protein-secondary-structure-nppe2
收藏Hugging Face2026-05-25 更新2026-05-26 收录
下载链接:
https://huggingface.co/datasets/lamm-mit/protein-secondary-structure-nppe2
下载链接
链接失效反馈官方服务:
资源简介:
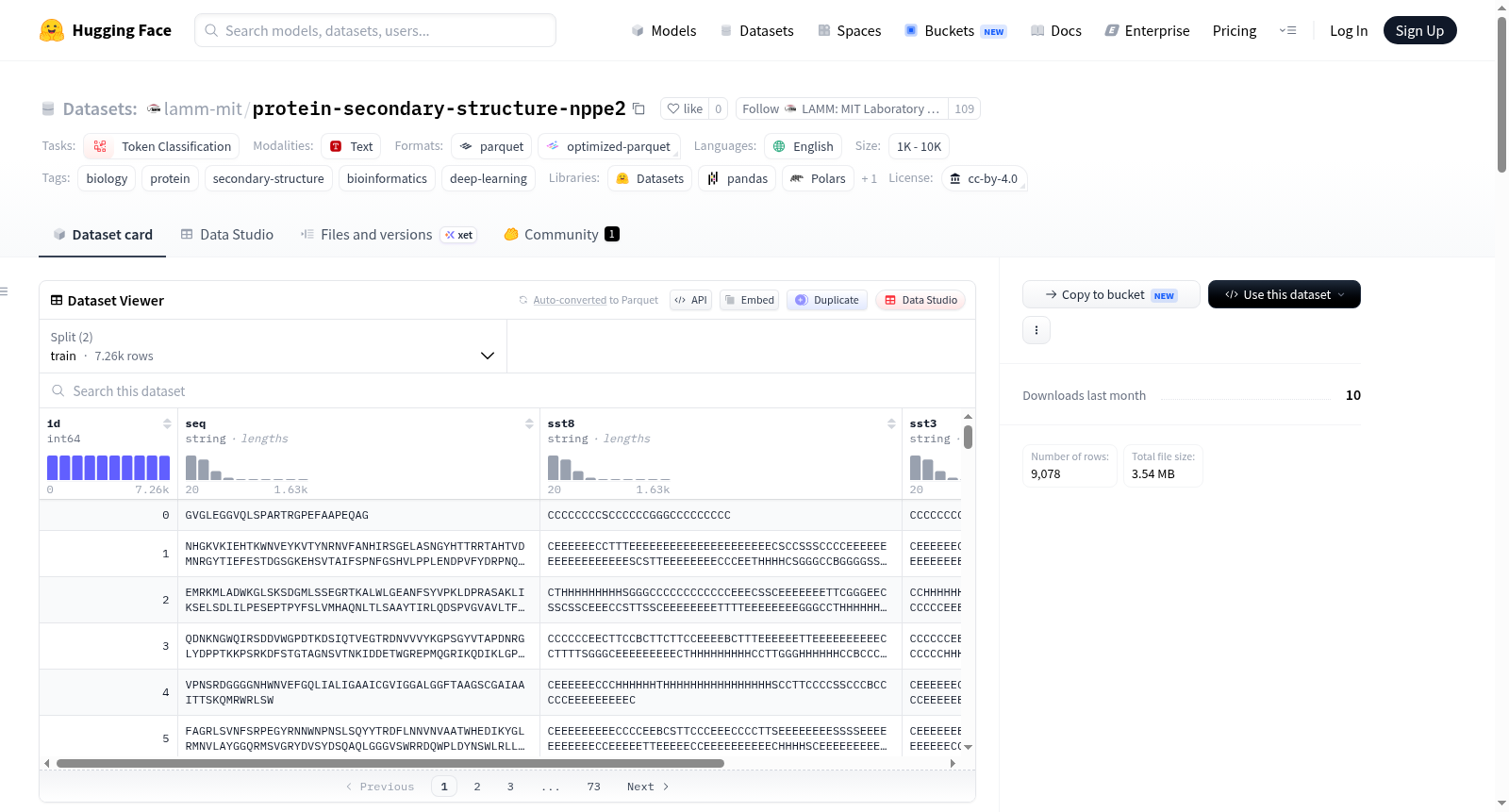
该数据集名为蛋白质二级结构预测数据集(NPPE-2),用于印度理工学院马德拉斯分校深度学习与生成AI课程中的蛋白质二级结构预测竞赛。其主要任务是在残基水平预测蛋白质的二级结构,采用两种分类体系:八态分类(Q8/sst8,基于DSSP符号,包括H(α螺旋)、C(卷曲/环)、E(β链)、T(转角)、S(弯曲)、G(3-10螺旋)、B(β桥)和I(π螺旋))和三态分类(Q3/sst3,将八态归类为C(卷曲,包含C、T、S)、H(螺旋,包含H、G、I)和E(链,包含E、B))。评估指标为Q8和Q3宏F1分数的调和平均数。数据集包含训练集(7,262个蛋白质序列,共1,763,921个残基)和测试集(1,816个序列,标签未提供)。序列长度范围为20至1,632个残基,平均长度为242.9个残基。标签分布显示,在Q8分类中,H(α螺旋)占比最高(31.6%),其次是C(24.2%)和E(21.0%);在Q3分类中,C(卷曲)占比最高(42.6%),其次是H(螺旋,35.4%)和E(链,22.1%)。数据以CSV文件形式组织,训练集文件包含id(唯一序列标识符)、seq(由20种标准氨基酸组成的序列)、sst8(Q8标签)和sst3(Q3标签)四列;测试集文件包含id和seq两列。该数据集适用于标记分类任务,特别是在生物信息学和深度学习领域用于蛋白质结构预测研究。
This dataset is named the Protein Secondary Structure Prediction Dataset (NPPE-2), used for a protein secondary structure prediction competition in the Deep Learning and Generative AI course at the Indian Institute of Technology Madras. Its main task is to predict protein secondary structure at the residue level, employing two classification systems: an eight-state classification (Q8/sst8, based on DSSP symbols, including H (α-helix), C (coil/loop), E (β-strand), T (turn), S (bend), G (3-10 helix), B (β-bridge), and I (π-helix)) and a three-state classification (Q3/sst3, which groups the eight states into C (coil, including C, T, S), H (helix, including H, G, I), and E (strand, including E, B)). The evaluation metric is the harmonic mean of the macro F1 scores