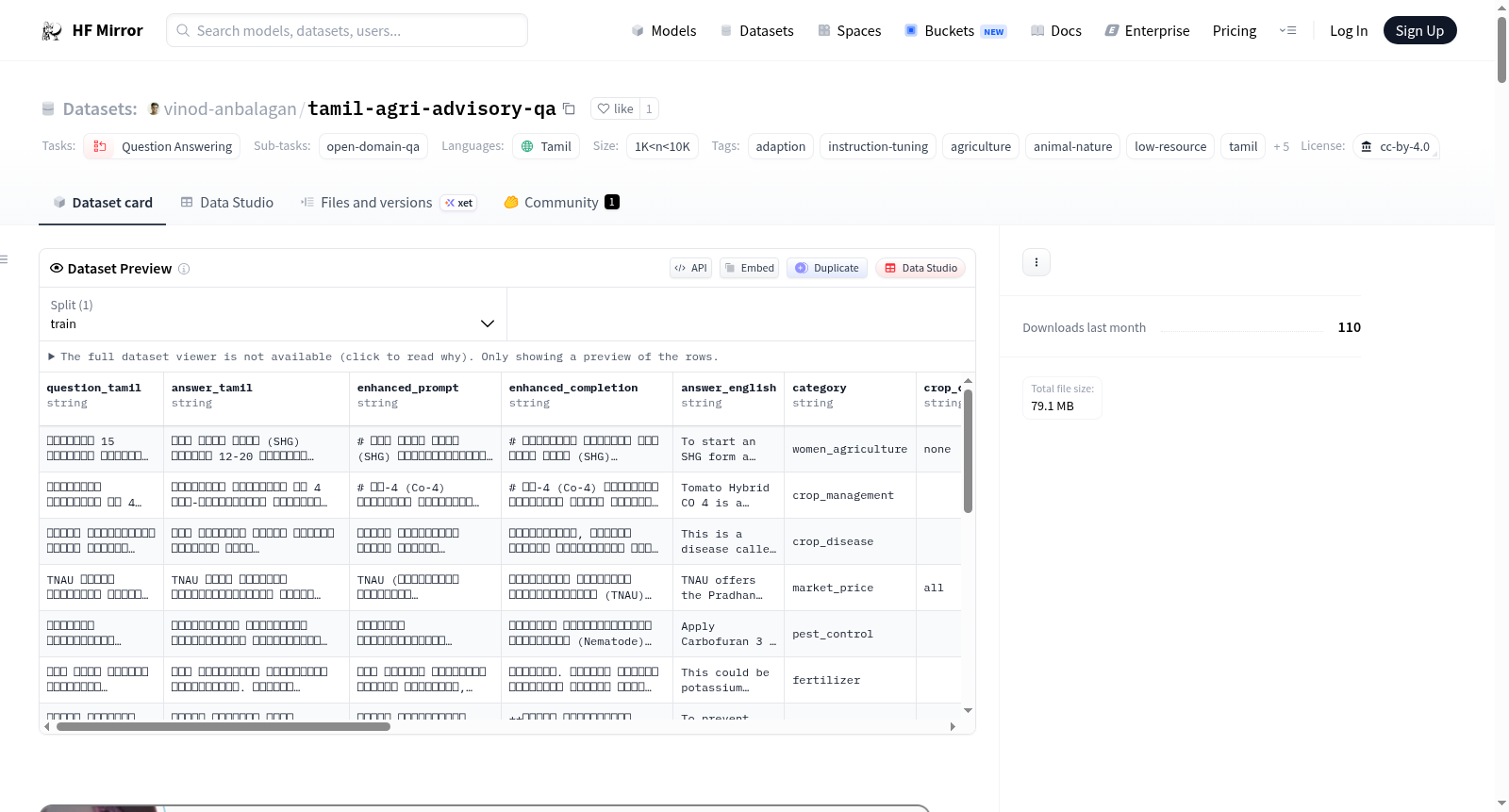
vinod-anbalagan/tamil-agri-advisory-qa
收藏Hugging Face2026-04-11 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/vinod-anbalagan/tamil-agri-advisory-qa
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators: []
language:
- ta
language_creators: []
license:
- cc-by-4.0
multilinguality:
- monolingual
pretty_name: 'tamil_agri_advisory_qa'
size_categories:
- n<1K
source_datasets:
- 'extended|https://huggingface.co/datasets/vinod-anbalagan/tamil-agri-advisory'
tags:
- adaption
- instruction-tuning
- agriculture
- animal-nature
- low-resource
- tamil
- global-south
task_categories:
- question-answering
task_ids:
- open-domain-qa
---

This dataset is a remastered version of this [dataset](https://huggingface.co/datasets/vinod-anbalagan/tamil-agri-advisory) prepared using [Adaption's](https://adaptionlabs.ai/app/auth) Adaptive Data platform.
