google/imageinwords
收藏Hugging Face2024-05-25 更新2024-05-18 收录
下载链接:
https://hf-mirror.com/datasets/google/imageinwords
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- expert-generated
- crowdsourced
license: cc-by-4.0
task_categories:
- image-to-text
- text-to-image
- object-detection
language:
- en
size_categories:
- 1K<n<10K
tags:
- iiw
- imageinwords
- image-descriptions
- image-captions
- detailed-descriptions
- hyper-detailed-descriptions
- object-descriptions
- object-detection
- object-labels
- image-text
- t2i
- i2t
- dataset
pretty_name: ImageInWords
multilinguality:
- monolingual
---
<h2>ImageInWords: Unlocking Hyper-Detailed Image Descriptions</h2>
Please visit the [webpage](https://google.github.io/imageinwords) for all the information about the IIW project, data downloads, visualizations, and much more.
<img src="https://github.com/google/imageinwords/blob/main/static/images/Abstract/1_white_background.png?raw=true">
<img src="https://github.com/google/imageinwords/blob/main/static/images/Abstract/2_white_background.png?raw=true">
Please reach out to iiw-dataset@google.com for thoughts/feedback/questions/collaborations.
<h3>🤗Hugging Face🤗</h3>
<li><a href="https://huggingface.co/datasets/google/imageinwords">IIW-Benchmark Eval Dataset</a></li>
```python
from datasets import load_dataset
# `name` can be one of: IIW-400, DCI_Test, DOCCI_Test, CM_3600, LocNar_Eval
# refer: https://github.com/google/imageinwords/tree/main/datasets
dataset = load_dataset('google/imageinwords', token=None, name="IIW-400", trust_remote_code=True)
```
<li><a href="https://huggingface.co/spaces/google/imageinwords-explorer">Dataset-Explorer</a></li>
## Dataset Description
- **Paper:** [arXiv](https://arxiv.org/abs/2405.02793)
- **Homepage:** https://google.github.io/imageinwords/
- **Point of Contact:** iiw-dataset@google.com
- **Dataset Explorer:** [ImageInWords-Explorer](https://huggingface.co/spaces/google/imageinwords-explorer)
### Dataset Summary
ImageInWords (IIW), a carefully designed human-in-the-loop annotation framework for curating hyper-detailed image descriptions and a new dataset resulting from this process.
We validate the framework through evaluations focused on the quality of the dataset and its utility for fine-tuning with considerations for readability, comprehensiveness, specificity, hallucinations, and human-likeness.
This Data Card describes **IIW-Benchmark: Eval Datasets**, a mixture of human annotated and machine generated data intended to help create and capture rich, hyper-detailed image descriptions.
IIW dataset has two parts: human annotations and model outputs. The main purposes of this dataset are:
1) to provide samples from SoTA human authored outputs to promote discussion on annotation guidelines to further improve the quality
2) to provide human SxS results and model outputs to promote development of automatic metrics to mimic human SxS judgements.
### Supported Tasks
Text-to-Image, Image-to-Text, Object Detection
### Languages
English
## Dataset Structure
### Data Instances
### Data Fields
For details on the datasets and output keys, please refer to our [GitHub data](https://github.com/google/imageinwords/tree/main/datasets) page inside the individual folders.
IIW-400:
- `image/key`
- `image/url`
- `IIW`: Human generated image description
- `IIW-P5B`: Machine generated image description
- `iiw-human-sxs-gpt4v` and `iiw-human-sxs-iiw-p5b`: human SxS metrics
- metrics/Comprehensiveness
- metrics/Specificity
- metrics/Hallucination
- metrics/First few line(s) as tldr
- metrics/Human Like
DCI_Test:
- `image`
- `image/url`
- `ex_id`
- `IIW`: Human authored image description
- `metrics/Comprehensiveness`
- `metrics/Specificity`
- `metrics/Hallucination`
- `metrics/First few line(s) as tldr`
- `metrics/Human Like`
DOCCI_Test:
- `image`
- `image/thumbnail_url`
- `IIW`: Human generated image description
- `DOCCI`: Image description from DOCCI
- `metrics/Comprehensiveness`
- `metrics/Specificity`
- `metrics/Hallucination`
- `metrics/First few line(s) as tldr`
- `metrics/Human Like`
LocNar_Eval:
- `image/key`
- `image/url`
- `IIW-P5B`: Machine generated image description
CM_3600:
- `image/key`
- `image/url`
- `IIW-P5B`: Machine generated image description
Please note that all fields are string.