for Q8 and Q3. The dataset includes a training set (7,262 protein sequences, totaling 1,763,921 residues) and a test set (1,816 sequences, labels not provided). The sequence length ranges from 20 to 1,632 residues, with an average length of 242.9 residues. Label distribution shows that in the Q8 classification, H (α-helix) has the highest proportion (31.6%), followed by C (24.2%) and E (21.0%); in the Q3 classification, C (coil) has the highest proportion (42.6%), followed by H (helix, 35.4%) and E (strand, 22.1%). The data is organized in CSV files: the training set file contains four columns—id (unique sequence identifier), seq (sequence composed of 20 standard amino acids), sst8 (Q8 label), and sst3 (Q3 label); the test set file contains two columns—id and seq. This dataset is suitable for token classification tasks, particularly for protein structure prediction research in bioinformatics and deep learning.
提供机构:
LAMM: MIT Laboratory for Atomistic and Molecular Mechanics
创建时间:
2026-05-25
搜集汇总
数据集介绍
构建方式
该数据集源自印度马德拉斯理工学院深度学习与生成式人工智能课程的蛋白质二级结构预测竞赛,旨在为残基层面的结构分类提供基准数据。数据集包含训练集与测试集,分别涵盖7,262条和1,816条蛋白质序列,总氨基酸残基数超过176万。序列长度分布在20至1,632个残基之间,平均长度为242.9个残基。数据以CSV格式存储,训练集提供序列标识符、氨基酸序列、Q8八态标签和Q3三态标签,而测试集仅包含序列信息用于评估。
特点
数据集的核心特色在于其双重标签体系,同时支持Q8八态与Q3三态二级结构分类,便于研究者从精细或粗粒度视角分析蛋白质构象。Q8标签严格遵循DSSP注释标准,涵盖α螺旋、β折叠、卷曲等八种结构状态,其中α螺旋占比31.6%,卷曲占24.2%,β折叠占21.0%。Q3标签则将结构归纳为卷曲、螺旋和链状三类,分布比例分别为42.6%、35.4%和22.1%,可用于简化模型任务。这种分层标注设计显著提升了数据集的灵活性与应用范围。
使用方法
