goendalf666/sales-conversations-2
收藏Hugging Face2023-10-04 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/goendalf666/sales-conversations-2
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
features:
- name: '0'
dtype: string
- name: '1'
dtype: string
- name: '2'
dtype: string
- name: '3'
dtype: string
- name: '4'
dtype: string
- name: '5'
dtype: string
- name: '6'
dtype: string
- name: '7'
dtype: string
- name: '8'
dtype: string
- name: '9'
dtype: string
- name: '10'
dtype: string
- name: '11'
dtype: string
- name: '12'
dtype: string
- name: '13'
dtype: string
- name: '14'
dtype: string
- name: '15'
dtype: string
- name: '16'
dtype: string
- name: '17'
dtype: string
- name: '18'
dtype: string
- name: '19'
dtype: string
splits:
- name: train
num_bytes: 6821725
num_examples: 3412
download_size: 2644154
dataset_size: 6821725
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "sales-conversations-2"
# Dataset Card for "sales-conversations"
This dataset was created for the purpose of training a sales agent chatbot that can convince people.
The initial idea came from: textbooks is all you need https://arxiv.org/abs/2306.11644
gpt-3.5-turbo was used for the generation
See the main model or github for more information
salesGPT_v2: https://huggingface.co/goendalf666/salesGPT_v2
github: https://github.com/tom813/salesGPT_foundation
# Structure
The conversations have a customer and a salesman which appear always in changing order. customer, salesman, customer, salesman, etc.
The customer always starts the conversation
Who ends the conversation is not defined.
# Generation
Note that a textbook dataset is mandatory for this conversation generation. This examples rely on the following textbook dataset:
https://huggingface.co/datasets/goendalf666/sales-textbook_for_convincing_and_selling
The data generation code can be found here: https://github.com/tom813/salesGPT_foundation/blob/main/data_generation/textbook_and_conversation_gen.py
The following prompt was used to create a conversation
```
def create_random_prompt(chapter, roles=["Customer", "Salesman"], range_vals=(3, 7), industries=None):
if industries is None:
industries = ["tech", "health", "finance"] # default industries; replace with your default list if different
x = random.randint(*range_vals)
y = 0
for i in reversed(range(3, 9)): # Generalized loop for range of values
if i * x < 27:
y = i
break
conversation_structure = ""
for i in range(1, x+1):
conversation_structure += f"""
{roles[0]}: #{i}. sentence of {roles[0].lower()}
{roles[1]}: #{i}. sentence of {roles[1].lower()}"""
