GRID-Extended (The GRID audiovisual sentence corpus - Extended)
收藏spandh.dcs.shef.ac.uk2024-11-02 收录
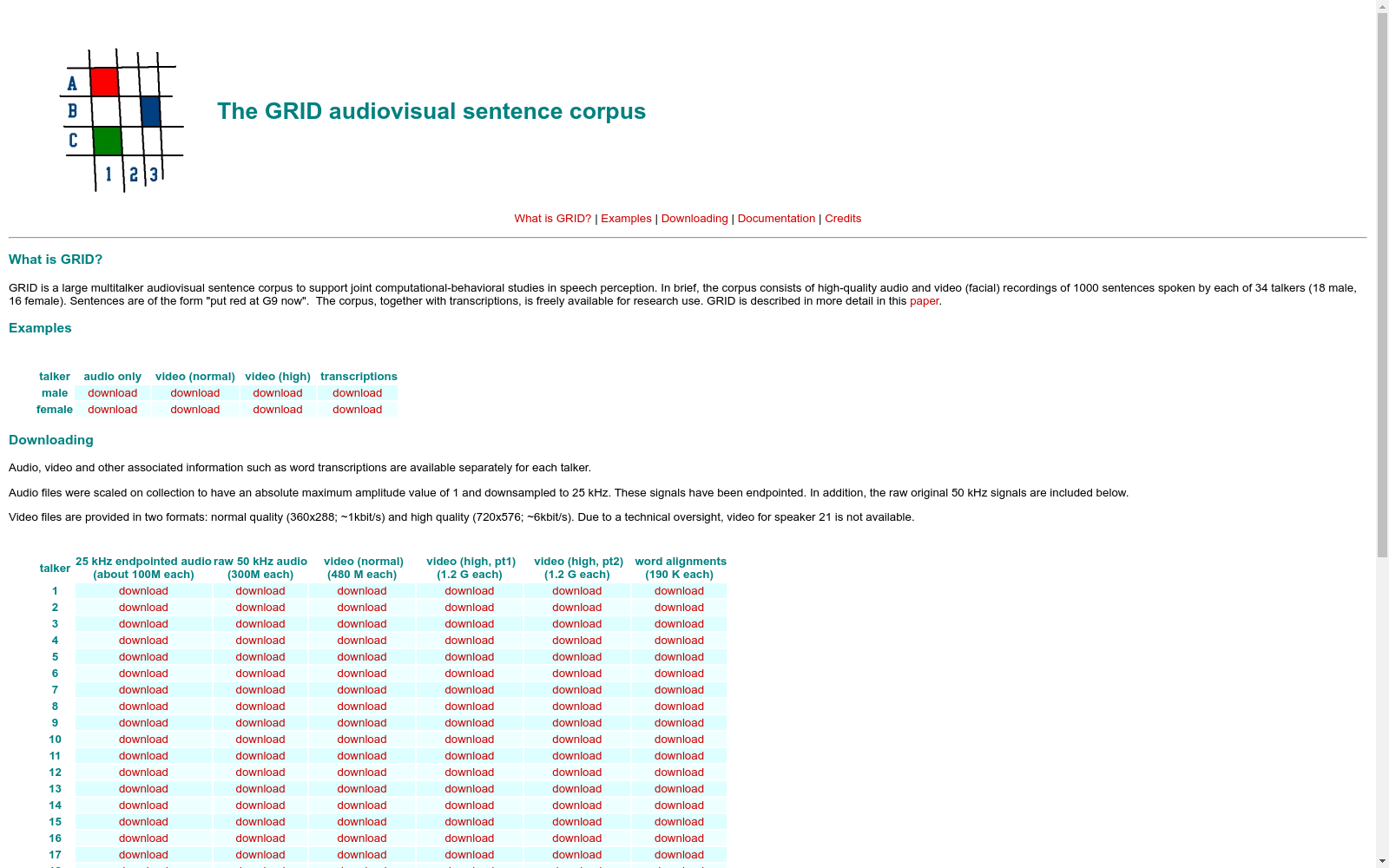
下载链接:
http://spandh.dcs.shef.ac.uk/gridcorpus/
下载链接
链接失效反馈官方服务:
资源简介:
GRID-Extended 是 GRID 视听句子语料库的扩展版本,包含视频和音频数据,用于研究语音识别和自然语言处理。该数据集包括了多个说话者的视频和音频记录,每个记录包含一个预定义的句子结构。
GRID-Extended is an extended version of the GRID audiovisual sentence corpus, which contains video and audio data and is designed for research in speech recognition and natural language processing. This dataset includes video and audio recordings from multiple speakers, with each recording containing a predefined sentence structure.
