biocreative-strategies/ai4science-commercial-lens
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/biocreative-strategies/ai4science-commercial-lens
下载链接
链接失效反馈官方服务:
资源简介:
BC AI4Science商业视角数据集是对Hugging Science资源的重新标记,使用商业买家角色标签。该数据集旨在帮助生命科学领域的商业团队(如业务发展、市场营销、产品、科学事务、临床运营)快速识别哪些开源AI4Science资源与他们的日常工作相关。数据集基于科学领域、最可能在对话中遇到的商业角色以及为该角色提供的可操作信号,对每个HS资源(数据集、模型、博客文章)进行六个商业买家角色维度的标记。数据来源为huggingscience.co/llms-full.txt,更新频率为每月一次,由BioCreative Strategies维护。
A re-tagging of every Hugging Science (huggingscience.co) resource with commercial-buyer-persona tags. Helps commercial teams in life sciences (BD, marketing, product, scientific affairs, clinical ops) quickly identify which open-source AI4Science resources are relevant to their day-to-day work. Each HS resource (dataset, model, blog post) is tagged across 6 commercial-buyer-persona axes based on: the scientific domain it operates in, the commercial role most likely to encounter it in conversation, and the actionable signal it provides for that role. Source data is from huggingscience.co/llms-full.txt, updated monthly, and maintained by BioCreative Strategies.
提供机构:
biocreative-strategies
搜集汇总
数据集介绍
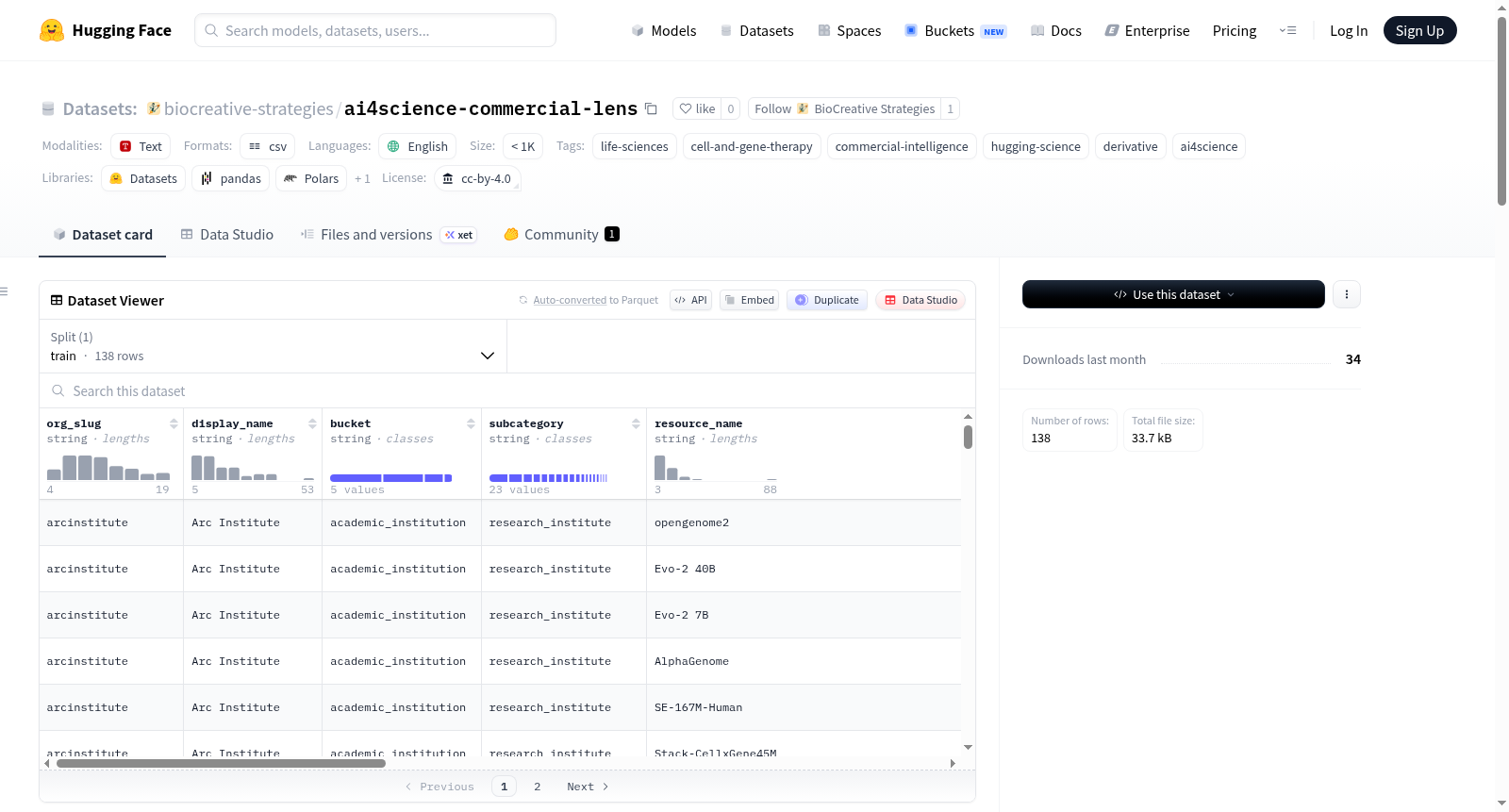
构建方式
该数据集基于Hugging Science平台公开的llms-full.txt资源清单,由BioCreative Strategies团队采用系统性方法构建而成。每个资源(包括数据集、模型及博客文章)均依据六个商业买家角色轴进行重新标注:涵盖其所在的科学领域、最可能在日常工作中接触到的商业职能,以及能为该职能提供的可操作信号。标注过程结合专家评审与月度人工复查机制,确保标签的准确性与时效性,最终形成一份约200至450行的结构化索引,支持CSV与JSONL格式存储。
特点
数据集的独特之处在于其角色导向的标注体系,将开源AI4Science资源与生命科学领域的商业决策场景深度绑定。六个预设角色(业务拓展、市场营销、产品管理、科学事务、临床运营及商业运营)各有针对性标签,使商业团队能快速筛选出与其职责高度相关的资源。例如,业务拓展角色可识别出暗示潜在合作或收购目标的高信号资源,而临床运营角色则聚焦于临床试验设计与生物标志物策略相关的条目。这种设计大幅降低了技术背景与非技术团队间的信息壁垒,提供精准的决策支持。
