生成未审查模型。该数据集采用Apache-2.0许可证,计划在多个基础模型上发布,其中LLaMA版本仅限非商业使用。
以上内容由遇见数据集搜集并总结生成