prompt = f"""Here is a chapter from a textbook about convincing people.
The purpose of this data is to use it to fine tune a llm.
Generate conversation examples that are based on the chapter that is provided and would help an ai to learn the topic by examples.
Focus only on the topic that is given in the chapter when generating the examples.
Let the example be in the {random.choice(industries)} industry.
Follow this structure and put each conversation in a list of objects in json format. Only return the json nothing more:
{conversation_structure}
Generate {y} lists of those conversations
Chapter:{chapter}"""
return prompt
```
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 数据集信息
特征列表:
- 字段名:'0',数据类型:字符串
- 字段名:'1',数据类型:字符串
- 字段名:'2',数据类型:字符串
- 字段名:'3',数据类型:字符串
- 字段名:'4',数据类型:字符串
- 字段名:'5',数据类型:字符串
- 字段名:'6',数据类型:字符串
- 字段名:'7',数据类型:字符串
- 字段名:'8',数据类型:字符串
- 字段名:'9',数据类型:字符串
- 字段名:'10',数据类型:字符串
- 字段名:'11',数据类型:字符串
- 字段名:'12',数据类型:字符串
- 字段名:'13',数据类型:字符串
- 字段名:'14',数据类型:字符串
- 字段名:'15',数据类型:字符串
- 字段名:'16',数据类型:字符串
- 字段名:'17',数据类型:字符串
- 字段名:'18',数据类型:字符串
- 字段名:'19',数据类型:字符串
数据集划分:
- 划分名称:训练集(train),占用字节数:6821725,样本数量:3412
下载大小:2644154,数据集总存储大小:6821725
配置项:
- 配置名称:默认(default),数据文件:
- 对应划分:训练集,文件路径:data/train-*
# "sales-conversations-2"数据集卡片
# "sales-conversations"数据集卡片
本数据集专为训练可用于说服用户的销售智能体聊天机器人(sales agent chatbot)而构建。
其初始灵感来源于论文《Textbooks Is All You Need》(https://arxiv.org/abs/2306.11644)。
数据集生成使用了gpt-3.5-turbo模型。
如需了解更多信息,请查阅关联模型或GitHub仓库。
关联模型salesGPT_v2:https://huggingface.co/goendalf666/salesGPT_v2
GitHub仓库:https://github.com/tom813/salesGPT_foundation
## 对话结构
本数据集包含的对话始终由客户与销售人员交替登场,顺序不定,即客户、销售人员、客户、销售人员……以此类推。对话始终由客户发起,但未定义对话的结束方。
## 数据生成
请注意,本对话生成任务必须依赖教科书类数据集。本次示例所依托的教科书数据集为:https://huggingface.co/datasets/goendalf666/sales-textbook_for_convincing_and_selling
数据生成代码可在此处获取:https://github.com/tom813/salesGPT_foundation/blob/main/data_generation/textbook_and_conversation_gen.py
以下为用于生成对话的提示词模板:
python
def create_random_prompt(chapter, roles=["Customer", "Salesman"], range_vals=(3, 7), industries=None):
if industries is None:
industries = ["tech", "health", "finance"] # 默认行业列表;如需自定义请替换为对应列表
x = random.randint(*range_vals)
y = 0
for i in reversed(range(3, 9)): # 通用数值范围循环逻辑
if i * x < 27:
y = i
break
conversation_structure = ""
for i in range(1, x+1):
conversation_structure += f"""
{roles[0]}: #{i}. sentence of {roles[0].lower()}
{roles[1]}: #{i}. sentence of {roles[1].lower()}"""
prompt = f"""Here is a chapter from a textbook about convincing people.
The purpose of this data is to use it to fine tune a llm.