使用该数据集时,可借助HuggingFace的datasets库直接加载,命令为`load_dataset("neuralninja110/protein-secondary-structure-nppe2")`,从而获取训练和测试数据。训练数据中,氨基酸序列以20种标准残基表示,对应的sst8和sst3列携带结构标签,适用于序列标注模型(token-classification)的构建与训练。模型性能通过Q8与Q3宏F1分数的调和均值进行综合评价,确保预测质量在两种分类粒度上达到平衡。此外,数据集提供了样本提交格式,便于竞赛场景下的标准化输出。
背景与挑战
背景概述
蛋白质二级结构预测作为计算生物学与生物信息学领域的核心任务之一,旨在从氨基酸序列推断蛋白质局部的空间构象,为理解蛋白质功能、药物设计及疾病机理研究奠定基础。该数据集由印度理工学院马德拉斯分校的Rahul Ashok于2025年创建,源自深度学习与生成式人工智能课程竞赛,聚焦于残基级别的二级结构分类任务。数据集涵盖Q8(八态)与Q3(三态)两种标注体系,包含7262条训练序列及1816条测试序列,序列长度横跨20至1632个残基,确保了序列多样性与学习复杂性。其设计紧密围绕深度学习方法在蛋白质结构预测中的前沿应用,通过定义宏观F1分数的调和均值作为评价指标,为模型泛化能力与多类别平衡性提出了高要求。该数据集为蛋白质序列表征学习与结构预测研究提供了标准化基准,推动了以数据驱动方式探索序列-结构映射机制的学术进展。
当前挑战
数据集相关的挑战涵盖多个层面。从领域问题来看,蛋白质二级结构预测面临的核心挑战在于氨基酸序列与结构之间复杂的非线性映射关系,尤其是稀有结构类型(如Pi螺旋占比不足0.1%)的准确识别与长程依赖关系的建模,使得模型极易受到类别不平衡与序列长度变化的影响。构建过程中,原始序列需从PDB等数据库提取并经过严格的同源性削减以避免过拟合,同时Q8标签的精细化分类要求对DSSP算法输出进行精准解析和质量控制。此外,氨基酸序列长度差异悬殊(最小20残基,最大1632残基)给模型设计与批处理策略带来了技术困难。测试集标签的缺失进一步增加了对模型泛化性能评估的挑战,要求研究者开发稳定可靠的跨序列预测方案。
常用场景
经典使用场景
在蛋白质功能与结构生物学研究中,精准解析蛋白质的局部构象是理解其生物学功能的核心任务之一。该数据集专为残基级别的蛋白质二级结构预测任务而设计,通过提供氨基酸序列与其对应的二级结构标签,支持研究者构建并训练深度学习模型,从而自动从一维序列中推断出每个氨基酸残基所属的二级结构类别。用户可基于该数据集进行序列到序列的标记分类任务,并同时利用其提供的Q8八态分类与Q3三态分类双标准体系,全面评估模型在不同精细度下的预测表现。这一经典使用范式已成为计算生物学中序列结构映射研究的标准基准。
实际应用
在实际应用中,该数据集所驱动的预测模型可被部署于药物研发与生物工程领域,例如辅助识别靶标蛋白的活性位点构象,加速基于结构的药物分子设计流程。此外,在合成生物学中,通过对设计蛋白序列的二级结构进行快速验证,研究者得以高效筛选具有预期折叠模式的人工酶或抗体片段。该数据集还为生物信息学平台中的自动化注释工具提供了模型训练基础,使得大规模基因组测序数据中的蛋白结构注释实现高通量与低成本化,有力支撑了精准医学与个性化诊疗的发展需求。
衍生相关工作
该数据集的设计理念与评价指标直接催生了一系列衍生研究,包括利用卷积神经网络(CNN)、循环神经网络(RNN)以及近年兴起的Transformer架构对序列结构映射关系进行建模的经典工作。研究者基于该数据集的Q8与Q3双任务联合优化框架,提出了多种多任务学习策略,如共享编码器配合任务特异性解码器的架构,进一步提升了预测性能。此外,该数据集还促进了注意力机制、自监督预训练(如ESM、ProtBERT)等前沿技术在二级结构预测领域的适配与验证,成为连接传统序列特征工程与现代深度表示学习的桥梁性基准资源。
以上内容由遇见数据集搜集并总结生成


