WildSketch
收藏arXiv2021-12-02 更新2024-06-21 收录
下载链接:
http://lingboliu.com/unconstrained_face_sketch.html
下载链接
链接失效反馈官方服务:
资源简介:
WildSketch是由华南理工大学和香港理工大学合作创建的一个新的数据集,专注于无约束条件下的面部素描合成。该数据集包含800对面部照片-素描,其规模是现有流行数据集的四倍。WildSketch的图像来源于真实世界场景,展示了各种姿态、表情、年龄甚至严重的遮挡。此外,数据集的背景比以往任何数据集都更复杂和多样。WildSketch的建立旨在推动无约束面部素描合成领域的研究,提供一个中规模的数据集,以支持更广泛的训练和评估需求。
WildSketch is a novel dataset co-created by South China University of Technology and The Hong Kong Polytechnic University, focusing on unconstrained facial sketch synthesis. It contains 800 pairs of facial photo-sketch samples, with a scale four times that of existing popular datasets. The images in WildSketch are sourced from real-world scenarios, showcasing various poses, expressions, age groups, and even severe occlusions. Additionally, the backgrounds in this dataset are more complex and diverse than those of any previous datasets. WildSketch is developed to advance research in the field of unconstrained facial sketch synthesis, providing a medium-scale dataset to support broader training and evaluation requirements.
提供机构:
华南理工大学, 中国
创建时间:
2021-12-02
搜集汇总
数据集介绍
构建方式
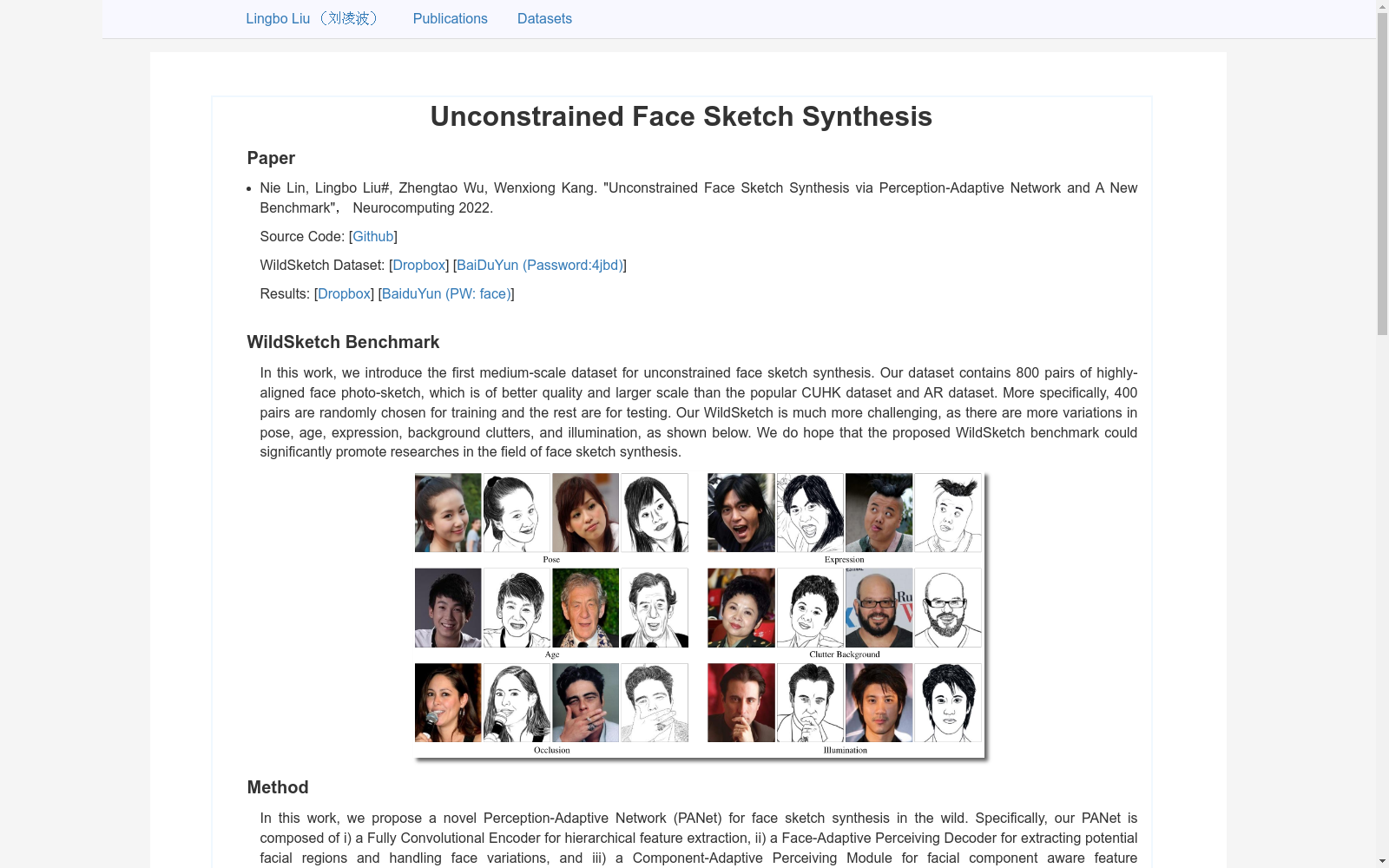
WildSketch数据集的构建方法主要涉及两个步骤。首先,从FaceScrub数据集中收集了530位西方名人身份的照片,以及从互联网上收集了270位亚洲名人身份的照片,以确保数据集的种族多样性。然后,邀请艺术家根据每张照片在电子绘图板上绘制草图,确保照片和草图的高度对齐。最终,数据集包含了800对高度对齐的人脸照片-草图对,其中400对用于训练,400对用于测试。这种构建方法确保了数据集的多样性和实用性。
特点