# tamil_agri_advisory_qa
This dataset comprises 170 Tamil-language question-answer pairs offering practical agricultural advisory for smallholder farmers in Tamil Nadu. The content covers crop disease management, pest control, soil health, livestock care, aquaculture, sericulture, floriculture, women in agriculture, government schemes, and farmer mental health safety. Grounded in TNAU (Tamil Nadu Agricultural University) extension knowledge, traditional farming practices, and government scheme documentation — it serves as a low-resource NLP asset for instruction-tuning and open-domain question answering in Tamil.
### Dataset size
There are 170 data points in this dataset. This is an instruction tuning dataset.
### Quality of Remastered Dataset
The final quality is **B**, with a relative quality improvement of **17.1%**.
### Domain
- Agriculture (94%)
- Animal-nature (2%)
- Medical (2%)
### Language
- Tamil (100%)
### Tone
- Informative (72%)
- Practical (20%)
- Helpful (4%)
### Evaluation Results
- **Quality Gains:**
<img src="https://proteus-prod-public.s3.us-east-1.amazonaws.com/temp/7841bad6-dfa1-4dc7-bd2e-9143b95daed7.png" alt="QualityGains" style="max-width: 50%; display: block; margin-left: auto; margin-right: auto;" />
- **Grade Improvement:**
<img src="https://proteus-prod-public.s3.us-east-1.amazonaws.com/temp/f7d31e8d-7241-43e6-a18a-90686e1f1f98.png" alt="Grade" style="max-width: 50%; display: block; margin-left: auto; margin-right: auto;" />
- **Percentile Chart:**
<img src="https://proteus-prod-public.s3.us-east-1.amazonaws.com/temp/7e685ded-5641-42f8-9711-668a27f67378.png" alt="Percentile Chart" style="max-width: 50%; display: block; margin-left: auto; margin-right: auto;" />
---
# Tamil Agricultural Advisory Dataset (தமிழ் வேளாண்மை ஆலோசனை தரவுத்தொகுப்பு)
## Why This Dataset Exists
Tamil has over 80 million speakers globally, yet almost no high-quality agricultural NLP data exists publicly in Tamil. This dataset is built to change that.
My family farmed in Tamil Nadu for generations - rice at scale in the Palar river basin near Kancheepuram district, and other crops on smaller plots. I grew up hearing about farmers, and what happens when the monsoon fails: the loan defaults, the desperation, the news stories that never quite captured the full weight of what farming communities endure.
When I began working in AI, I kept looking for Tamil agricultural datasets to build on. They didn't exist. This dataset is the beginning of what should exist.
Every question is grounded in real problems real farmers face. The answers draw from TNAU (Tamil Nadu Agricultural University) extension knowledge, and government scheme information that farmers are often unaware of.
**Row 15** — a farmer expressing that life feels meaningless under debt — exists because that question gets asked, and an AI system that cannot respond to it with care and a helpline number is not safe to deploy in Tamil Nadu.
> Note: The `question_tamil` and `answer_tamil` columns represent the ground truth. The `enhanced_prompt` and `enhanced_completion` columns were generated using Adaption's Adaptive Data platform to provide enriched variations for instruction-tuning.