使用方法
使用者可通过浏览标注数据表直接调用,每行记录均包含资源名称、类型、主题及六个角色的信号强度评级(高/中/低)。商业团队在生命科学领域的日常工作中,可根据自身角色筛选对应标签列评级为“高”的资源,作为情报速览或工作参考。数据集支持CSV与JSONL格式,便于集成至商业分析工具或机器学习工作流。建议结合Hugging Science原始资源页面获取详细技术信息,并依据CC-BY-4.0许可协议进行衍生使用,同时保留对BioCreative Strategies的署名。
背景与挑战
背景概述
在生命科学领域,商业决策往往依赖于对前沿人工智能与科学(AI4Science)资源的快速解读。由BioCreative Strategies于2026年创建的BC AI4Science Commercial Lens数据集,通过为Hugging Science平台上的公开资源(包括模型、数据集与博文)标注商业买家角色标签,旨在弥合开放科学成果与商业应用之间的鸿沟。该数据集覆盖业务拓展、营销、产品管理等六类典型商业角色,使生命科学领域的商业团队能够高效筛选出与其日常工作相关的AI资源。这一创新索引不仅提升了开源资源在行业中的可及性,更推动了AI4Science从实验室向商业落地的转化,对生命科学领域的商业智能发展具有里程碑式的影响。
当前挑战
该数据集面临的挑战源于两个方面。在领域问题层面,生命科学领域的商业团队常面临海量开源AI资源与有限时间的矛盾,亟需一种能快速定位与自身角色相关资源的智能索引机制。在构建过程中,挑战则体现在如何从450余项资源中准确提炼信号,确保标签的科学性与实用性。手动月度审查虽保证了质量,却限制了可扩展性,且标签需动态适应商业角色演变与资源更新。此外,保持对角色相关性的客观判断,避免主观偏差,同时维持许可合规性(CC-BY-4.0),亦是数据集成败的关键所在。
常用场景
经典使用场景
该数据集的核心价值在于为生命科学领域的商业团队提供一套结构化的资源导航工具。通过将Hugging Science平台上公开的AI4Science资源(包括模型、数据集、博客文章)按照六种商业买家角色(如商务拓展、市场营销、产品管理、科学事务、临床运营、商业运营)进行标签化分类,数据集能够帮助用户快速筛选出与其日常工作高度相关的开源资源。经典使用场景包括:一家生物科技公司的商务拓展负责人可以利用该数据集迅速锁定那些展示出AI活跃度的顶尖学术机构,从而制定精准的合作许可或并购目标清单。
实际应用
在实际应用层面,该数据集直接服务于生命科学企业的多种商业场景。市场部门可基于标签分析竞争对手在基因治疗等热门领域的资源布局,从而优化自身内容策略与市场定位。产品团队能快速识别与自家管线技术相关的开源基准测试或模型,用于产品路线图的优先级排序。临床运营团队则可通过筛选标记为'临床运营'高相关性的资源,获取临床试验设计或生物标志物选择上的创新思路。此外,该数据集还可作为销售赋能工具,帮助销售代表在客户对话中精准引用具有影响力的开源研究成果。
衍生相关工作
该数据集的衍生价值体现在多个维度:其一,它可作为构建更复杂的商业情报系统的基石,例如通过将角色标签与公司关系图谱结合,预测AI4Science领域的潜在合作伙伴。其二,其标签化方法论可迁移至其他垂直技术领域(如计算材料科学、清洁能源),形成跨领域的'商业透镜'数据集家族。其三,该数据集的定期更新机制使动态分析资源趋势成为可能,衍生的系列工作包括季度性的'生命科学AI商业活跃度报告',以及基于标签共现的商业生态系统图谱。这些衍生工作共同推动着AI驱动下的科学资源商业化评估从直觉判断走向数据驱动。
以上内容由遇见数据集搜集并总结生成