### Data Splits
Dataset | Size
---| ---:
IIW-400 | 400
DCI_Test | 112
DOCCI_Test | 100
LocNar_Eval | 1000
CM_3600 | 1000
### Annotations
#### Annotation process
Some text descriptions were written by human annotators and some were generated by machine models.
The metrics are all from human SxS.
### Personal and Sensitive Information
The images that were used for the descriptions and the machine generated text descriptions are checked (by algorithmic methods and manual inspection) for S/PII, pornographic content, and violence and any we found may contain such information have been filtered.
We asked that human annotators use an objective and respectful language for the image descriptions.
### Licensing Information
CC BY 4.0
### Citation Information
```
@misc{garg2024imageinwords,
title={ImageInWords: Unlocking Hyper-Detailed Image Descriptions},
author={Roopal Garg and Andrea Burns and Burcu Karagol Ayan and Yonatan Bitton and Ceslee Montgomery and Yasumasa Onoe and Andrew Bunner and Ranjay Krishna and Jason Baldridge and Radu Soricut},
year={2024},
eprint={2405.02793},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
annotations_creators: 注释创建者:
- 专家生成(expert-generated)
- 众包(crowdsourced)
license: 许可证:CC BY 4.0(知识共享署名4.0国际许可协议)
task_categories: 任务类别:
- 图像到文本(image-to-text)
- 文本到图像(text-to-image)
- 目标检测(object-detection)
language: 语言:
- 英语(en)
size_categories: 规模类别:
- 1K<n<10K
tags: 标签:
- iiw(ImageInWords)
- imageinwords
- image-descriptions(图像描述)
- image-captions(图像字幕)
- detailed-descriptions(详细描述)
- hyper-detailed-descriptions(超详细描述)
- object-descriptions(目标描述)
- object-detection(目标检测)
- object-labels(目标标签)
- image-text(图像-文本)
- t2i(text-to-image,文本到图像)
- i2t(image-to-text,图像到文本)
- dataset(数据集)
pretty_name: 展示名称:ImageInWords
multilinguality: 多语言类型:单语言(monolingual)
---
## ImageInWords:解锁超详细图像描述
请访问[网页](https://google.github.io/imageinwords)以获取IIW(ImageInWords)项目的所有相关信息、数据下载、可视化内容及更多资源。