Generate conversation examples that are based on the chapter that is provided and would help an ai to learn the topic by examples.
Focus only on the topic that is given in the chapter when generating the examples.
Let the example be in the {random.choice(industries)} industry.
Follow this structure and put each conversation in a list of objects in json format. Only return the json nothing more:
{conversation_structure}
Generate {y} lists of those conversations
Chapter:{chapter}"""
return prompt
为便于国内读者理解,以下为本地化注释后的代码版本:
python
def create_random_prompt(chapter, roles=["客户", "销售人员"], range_vals=(3, 7), industries=None):
if industries is None:
industries = ["科技", "医疗", "金融"] # 默认行业列表;如需自定义请替换为对应列表
# 随机生成对话轮次数量
x = random.randint(*range_vals)
y = 0
for i in reversed(range(3, 9)): # 通用数值范围循环逻辑
if i * x < 27:
y = i
break
conversation_structure = ""
for i in range(1, x+1):
conversation_structure += f"""
{roles[0]}: #{i}. {roles[0].lower()}第{i}句
{roles[1]}: #{i}. {roles[1].lower()}第{i}句"""
prompt = f"""以下为一篇关于说服沟通的教科书章节。
本数据集的用途为用于微调大语言模型(Large Language Model, LLM)。
请基于提供的章节生成对话示例,以帮助AI通过示例学习对应主题。
生成示例时需严格围绕章节给定的主题展开,并将示例设定在{random.choice(industries)}行业场景中。
请遵循以下结构,将每一组对话以JSON对象列表的形式输出,仅返回JSON内容,无需其他额外信息:
{conversation_structure}
请生成{y}组此类对话
章节内容:{chapter}"""
return prompt
[更多信息需求](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
提供机构:
goendalf666
原始信息汇总
数据集概述
数据集信息
-
特征列表:
- 名称: 0, 数据类型: string
- 名称: 1, 数据类型: string
- 名称: 2, 数据类型: string
- 名称: 3, 数据类型: string
- 名称: 4, 数据类型: string
- 名称: 5, 数据类型: string
- 名称: 6, 数据类型: string
- 名称: 7, 数据类型: string
- 名称: 8, 数据类型: string
- 名称: 9, 数据类型: string
- 名称: 10, 数据类型: string
- 名称: 11, 数据类型: string
- 名称: 12, 数据类型: string
- 名称: 13, 数据类型: string
- 名称: 14, 数据类型: string
- 名称: 15, 数据类型: string
- 名称: 16, 数据类型: string
- 名称: 17, 数据类型: string
- 名称: 18, 数据类型: string
- 名称: 19, 数据类型: string
-
数据分割:
- 名称: train, 字节数: 6821725, 样本数: 3412
-
数据大小:
- 下载大小: 2644154
- 数据集大小: 6821725
-
配置:
- 配置名称: default
- 数据文件:
- 分割: train, 路径: data/train-*
数据集结构
- 对话包含客户和销售员,顺序不定,客户总是开始对话,对话结束未定义。
数据生成
-
生成对话需要依赖特定的教科书数据集。
-
生成代码可在以下链接找到: https://github.com/tom813/salesGPT_foundation/blob/main/data_generation/textbook_and_conversation_gen.py
-
生成对话使用的提示如下: python def create_random_prompt(chapter, roles=["Customer", "Salesman"], range_vals=(3, 7), industries=None): if industries is None: industries = ["tech", "health", "finance"] # default industries; replace with your default list if different