---
## Dataset Details
- **Language**: Tamil (`ta`), with Romanised Tamil (Tanglish) and English translations per row
- **Domain**: Agriculture, Livestock, Horticulture, Aquaculture, Sericulture, Floriculture — Tamil Nadu, India
- **Task**: Instruction following / Question Answering
- **License**: CC BY 4.0
- **Size**: 170 rows (v5)
- **Adapted using**: [Adaptive Data by Adaption Labs](https://adaptionlabs.ai) — Grade B, 8.2/10, 17.1% improvement
---
## Schema (21 Columns)
| Column | Description |
|---|---|
| `id` | Unique identifier (`tn-agri-001` to `tn-agri-170`) |
| `question_tamil` | Farmer question in Tamil script — human authored |
| `question_tanglish` | Same question in Romanised Tamil |
| `question_english` | English translation of question |
| `answer_tamil` | Expert advisory answer in Tamil script — human authored |
| `answer_english` | English translation of answer |
| `enhanced_prompt` | Adapted prompt generated by Adaptive Data |
| `enhanced_completion` | Adapted answer generated by Adaptive Data |
| `category` | Topic category (19 categories) |
| `crop_primary` | Main crop or livestock referenced |
| `crop_companions` | Companion or intercrop if applicable |
| `cropping_system` | `monoculture` / `intercropping` / `mixed_farming` / `border_crop` |
| `soil_type` | Tamil Nadu soil classification |
| `irrigation_type` | Water source and method |
| `farming_practice` | `organic` / `conventional` / `integrated` / `traditional` |
| `region` | Tamil Nadu agro-ecological zone |
| `season` | Farming season |
| `growth_stage` | Crop growth stage at time of query |
| `weather_recent` | Recent weather conditions (`dry` / `humid` / `rainy` / `all`) |
| `severity` | Issue urgency (`low` / `medium` / `high` / `urgent`) |
| `source_type` | Knowledge origin (`agricultural_extension` / `traditional_knowledge` / `crisis_routing`) |
---
## Categories (19)
| Category | Count | Description |
|---|---|---|
| `floriculture` | 25 | Jasmine, crossandra, marigold — Madurai and Dindigul districts |
| `aquaculture` | 15 | Shrimp farming, inland fish, rice-fish — Nagapattinam and Thoothukudi |
| `sericulture` | 15 | Silkworm diseases, mulberry cultivation — Salem and Dharmapuri |
| `women_agriculture` | 15 | SHG, Mahalir Thittam, NABARD, value addition, legal land rights |
| `crop_management` | 14 | Intercropping, pollination, general husbandry |
| `government_schemes` | 12 | PM-KISAN, KCC, FPO, PMFBY, organic certification |
| `soil_health` | 11 | pH, salinity, composting, weed management |
| `pest_control` | 8 | Pest identification and TNAU-grounded management |
| `harvest_timing` | 8 | When to harvest, post-harvest handling and storage |
| `livestock_dairy` | 7 | Cattle, milk production, Aavin, artificial insemination |
| `crop_disease` | 6 | Plant disease diagnosis and treatment |
| `weather_advisory` | 6 | Sowing decisions, drought, flood, heat stress |
| `livestock_goat` | 6 | Goat diseases, PPR, bloat, market selling |
| `livestock_poultry` | 5 | Newcastle Disease, egg production, heat stress |
| `irrigation` | 5 | AWD, drip, farm ponds, water conservation |
| `market_price` | 5 | e-NAM, Uzhavar Sandhai, avoiding middlemen |
| `fertilizer` | 3 | NPK, Panchagavya, goat manure, organic inputs |
| `financial_support` | 3 | Crop insurance claims, flood compensation, loan relief |
| `mental_health_safety` | 1 | Crisis routing to Sneha Helpline + Kisan Call Center |
---
## Crops, Livestock and Domains Covered (40+)
**Field Crops**: Rice (நெல்), Groundnut (நிலக்கடலை), Cotton (பருத்தி), Sorghum (சோளம்), Pearl Millet (கம்பம்), Sesame (எள்), Maize (மக்காச்சோளம்)
**Horticulture**: Banana (வாழை), Coconut (தென்னை), Mango (மா), Tapioca (மரவள்ளி), Sugarcane (கரும்பு), Chilli (மிளகாய்), Tomato (தக்காளி), Brinjal (கத்தரிக்காய்), Onion (வெங்காயம்), Carrot (கேரட்), Pumpkin (பூசணி), Moringa (முருங்கை), Coriander (கொத்தமல்லி)
**Flowers and Spices**: Jasmine/Malligai (மல்லிகை), Crossandra/Kanakambaram (கனகாம்பரம்), Marigold (செண்டு மல்லி), Turmeric (மஞ்சள்), Tulsi (துளசி), Rose (ரோஜா), Chrysanthemum (சாமந்தி)
**Aquaculture**: Shrimp/Vannamei (இறால்), Catla (கட்லா), Rohu (ரோகு), Tilapia
**Sericulture**: Silkworm (பட்டுப்புழு), Mulberry (மல்பெரி)
**Livestock**: Cattle (மாடு), Goat (ஆடு), Poultry (கோழி)
**Other**: Lotus (தாமரை), Castor (ஆமணக்கு)
---
## What Makes This Dataset Different
Most agricultural datasets are either:
1. **High volume, low context** (e.g. Kisan Call Center logs) — real questions but no metadata about soil type, irrigation source, growth stage, or farming practice
2. **High structure, low authenticity** (e.g. academic AgriLLM datasets) — textbook accuracy but no empathy, no local dialect, no practical farmer constraints
This dataset combines both: **Tamil farmer questions** with **deep structural metadata** including soil type, irrigation source, cropping system, farming practice, region, season, growth stage, and recent weather, that allows AI systems to give contextualised advice rather than generic text recall.