<img src="https://github.com/google/imageinwords/blob/main/static/images/Abstract/1_white_background.png?raw=true">
<img src="https://github.com/google/imageinwords/blob/main/static/images/Abstract/2_white_background.png?raw=true">
请发送邮件至iiw-dataset@google.com交流想法、反馈问题或寻求合作。
<h3>🤖 Hugging Face🤖</h3>
<li><a href="https://huggingface.co/datasets/google/imageinwords">IIW-Benchmark 评测数据集</a></li>
python
from datasets import load_dataset
# `name` 可选值包括:IIW-400、DCI_Test、DOCCI_Test、CM_3600、LocNar_Eval,具体参考:https://github.com/google/imageinwords/tree/main/datasets
dataset = load_dataset('google/imageinwords', token=None, name="IIW-400", trust_remote_code=True)
<li><a href="https://huggingface.co/spaces/google/imageinwords-explorer">数据集浏览器</a></li>
## 数据集说明
- **论文:** [arXiv](https://arxiv.org/abs/2405.02793)
- **主页:** https://google.github.io/imageinwords/
- **联系人:** iiw-dataset@google.com
- **数据集浏览器:** [ImageInWords-数据集浏览器](https://huggingface.co/spaces/google/imageinwords-explorer)
### 数据集概述
ImageInWords(简称IIW)是一套精心设计的人机协同注释框架,用于构建超详细图像描述集,同时该框架也产出了全新的配套数据集。我们通过针对数据集质量的评估验证了该框架的有效性,评估维度涵盖可读性、全面性、特异性、幻觉性(hallucinations)及类人性,并验证了其在微调场景中的实用性。
本数据卡片介绍的是**IIW-Benchmark:评测数据集**,该数据集融合了人工注释与机器生成数据,旨在助力生成并获取丰富的超详细图像描述。
IIW数据集包含两部分:人工注释内容与模型输出结果。本数据集的核心用途有二:
1) 提供当前顶尖水平(State-of-the-art,简称SoTA)的人工创作样本,以推动注释指南的讨论迭代,进一步提升标注质量
2) 提供人类并排对比(side-by-side,简称SxS)结果与模型输出,以推动自动评测指标的开发,使其能够模拟人类的并排对比评判。
### 支持任务
文本到图像(text-to-image)、图像到文本(image-to-text)、目标检测(object-detection)
### 语言
英语
## 数据集结构
### 数据实例
### 数据字段
关于各数据集及输出字段的详细信息,请参考我们[GitHub数据集页面](https://github.com/google/imageinwords/tree/main/datasets)中对应子文件夹内的文档。
IIW-400:
- `image/key`:图像键值
- `image/url`:图像链接
- `IIW`:人工生成的图像描述
- `IIW-P5B`:机器生成的图像描述
- `iiw-human-sxs-gpt4v` 与 `iiw-human-sxs-iiw-p5b`:人类并排对比评测指标
- metrics/Comprehensiveness:全面性指标
- metrics/Specificity:特异性指标
- metrics/Hallucination:幻觉性指标
- metrics/First few line(s) as tldr:以开头若干行作为摘要的指标
- metrics/Human Like:类人性指标
DCI_Test:
- `image`:图像
- `image/url`:图像链接
- `ex_id`:示例ID
- `IIW`:人工创作的图像描述
