RefEdit-Data
收藏arXiv2025-06-04 更新2025-06-06 收录
下载链接:
http://refedit.vercel.app
下载链接
链接失效反馈官方服务:
资源简介:
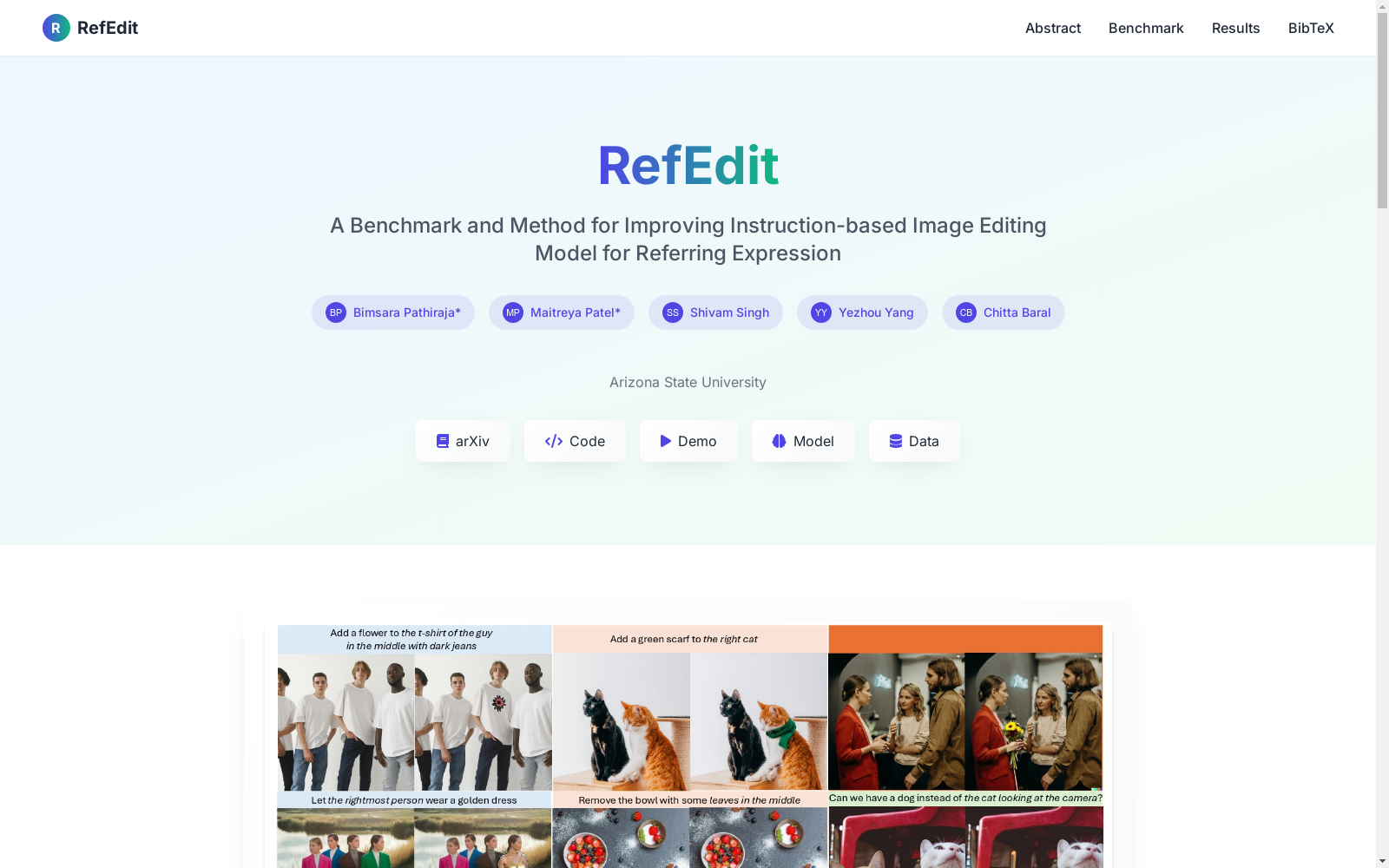
RefEdit-Data是一个基于指示的图像编辑数据集,由亚利桑那州立大学创建。该数据集包含超过20000个图像编辑三元组,旨在帮助图像编辑模型在复杂的场景中准确识别和编辑多个实体。数据集通过一个可扩展的合成数据生成管道创建,使用GPT-4o生成复杂的编辑任务,并整合了Grounded Segment Anything和FlowChef技术进行精确、受控的编辑。RefEdit-Data被用于训练RefEdit模型,该模型在RefEdit-Bench基准测试中表现出色,超越了在数百万数据上训练的现有方法。
RefEdit-Data is an instruction-based image editing dataset created by Arizona State University. This dataset contains over 20,000 image editing triplets, aiming to assist image editing models in accurately identifying and editing multiple entities in complex scenarios. It is constructed via a scalable synthetic data generation pipeline, where GPT-4o is used to generate complex editing tasks, and Grounded Segment Anything and FlowChef technologies are integrated to enable precise and controlled editing. RefEdit-Data is utilized to train the RefEdit model, which achieves excellent performance on the RefEdit-Bench benchmark and outperforms existing methods trained on millions of data samples.