WildSketch数据集具有三个显著特点。首先,它是首个针对无约束人脸草图合成任务的中等规模基准数据集,包含800对人脸照片-草图对,比流行的CUHK和AR数据集大四倍。其次,数据集中的图像来自现实场景,人脸展现出各种姿态、表情、年龄,甚至有严重的遮挡。第三,数据集中的背景比所有以前的基准更加复杂和多样化。这些特点使得WildSketch数据集成为评估和训练无约束人脸草图合成算法的理想选择。
使用方法
使用WildSketch数据集的方法主要包括以下几个步骤。首先,将数据集中的800对人脸照片-草图对分为训练集和测试集,其中400对用于训练,400对用于测试。然后,利用训练集训练人脸草图合成模型,如PANet。在训练过程中,可以采用多种评价指标,如Scoot、FSIM和FID,以评估模型的性能。最后,利用测试集对训练好的模型进行评估,以验证其在无约束人脸草图合成任务上的有效性。
背景与挑战
背景概述
WildSketch数据集是在2021年12月由林涅、李灵波、吴正涛、康文雄等人共同创建的,旨在解决无约束人脸素描合成的问题。该数据集的创建背景源于人脸素描在计算机视觉领域的重要性,尤其在执法和数字娱乐等现实场景中的应用。然而,现有的方法往往局限于有约束条件下的人脸素描生成,或者需要依赖各种预处理步骤来处理无约束情况。WildSketch数据集的创建填补了这一空白,它包含了800对人脸照片和素描,具有广泛的姿态、表情、种族、背景和光照变化,为无约束人脸素描合成的研究提供了新的基准。
当前挑战
WildSketch数据集面临的挑战主要包括:1) 所解决的领域问题是无约束人脸素描合成,这需要模型能够从复杂的背景中准确感知面部区域和面部组件;2) 构建过程中遇到的挑战包括收集多样化的人脸照片和对应的素描,以及确保数据集的质量和规模。此外,现有的评估指标如SSIM可能与人类对素描的感知不一致,因此需要寻找更合理的评估指标。
常用场景
经典使用场景
WildSketch数据集主要应用于无约束人脸素描生成任务,该任务旨在从人脸照片自动生成素描。在法律执法、数字娱乐等实际场景中,人脸素描生成具有广泛的应用价值。WildSketch数据集包含了800对人脸照片和素描,涵盖了各种姿势、表情、种族、背景和光照条件,为无约束人脸素描生成的研究提供了宝贵的资源。
实际应用
WildSketch数据集在人脸识别、人像合成、人像修复等领域具有广泛的应用前景。在人脸识别领域,WildSketch数据集可以帮助研究者训练出更鲁棒的人脸识别模型,提高识别准确率;在人像合成领域,WildSketch数据集可以为艺术家提供更多样化的人像素材,帮助他们创作出更具创意的作品;在人像修复领域,WildSketch数据集可以帮助研究者修复受损的人脸图像,恢复图像的完整性。
衍生相关工作
WildSketch数据集的提出激发了研究者对无约束人脸素描生成任务的兴趣,并衍生出了一系列相关研究。例如,一些研究者基于WildSketch数据集提出了新的无约束人脸素描生成模型,如PANet、CA-GAN等,这些模型在无约束人脸素描生成任务上取得了显著的效果。此外,一些研究者还基于WildSketch数据集研究了人脸素描生成任务的评估指标,如Scoot、FSIM等,这些指标可以更准确地评估模型的性能。
以上内容由遇见数据集搜集并总结生成