- `metrics/Comprehensiveness`:全面性指标
- `metrics/Specificity`:特异性指标
- `metrics/Hallucination`:幻觉性指标
- `metrics/First few line(s) as tldr`:以开头若干行作为摘要的指标
- `metrics/Human Like`:类人性指标
DOCCI_Test:
- `image`:图像
- `image/thumbnail_url`:图像缩略图链接
- `IIW`:人工生成的图像描述
- `DOCCI`:来自DOCCI的图像描述
- `metrics/Comprehensiveness`:全面性指标
- `metrics/Specificity`:特异性指标
- `metrics/Hallucination`:幻觉性指标
- `metrics/First few line(s) as tldr`:以开头若干行作为摘要的指标
- `metrics/Human Like`:类人性指标
LocNar_Eval:
- `image/key`:图像键值
- `image/url`:图像链接
- `IIW-P5B`:机器生成的图像描述
CM_3600:
- `image/key`:图像键值
- `image/url`:图像链接
- `IIW-P5B`:机器生成的图像描述
请注意,所有字段均为字符串类型。
### 数据拆分
| 数据集 | 样本数量 |
|---|---:
| IIW-400 | 400 |
| DCI_Test | 112 |
| DOCCI_Test | 100 |
| LocNar_Eval | 1000 |
| CM_3600 | 1000 |
### 注释信息
#### 注释流程
部分文本描述由人工注释者撰写,部分则由机器学习模型生成。所有评测指标均基于人类并排对比得出。
### 个人与敏感信息说明
我们通过算法检测与人工审核的方式,对用于生成描述的图像及机器生成的文本描述进行了个人可识别信息(PII)、色情内容及暴力内容筛查,并过滤了所有疑似包含此类信息的样本。我们要求人工注释者在撰写图像描述时使用客观且尊重的语言。
### 许可信息
CC BY 4.0(知识共享署名4.0国际许可协议)
### 引用信息
@misc{garg2024imageinwords,
title={ImageInWords: Unlocking Hyper-Detailed Image Descriptions},
author={Roopal Garg and Andrea Burns and Burcu Karagol Ayan and Yonatan Bitton and Ceslee Montgomery and Yasumasa Onoe and Andrew Bunner and Ranjay Krishna and Jason Baldridge and Radu Soricut},
year={2024},
eprint={2405.02793},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
提供机构:
google
原始信息汇总
数据集概述
数据集名称
- 名称: ImageInWords (IIW)
- 别名: IIW
数据集描述
- 目的: 提供超详细图像描述,促进讨论和改进标注指南,以及开发自动度量标准以模拟人类并行判断。
- 组成: 由人类标注和模型输出两部分组成。
支持的任务
- 任务类型:
- 文本到图像
- 图像到文本
- 对象检测
语言
- 语言: 英语
数据集结构
- 数据实例:
- IIW-400: 包含图像键、图像URL、人类生成的图像描述、机器生成的图像描述及人类并行度量。
- DCI_Test: 包含图像、图像URL、人类编写的图像描述及度量。
- DOCCI_Test: 包含图像、缩略图URL、人类生成的图像描述、DOCCI生成的图像描述及度量。
- LocNar_Eval: 包含图像键、图像URL、机器生成的图像描述。
- CM_3600: 包含图像键、图像URL、机器生成的图像描述。
- 数据分割:
- IIW-400: 400个实例
- DCI_Test: 112个实例
- DOCCI_Test: 100个实例
- LocNar_Eval: 1000个实例
- CM_3600: 1000个实例
注释
- 注释过程: 文本描述部分由人类标注者编写,部分由机器模型生成。所有度量来自人类并行。
个人和敏感信息
