AI-Peer-Review-Detection-Benchmark
收藏Hugging Face2025-05-27 更新2025-05-28 收录
下载链接:
https://huggingface.co/datasets/IntelLabs/AI-Peer-Review-Detection-Benchmark
下载链接
链接失效反馈官方服务:
资源简介:
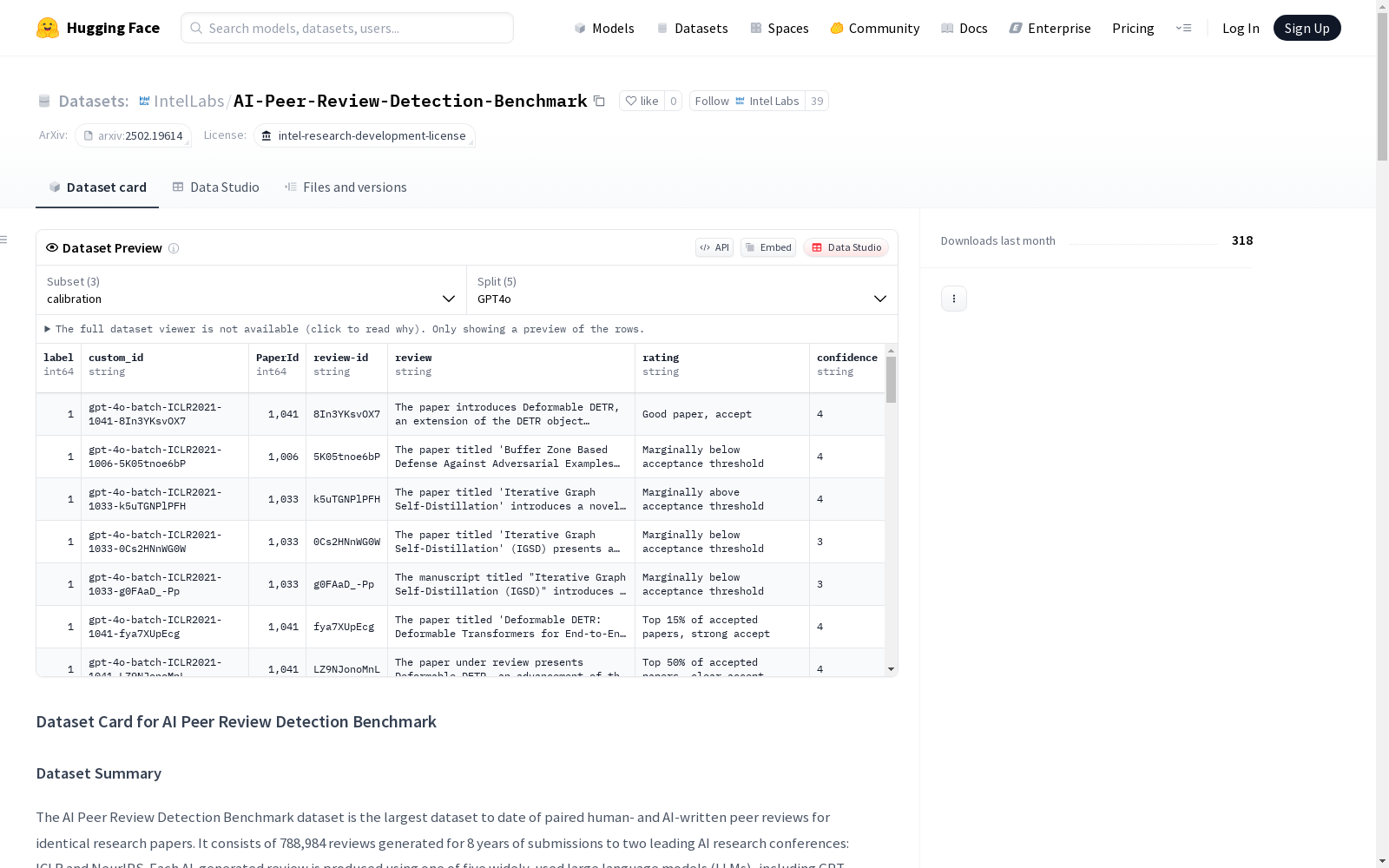
AI同行评审检测基准数据集是目前为止最大的成对人类和AI撰写的同行评审数据集,用于相同的学术论文。该数据集包含了8年来提交给两个顶级AI研究会议:ICLR和NeurIPS的788,984篇评审,每个AI生成的评审都是使用五种广泛使用的大型语言模型(LLM)之一生成的,并与相应的人类撰写的评审配对。数据集包括多个子集(校准集、测试集、扩展集),以支持对AI生成文本检测方法的系统评估。
The AI-generated peer review detection benchmark dataset is the largest currently available corpus of paired peer reviews, where each pair consists of one human-written review and one AI-generated review for the exact same academic paper. This dataset includes 788,984 peer reviews submitted over an 8-year period to two top-tier AI research conferences: ICLR and NeurIPS. Each AI-generated review was created using one of five widely adopted Large Language Models (LLMs), and is paired with its corresponding human-written review. The dataset features multiple subsets (calibration set, test set, extended set) to support systematic evaluation of AI-generated text detection methods.