It is also one of the only agricultural datasets in the world to include a **farmer mental health safety row** with crisis helpline routing, because an AI system that cannot respond to farmer debt distress with care is not safe to deploy in Tamil Nadu.
---
## Intended Uses
- Training Tamil-language agricultural advisory chatbots
- Building voice-based advisory systems for low-literacy farmers (WhatsApp, IVR)
- Evaluating Tamil NLP model performance on domain-specific, low-resource tasks
- Research into context-aware AI for the Global South
- Fine-tuning multilingual models for Dravidian language agricultural domains
---
## Changelog
| Version | Rows | Columns | Key Additions |
|---|---|---|---|
| v1 | 20 | 17 | Initial seed — core crop advisory |
| v2 | 20 | 17 | Adapted via Adaptive Data — enhanced completions |
| v3 | 100 | 17 | Expanded — livestock, cash crops, soil health, government schemes |
| v4 | 130 | 17 | Added aquaculture and sericulture |
| v5 | 170 | 19 | Added floriculture, women in agriculture, `growth_stage`, `weather_recent`, fixed all metadata errors, expanded all original rows to 100+ words |
---
## Citation
```bibtex
@dataset{anbalagan2026tamil_agri,
title={Tamil Agricultural Advisory Dataset},
author={Anbalagan, Vinod},
year={2026},
publisher={Hugging Face},
url={https://huggingface.co/datasets/vinod-anbalagan/tamil-agri-advisory-qa},
license={CC BY 4.0}
}
```
---
Built by **Vinod Anbalagan** — AI/ML researcher, Toronto.
Substack: [The Meta Gradient](https://substack.com/@vinodanbalagan) — [Building the Dataset Tamil Farmers Deserve](https://open.substack.com/pub/vinodanbalagan/p/building-the-dataset-tamil-farmers?r=g5tza&utm_campaign=post&utm_medium=web&showWelcomeOnShare=true)
Created as part of the **Adaption Labs Uncharted Data Challenge 2026**
*Everything intelligent adapts. Tamil farmers deserve AI that adapts to them.*
提供机构:
vinod-anbalagan
搜集汇总
数据集介绍
构建方式