提供机构:
亚利桑那州立大学
创建时间:
2025-06-04
搜集汇总
数据集介绍
构建方式
RefEdit-Data数据集的构建采用了创新的合成数据生成流程,通过GPT-4o生成图像提示、编辑指令及描述性指代表达,结合FLUX生成高分辨率图像,并利用Grounded Segment Anything进行精确掩码生成。编辑任务分为五大类别,包括颜色更改、对象替换等,确保数据多样性和复杂性。最终,通过Inpaint Anything和FlowChef技术生成编辑后的图像,构建了一个包含20000+样本的高质量训练数据集。
特点
RefEdit-Data数据集以其复杂场景下的多实体编辑能力著称,特别针对指代表达的挑战进行了优化。数据集包含多样化的编辑任务,如颜色更改、对象添加与移除等,且每个任务均涉及多个相似实体的精确识别与编辑。此外,数据集的样本均经过精心设计,确保背景信息的保留与编辑的局部性,从而显著提升了模型在复杂场景下的编辑精度。
使用方法
RefEdit-Data数据集主要用于训练和评估基于指令的图像编辑模型,特别是在涉及多实体和复杂指代表达的场景中。研究人员可通过该数据集微调扩散模型(如Stable Diffusion),以提升模型在真实世界图像编辑任务中的表现。数据集还附带详细的基准测试(RefEdit-Bench),支持对模型性能的全面评估,包括语义一致性和感知质量等指标。
背景与挑战
背景概述
RefEdit-Data是由亚利桑那州立大学的研究团队于2025年提出的一个基于指代表达的图像编辑基准数据集。该数据集旨在解决当前图像生成模型在复杂场景下对多实体进行精确编辑的难题。研究团队通过整合RefCOCO数据集中的真实图像,并利用GPT-4o和Grounded Segment Anything等技术,构建了一个包含20,000个编辑三元组的高质量数据集。RefEdit-Data的提出不仅填补了指代表达在生成式图像编辑领域的空白,还为相关研究提供了可靠的评估基准。
当前挑战
RefEdit-Data面临的挑战主要体现在两个方面:领域问题的挑战和构建过程的挑战。在领域问题方面,现有图像编辑模型难以在包含多个相似实体的复杂场景中准确定位目标对象并进行精确编辑,导致编辑溢出或失败。在构建过程方面,研究团队需要克服指代表达的歧义性、编辑指令的多样性以及高质量合成数据的生成等难题。此外,确保编辑后的图像在语义一致性和视觉质量上达到高标准也是一项重要挑战。
常用场景
经典使用场景
RefEdit-Data 数据集在计算机视觉领域被广泛用于评估和提升基于指令的图像编辑模型的性能。特别是在涉及复杂场景和多实体图像编辑任务中,该数据集通过提供精确的指代表达和编辑指令,帮助研究人员验证模型在识别和编辑特定对象时的准确性和鲁棒性。例如,在编辑包含多个相似实体的图像时,RefEdit-Data 能够有效测试模型是否能够正确理解并执行如“将最右边的人的衣服改为金色”这样的复杂指令。
解决学术问题
RefEdit-Data 解决了图像编辑领域中的一个关键问题:在多实体复杂场景中,模型难以准确识别和编辑特定对象。通过引入基于指代表达的编辑任务,该数据集填补了现有方法在复杂场景编辑中的性能空白。其意义在于为研究者提供了一个标准化的评估基准,推动了图像编辑模型在精确性和泛化能力方面的进步,同时也为生成对抗网络(GANs)和扩散模型的研究提供了新的数据支持。
衍生相关工作
RefEdit-Data 的发布催生了一系列相关研究,特别是在基于指令的图像编辑领域。例如,RefEdit 模型通过在该数据集上的训练,显著提升了在复杂场景中的编辑性能。此外,许多后续工作借鉴了其数据生成 pipeline,进一步优化了模型的指代表达理解能力。这些衍生工作不仅扩展了数据集的应用范围,还推动了图像编辑技术在实际场景中的落地。
以上内容由遇见数据集搜集并总结生成