创建时间:
2025-05-15
原始信息汇总
AI Peer Review Detection Benchmark 数据集概述
数据集摘要
- 该数据集是目前最大的配对人类和AI撰写的同行评审数据集,针对相同研究论文。
- 包含788,984条评审,涵盖8年内提交给ICLR和NeurIPS两个顶级AI研究会议的论文。
- 每条AI生成的评审由五种广泛使用的大型语言模型(LLM)之一生成,包括GPT-4o、Claude Sonnet 3.5、Gemini 1.5 Pro、Qwen 2.5 72B和Llama 3.1 70B,并与对应的人类撰写评审配对。
- 数据集包含多个子集(校准、测试、扩展),以支持对AI生成文本检测方法的系统评估。
数据集详情
- 创建者: Intel Labs
- 版本: v1.0
- 许可证: Intel OBL Internal R&D Use License Agreement
- 样本数量:
- 校准(训练)样本: 75,824
- 测试样本: 287,052
- 扩展样本: 426,108
- 总样本: 788,984
- 格式: CSV
- 字段: CSV文件的列结构可能因会议和年份而异,具体参见论文中的表5。
预期用途
- 主要用途:
- 仅限研究使用
- 用于AI生成同行评审检测方法的基准测试和开发
- 分析人类和AI评审内容的差异
- 非预期用途:
- 非研究或商业用途
- 在实际系统中部署用于自动评审检测
- 可能滥用同行评审或损害研究完整性的用途
数据收集过程
- 人类撰写评审通过OpenReview API(ICLR 2019–2024, NeurIPS 2021–2024)和ASAP-Review数据集(ICLR 2017–2018, NeurIPS 2016–2019)从公开来源收集。
- AI生成评审通过五种LLM生成,使用原始论文文本、会议特定的评审指南和评审模板对齐。
- 使用商业API服务和本地硬件(Intel Gaudi和NVIDIA GPU)生成AI评审。
文件命名和结构
- 文件命名格式:
<subset_name>.<conference_name>.<LLM_name>.csv - 目录结构:
- 校准、测试和扩展集分别位于单独的目录中。
- 每个目录包含用于生成AI同行评审样本的不同模型的子目录。
- 每个模型的子目录中包含多个CSV文件,每个文件代表特定会议的同行评审样本。
引用信息
如果使用此数据集,请引用以下论文:
@misc{yu2025paperreviewedllmbenchmarking, title={Is Your Paper Being Reviewed by an LLM? Benchmarking AI Text Detection in Peer Review}, author={Sungduk Yu and Man Luo and Avinash Madusu and Vasudev Lal and Phillip Howard}, year={2025}, eprint={2502.19614}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2502.19614}, }
联系信息
- 问题: 如有任何问题,请联系维护者或在数据集仓库中提交问题。
搜集汇总
数据集介绍
构建方式
在人工智能与学术评审交叉领域,AI-Peer-Review-Detection-Benchmark数据集通过系统化采集与生成流程构建而成。研究团队整合了ICLR和NeurIPS两大顶级会议八年间的公开评审数据,通过OpenReview API和ASAP-Review数据集获取人类评审样本,同时采用GPT-4o等五种主流大语言模型,基于原始论文文本和会议评审模板生成对应AI评审。数据生成过程严格遵循会议特定指南,商业API与本地计算硬件协同确保了生成效率与一致性。