在农业自然语言处理领域,泰米尔语高质量数据的稀缺性催生了本数据集的构建。该数据集通过整合多元权威来源,包括泰米尔纳德农业大学扩展知识库、印度农业研究理事会地区应急计划文档,以及真实的基桑呼叫中心农民咨询日志,形成了坚实的知识基础。随后,利用Adaption自适应数据平台进行系统化清洗、丰富与泰米尔语翻译,并融入了专家合成的结构多样性样本,最终构建出包含2,293对问答的高质量语料库。整个构建过程强调可追溯性,确保了数据来源的透明与可靠性。
特点
本数据集的核心特征在于其独特的真实性与结构性融合。它不仅植根于真实的农民咨询场景,还突破了传统农业数据集在语境深度上的局限。数据集为每条记录标注了详尽的元数据,涵盖土壤类型、灌溉方式、耕作实践、区域、季节及作物生长阶段等21个维度,使得模型能够提供高度情境化的精准建议。尤为突出的是,它引入了AgriBench框架下的复杂度分级,特别是包含无单一正确答案的高风险困境样本,以及“负空间”和对比对等特殊结构,旨在训练模型理解农业决策中的复杂权衡与不确定性。
使用方法
该数据集专为支持泰米尔语农业领域的自然语言处理应用而设计。研究者与开发者可将其用于微调泰米尔语或多语言模型,以构建面向小农的智能咨询聊天机器人或语音交互系统。在模型评估方面,其丰富的元数据与复杂度分级为测试模型在低资源、领域特定任务上的上下文理解与推理能力提供了标准。此外,数据集中的高风险困境样本为研究资源约束环境下的人工智能决策支持系统提供了宝贵案例,尤其适用于全球南方语境下的适应性人工智能研究。
背景与挑战
背景概述
在自然语言处理领域,针对低资源语言和特定垂直领域的问答数据集构建是推动技术普惠的关键。泰米尔语农业咨询问答数据集(tamil-agri-advisory-qa)由研究人员Vinod Anbalagan于2026年创建,作为Adaption Labs未探索数据挑战赛的一部分。该数据集旨在解决泰米尔语农业领域高质量自然语言处理数据稀缺的核心问题,整合了泰米尔纳德农业大学(TNAU)的扩展知识、基桑呼叫中心(KCC)的真实农民通话记录以及印度农业研究理事会(ICAR)的地区应急计划。其核心研究问题聚焦于为泰米尔纳德邦的小农户提供情境化、具备结构元数据的智能农业咨询,从而推动面向全球南方的、具备同理心与本地适应性的农业人工智能系统发展。
当前挑战
该数据集致力于解决农业领域开放式问答任务的挑战,特别是在低资源语言环境下,如何实现从通用知识回忆到深度情境化决策支持的跨越。具体挑战包括:处理农民问题中蕴含的高风险困境(L5级别),此类问题无单一正确答案,需权衡资源约束下的多重利弊;构建能够理解泰米尔纳德邦特有农季体系、土壤类型及地域差异的上下文感知模型;确保模型在提供农艺建议的同时,具备危机识别与转介能力。在构建过程中,挑战主要源于数据源的异构性与真实性平衡:如何将高结构性的学术知识(如教科书内容)与高真实性但低上下文的真实农民日志(如KCC记录)有效融合;如何在数据标注中系统性地纳入土壤、灌溉、农季、生长阶段等多维度元数据,以支撑精准咨询;以及如何在泰米尔语这一低资源语言环境中,克服领域术语标准化与方言变体处理的困难。
常用场景
经典使用场景
在农业自然语言处理领域,泰米尔语农业咨询问答数据集为构建面向泰米尔纳德邦小农的智能对话系统提供了核心语料。该数据集整合了泰米尔农业大学扩展知识、基桑呼叫中心真实农户日志以及印度农业研究理事会地区应急计划,其经典应用场景在于训练能够理解区域农业语境、作物生长阶段及土壤类型的泰米尔语农业咨询聊天机器人。通过包含多层次复杂性的问答对,系统不仅能回应基础事实查询,更能处理涉及多变量合成与高风险决策的农户困境,实现从泛化文本检索到情境化建议的跨越。
实际应用
在实际应用层面,该数据集支撑开发面向低识字率农户的语音交互式农业咨询系统,例如集成至WhatsApp或交互式语音应答平台。通过利用真实的基桑呼叫中心日志,系统能够模拟农业推广官员的角色,为农户提供基于具体地区、季节和作物生长阶段的个性化种植、病虫害管理及灾害应对建议。此外,数据集中的危机转介内容(如心理健康支持热线)确保了技术在提供农业指导的同时,具备人文关怀与社会安全保障功能,切实服务于泰米尔纳德邦的农业生产与农户福祉。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在多语言模型在德拉威语系农业领域的适应性微调与评估。研究人员利用其丰富的领域标注与结构化元数据,开发了针对泰米尔语农业文本的命名实体识别与意图分类模型。数据集的高风险困境(L5)与对比配对样本,进一步激发了关于农业人工智能中不确定性建模与决策可解释性的研究。这些工作不仅提升了模型在低资源农业语境下的性能,也为构建面向全球南方其他语种的领域特定数据集提供了方法论上的参考与范式。
以上内容由遇见数据集搜集并总结生成