x = random.randint(*range_vals) y = 0 for i in reversed(range(3, 9)): # Generalized loop for range of values if i * x < 27: y = i break conversation_structure = "" for i in range(1, x+1): conversation_structure += f""" {roles[0]}: #{i}. sentence of {roles[0].lower()} {roles[1]}: #{i}. sentence of {roles[1].lower()}""" prompt = f"""Here is a chapter from a textbook about convincing people. The purpose of this data is to use it to fine tune a llm. Generate conversation examples that are based on the chapter that is provided and would help an ai to learn the topic by examples. Focus only on the topic that is given in the chapter when generating the examples. Let the example be in the {random.choice(industries)} industry. Follow this structure and put each conversation in a list of objects in json format. Only return the json nothing more: {conversation_structure} Generate {y} lists of those conversations Chapter:{chapter}""" return prompt
搜集汇总
数据集介绍
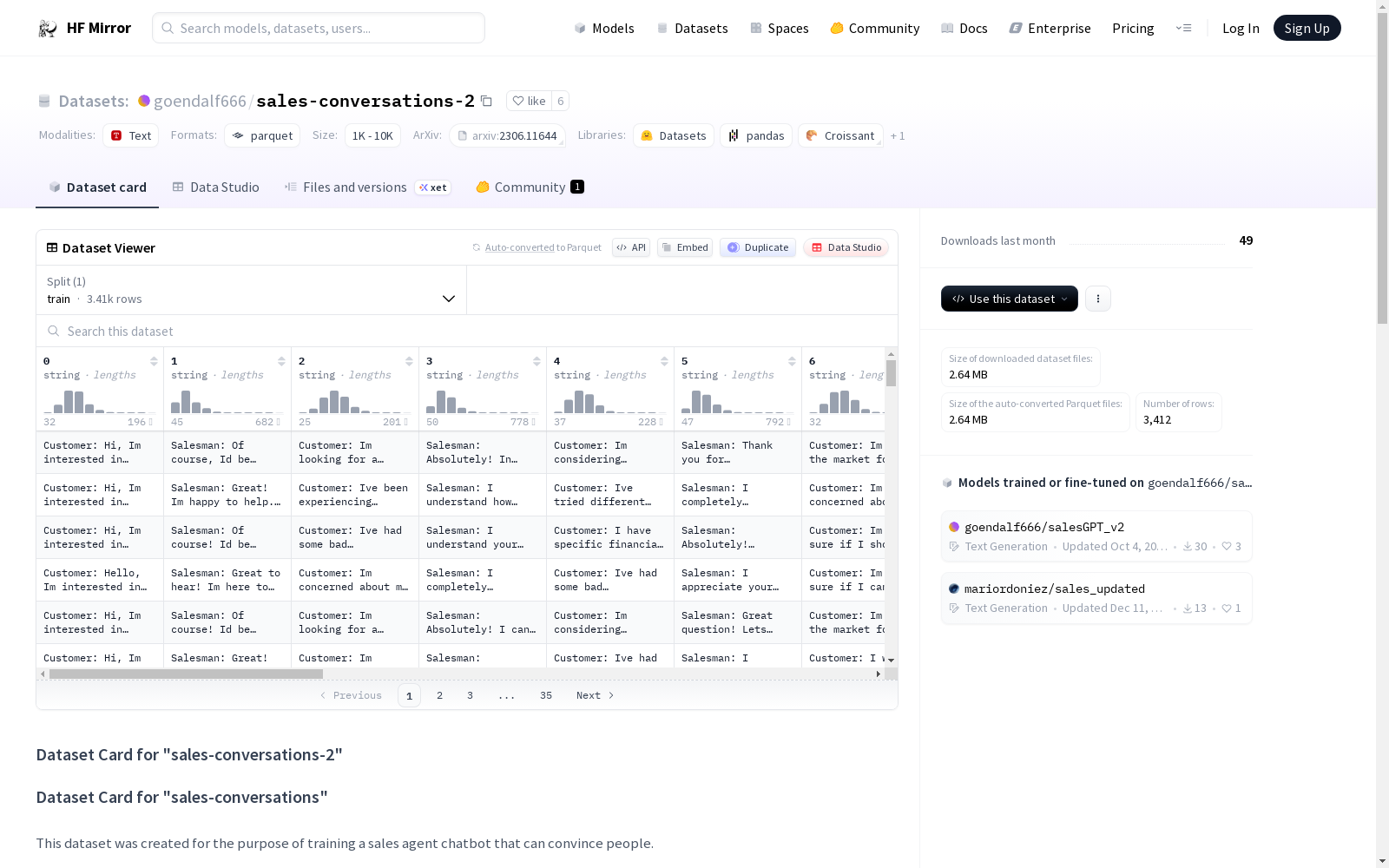
构建方式
在销售对话生成领域,该数据集采用基于教科书知识的合成方法构建。其核心机制依赖于特定领域的教科书数据集作为知识源,通过精心设计的提示工程,利用GPT-3.5-turbo模型生成模拟对话。生成过程遵循结构化模板,首先从教科书中抽取章节内容作为主题依据,随后随机选择行业背景,并按照预设的对话轮次与角色交替顺序,自动产生客户与销售员之间的交互文本。最终输出被格式化为JSON对象列表,确保了数据的规整性与可扩展性。
特点
该数据集在销售对话语料中展现出鲜明的结构化特征。所有对话均严格遵循客户发起、双方交替发言的序列模式,构成了清晰的对话流。数据以多列字符串形式存储,覆盖了从科技到金融等多个行业场景,模拟了真实销售环节中的说服策略与客户应对。其内容深度绑定教科书中的说服理论,确保了生成示例与学术主题的高度一致性,为模型提供了兼具专业性与多样性的训练样本,有效支撑销售对话智能体的能力塑造。
使用方法
该数据集主要应用于销售对话智能体的微调训练。使用者可通过HuggingFace平台直接加载数据集,其标准化的JSON格式便于与主流机器学习框架集成。在具体应用中,建议将对话序列作为输入输出对,用于训练序列到序列模型或对话生成模型,以学习销售场景下的说服策略与语言模式。结合原始教科书数据集进行联合训练,可进一步深化模型对说服理论的理解。相关代码示例已在GitHub仓库开源,为复现与扩展提供了实践指引。
背景与挑战
背景概述
在人工智能与自然语言处理领域,销售对话生成数据集的研究旨在推动对话系统在商业场景中的应用。数据集'sales-conversations-2'由研究人员goendalf666于2023年构建,其灵感来源于'Textbooks Is All You Need'的学术理念,核心目标是通过教材驱动的对话生成,训练能够有效说服客户的销售代理聊天机器人。该数据集利用GPT-3.5-turbo模型生成,涵盖了科技、健康与金融等多个行业,为销售对话的自动化与个性化研究提供了重要资源,对提升商业智能系统的交互能力具有显著影响力。
当前挑战
该数据集致力于解决销售对话生成领域的核心挑战,即如何基于结构化教材内容,生成自然、连贯且具有说服力的多轮对话,以克服传统对话系统在商业语境中缺乏策略性与适应性的局限。在构建过程中,挑战主要体现在对话结构的严格编排与行业知识的准确融合,需确保客户与销售员角色交替的序列符合真实交互逻辑,同时依赖外部教材数据集作为生成基础,增加了数据一致性与语义深度的把控难度。
常用场景
经典使用场景
在对话生成与销售智能体研究领域,goendalf666/sales-conversations-2数据集为构建专业销售对话模型提供了关键语料支撑。该数据集通过模拟真实销售场景中的交互序列,系统化地捕捉了客户与销售人员在多轮对话中的语言模式与说服策略,成为训练端到端销售对话系统的核心资源。其结构化对话记录不仅覆盖科技、健康、金融等多个行业,还严格遵循交替发言的对话逻辑,为模型学习销售话术的动态演进与情境适应性奠定了坚实基础。
实际应用
在实际商业环境中,该数据集支撑的模型已广泛应用于智能销售助手、客户服务自动化及销售培训系统。通过集成行业特定的话术库与对话策略,这类系统能够实时生成符合商业伦理的个性化销售建议,辅助人工销售团队提升转化效率。在金融产品推广、健康咨询导流等垂直场景中,基于该数据训练的模型展现出精准的需求洞察与渐进式说服能力,为企业数字化营销转型提供了可靠的技术赋能。
衍生相关工作
以该数据集为基础衍生的经典工作包括开源项目salesGPT_foundation及其迭代模型salesGPT_v2,这些成果系统探索了教科书知识引导的对话生成架构。相关研究进一步拓展至多模态销售对话生成、跨行业适应性迁移学习等方向,催生了如ConvinceNet等行业针对性模型。这些衍生工作不仅深化了销售对话系统的可解释性研究,还为构建兼具专业性与泛化能力的商业对话智能体提供了持续的技术演进路径。
以上内容由遇见数据集搜集并总结生成