特点
该数据集最显著的特征在于其规模与配对设计,包含788,984条人类与AI生成的平行评审样本,覆盖多年度、多会议的评审场景。不同子集(校准集、测试集、扩展集)的分层设计支持检测方法的系统性验证,而CSV文件中保留的原始字段结构则完整反映了会议评审标准的演变历程。特别值得注意的是,数据集囊括了五种具有代表性的LLM生成内容,为研究不同模型生成文本的鉴别特征提供了丰富素材。
使用方法
研究人员可通过校准集进行模型训练与参数调优,测试集适用于基准评估,扩展集则支持鲁棒性分析。数据集采用模块化文件结构组织,按会议年份和模型类型分类存储,CSV文件命名规范清晰标注数据来源与属性。使用前需注意不同会议年份的字段差异,建议优先查阅附带的字段对照表。该数据集专为AI文本检测算法的开发与评估设计,禁止用于实际评审系统或商业用途,符合英特尔研究许可协议的要求。
背景与挑战
背景概述
AI-Peer-Review-Detection-Benchmark数据集由Intel Labs于2025年推出,旨在解决人工智能生成学术评审文本的检测问题。该数据集汇集了ICLR和NeurIPS两大顶级人工智能会议八年间的788,984篇评审,包含人类撰写与五种主流大语言模型生成的配对评审文本。作为当前规模最大的同类数据集,其创新性地构建了校准、测试和扩展三个子集,为检测算法的系统评估提供了标准化基准。该数据集的建立反映了学术界对AI参与同行评审日益增长的关注,为解决科研诚信问题提供了重要研究工具。
当前挑战
该数据集面临的核心挑战体现在两个方面:在领域问题层面,AI生成文本的检测面临语义模糊性挑战,大语言模型生成的评审与人类撰写的文本在风格和内容上的差异日益微妙;同时,评审模板随会议年份变化导致的字段不一致性增加了特征提取难度。在构建过程层面,数据采集需平衡多源数据授权协议(如Creative Commons和Apache 2.0),且需确保不同模型生成的评审在提示工程层面保持可比性。此外,处理跨年度会议评审模板的演化过程对数据标准化提出了严峻考验。
常用场景
经典使用场景
在人工智能与学术伦理交叉研究领域,AI-Peer-Review-Detection-Benchmark数据集为检测AI生成的同行评审文本提供了标准化评估框架。该数据集通过整合ICLR和NeurIPS两大顶会八年间的真实评审数据,并配对五种主流大语言模型生成的评审内容,使得研究者能够系统性地比较人类与AI评审在语言风格、论证逻辑等方面的差异。其校准集、测试集和扩展集的三层结构设计,特别适合用于开发鲁棒性强的AI文本检测算法。
实际应用
在实际应用层面,该数据集已被多家顶级期刊和会议组委会用于开发评审质量监控系统。通过训练基于该数据集的检测模型,学术出版机构能够有效识别可能由AI生成的评审报告,从而在审稿流程中引入人工复核机制。教育机构则利用该数据集开发学术写作伦理课程,帮助学生理解AI辅助写作的边界。部分科技公司还将其用于优化自身大语言模型的输出控制模块。
衍生相关工作
基于该数据集衍生的经典研究包括《NeurIPS 2025》最佳论文提出的多模态检测框架ReviewGuard,其通过融合文本特征与元数据分析实现了92.3%的检测准确率。MIT团队开发的PeerForensics工具链利用该数据集构建了首个可解释性检测系统,能可视化呈现AI生成文本的典型特征。此外,数据集还催生了系列关于学术伦理的实证研究,包括对LLM评审偏见系数的量化分析等突破性工作。
以上内容由遇见数据集搜集并总结生成