- 信息处理: 图像和机器生成的文本描述经过算法和手动检查,过滤了可能包含个人和敏感信息、色情内容和暴力内容的部分。
许可信息
- 许可证: CC BY 4.0
引用信息
@misc{garg2024imageinwords, title={ImageInWords: Unlocking Hyper-Detailed Image Descriptions}, author={Roopal Garg and Andrea Burns and Burcu Karagol Ayan and Yonatan Bitton and Ceslee Montgomery and Yasumasa Onoe and Andrew Bunner and Ranjay Krishna and Jason Baldridge and Radu Soricut}, year={2024}, eprint={2405.02793}, archivePrefix={arXiv}, primaryClass={cs.CV} }
搜集汇总
数据集介绍
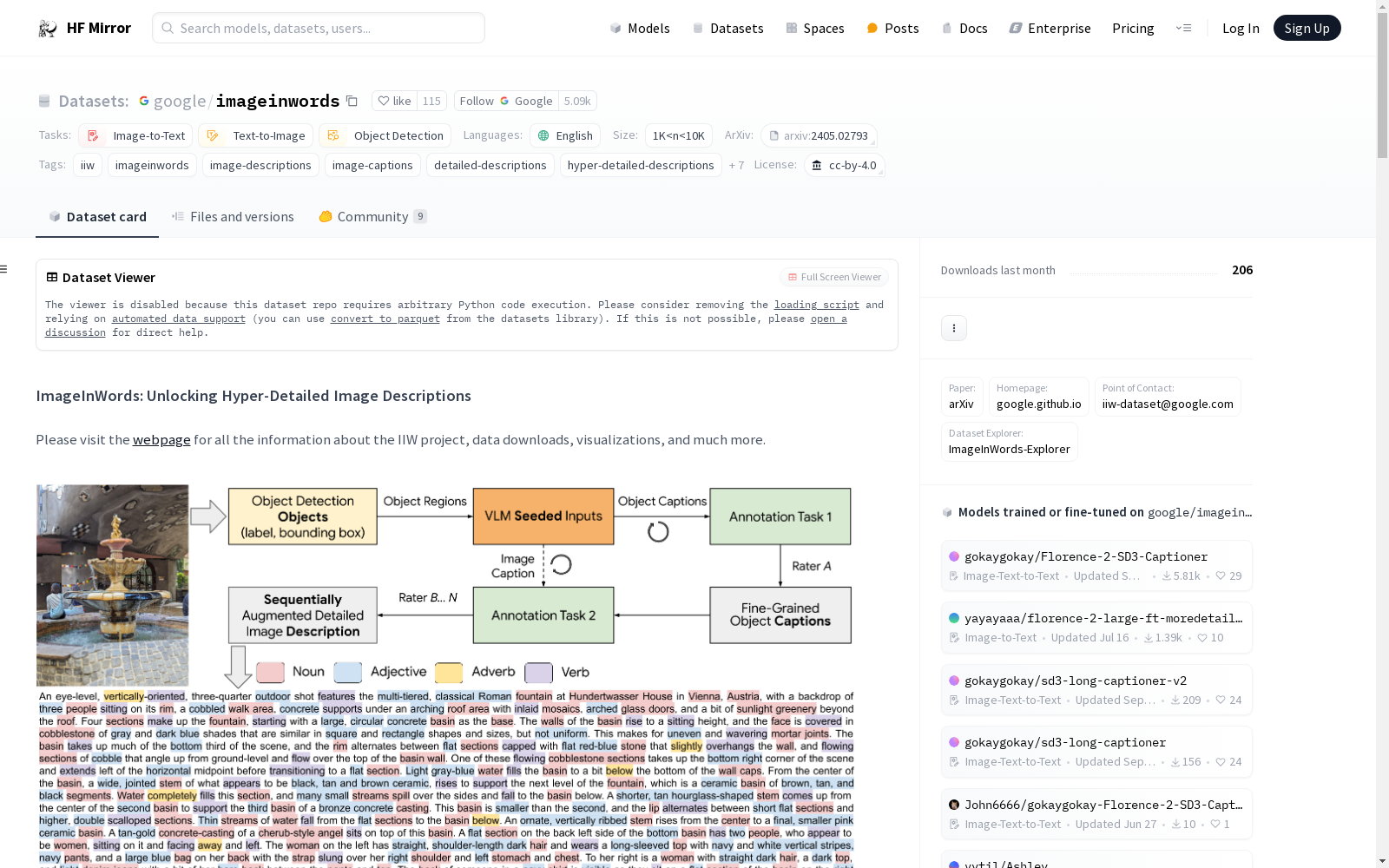
构建方式
ImageInWords(IIW)数据集的构建基于一个精心设计的人类参与的标注框架,旨在生成超详细的图像描述。该框架通过专家生成和众包的方式,结合机器生成的描述,形成了一个包含丰富细节的图像描述数据集。数据集的构建过程中,特别关注了描述的阅读性、全面性、特异性、幻觉现象以及人类相似性,以确保数据集的高质量。
特点
ImageInWords数据集的显著特点在于其超详细的图像描述,这些描述不仅由人类专家生成,还包括机器生成的描述,从而提供了多样化的视角和细节。此外,数据集还包含了人类并排(SxS)的评价指标,如全面性、特异性、幻觉现象等,这些指标有助于评估和改进描述的质量。
使用方法
使用ImageInWords数据集时,用户可以通过Hugging Face的datasets库加载数据集,选择不同的子集如IIW-400、DCI_Test等。每个子集包含图像的URL、人类生成的描述、机器生成的描述以及相关的评价指标。用户可以利用这些数据进行图像到文本、文本到图像以及对象检测等任务的模型训练和评估。
背景与挑战
背景概述
ImageInWords(IIW)数据集由Google的研究团队精心设计,旨在通过人机协作的标注框架生成超详细的图像描述。该数据集的核心研究问题在于如何通过高质量的标注提升图像描述的细节和准确性,从而推动图像与文本之间的深度理解和交互。IIW数据集的创建不仅填补了现有数据集在超详细描述方面的空白,还为图像描述生成模型的训练提供了宝贵的资源。其主要研究人员包括Roopal Garg、Andrea Burns等,他们的工作对计算机视觉和自然语言处理领域产生了深远影响。
当前挑战
ImageInWords数据集在构建过程中面临多项挑战。首先,如何确保人类标注者与机器生成描述之间的质量一致性是一个关键问题。其次,数据集的多样性和覆盖范围需要广泛,以确保模型在不同场景下的泛化能力。此外,评估图像描述的质量,特别是在可读性、全面性、特异性、幻觉和人类相似性方面的评估,也是一个复杂的过程。最后,数据集中涉及的敏感信息和隐私问题需要严格的管理和审查,以确保数据的安全性和合规性。
常用场景
经典使用场景
在图像描述生成领域,ImageInWords数据集以其超详细的图像描述而著称。该数据集的经典使用场景包括图像到文本(Image-to-Text)和文本到图像(Text-to-Image)的任务。通过提供人类专家和机器生成的详细描述,ImageInWords为研究人员和开发者提供了丰富的资源,用于训练和评估图像描述生成模型,特别是在需要高度细节和准确性的应用中。
解决学术问题
ImageInWords数据集解决了图像描述生成领域中常见的学术研究问题,如描述的详细性、准确性和人类相似性。通过提供人类专家和机器生成的详细描述,该数据集帮助研究人员评估和改进模型的描述能力,减少幻觉现象,并提高描述的全面性和特定性。这不仅推动了图像描述生成技术的发展,还为相关领域的研究提供了宝贵的基准数据。
衍生相关工作
基于ImageInWords数据集,许多相关工作得以展开,特别是在图像描述生成和评估领域。例如,研究人员利用该数据集开发了新的自动评估指标,以更好地模拟人类对图像描述的判断。此外,该数据集还促进了图像描述生成模型的改进,特别是在处理复杂场景和细节丰富的图像时。这些衍生工作不仅丰富了图像描述生成领域的研究,还为实际应用提供了技术支持。
以上内容由遇见数据集搜集并总结生成