提供机构:
spandh.dcs.shef.ac.uk
搜集汇总
数据集介绍
构建方式
GRID-Extended数据集是在原始GRID视听句子语料库的基础上,通过引入更多样化的语言表达和场景设置,精心构建而成。该数据集的构建过程中,研究人员广泛收集了来自不同背景和语言习惯的参与者在多种自然场景下的语音和视频数据。通过先进的语音识别和视频处理技术,确保了数据的高质量和一致性。此外,数据集还包含了丰富的元数据,如参与者的性别、年龄、语言背景等,以支持多维度的分析和应用。
使用方法
GRID-Extended数据集适用于多种研究领域,包括但不限于语音识别、情感分析、自然语言处理和视听信息融合。研究人员可以通过访问数据集的官方网站,下载所需的数据子集,并根据研究需求进行预处理和分析。数据集提供了详细的文档和示例代码,帮助用户快速上手。此外,数据集还支持多种编程语言和工具,如Python、MATLAB等,方便研究人员进行定制化开发和实验。通过合理利用GRID-Extended数据集,研究人员可以推动相关领域的技术进步和应用创新。
背景与挑战
背景概述
GRID-Extended数据集,作为GRID视听句子语料库的扩展版本,由英国剑桥大学于2011年创建。该数据集的核心研究问题聚焦于视听信息的多模态融合与理解,旨在提升计算机对人类语言和行为的综合分析能力。主要研究人员包括剑桥大学的Andrew Zisserman教授及其团队,他们在计算机视觉和自然语言处理领域具有显著影响力。GRID-Extended的推出,不仅丰富了视听数据资源的多样性,还为多模态学习、人机交互等前沿研究提供了宝贵的实验平台,极大地推动了相关领域的发展。
当前挑战
GRID-Extended数据集在构建过程中面临多重挑战。首先,视听数据的多模态融合要求高精度的同步与对齐技术,以确保音频与视频信息的准确匹配。其次,数据集的扩展需要处理大量异构数据,包括不同背景、光照条件和语言表达方式,这对数据清洗和标注提出了高要求。此外,如何有效利用扩展数据集进行模型训练,以提升多模态学习的性能,也是当前研究的一大难题。这些挑战不仅涉及技术层面的创新,还要求研究者具备跨学科的综合能力,以应对复杂多变的实际应用场景。
发展历史
创建时间与更新
GRID-Extended数据集,作为GRID视听句子语料库的扩展版本,其创建时间可追溯至2011年,随后在2017年进行了重大更新,以丰富其内容和多样性。
重要里程碑
GRID-Extended数据集的重要里程碑包括其在2011年的首次发布,这一发布标志着视听语料库在多模态研究中的应用迈出了重要一步。2017年的更新则进一步扩展了数据集的规模和多样性,引入了更多样化的语言和行为模式,极大地推动了多模态数据分析和机器学习算法的发展。
当前发展情况
当前,GRID-Extended数据集已成为多模态研究领域的基石,广泛应用于语音识别、情感分析和行为预测等多个前沿领域。其丰富的视听数据为研究人员提供了宝贵的资源,促进了跨学科研究的深入发展。此外,数据集的持续更新和扩展,确保了其在不断变化的科研需求中保持前沿地位,为未来的多模态技术进步奠定了坚实基础。
发展历程
- GRID-Extended数据集首次发表,作为GRID视听句子语料库的扩展版本,旨在提供更丰富的视听数据以支持多模态研究。
- GRID-Extended数据集首次应用于多模态机器学习研究,特别是在视听信息融合和语音识别领域。
- GRID-Extended数据集的重要里程碑事件,其数据规模和多样性得到了显著扩展,进一步推动了多模态研究的进展。
- GRID-Extended数据集被广泛应用于多个国际会议和期刊,成为多模态研究领域的重要参考数据集。
常用场景
经典使用场景
在语音与语言处理领域,GRID-Extended数据集以其丰富的视听信息和多样的句子结构,成为研究语音识别、自然语言理解和多模态数据融合的经典工具。该数据集包含了超过1000个不同说话者的视频和音频数据,每个视频片段都配有相应的句子标注,为研究人员提供了详尽的实验材料。
解决学术问题
GRID-Extended数据集解决了语音识别系统在复杂背景噪声和多样化说话者条件下的性能瓶颈问题。通过提供高质量的视听数据,该数据集帮助研究者开发出更加鲁棒和准确的语音识别算法。此外,它还促进了多模态学习的发展,使得机器能够更好地理解人类语言和非语言信息之间的关联。
实际应用
在实际应用中,GRID-Extended数据集被广泛用于开发智能家居设备、语音助手和视频会议系统。这些应用场景中,系统需要准确识别和理解用户的语音指令,同时结合视觉信息以提高交互的自然性和准确性。数据集的多模态特性使得这些系统能够在各种环境下稳定运行。
数据集最近研究
最新研究方向
在多媒体信息处理领域,GRID-Extended数据集的最新研究方向主要集中在多模态情感分析与跨模态检索上。该数据集通过整合音频、视频和文本信息,为研究者提供了丰富的多模态数据资源,促进了情感识别和内容检索技术的进步。前沿研究不仅探索了如何更准确地从多模态数据中提取情感特征,还致力于开发高效的跨模态匹配算法,以实现更精准的检索效果。这些研究成果在人机交互、智能客服和情感计算等领域具有广泛的应用前景,推动了多媒体技术的智能化发展。
相关研究论文
- 1The GRID audiovisual sentence corpus: A resource for multimodal researchUniversity of East Anglia · 2012年
- 2Multimodal Sentiment Analysis Using Deep Learning ArchitecturesUniversity of Southern California · 2018年
- 3Multimodal Language Analysis in the Wild: CMU-MOSEI Dataset and Interpretable Dynamic Fusion GraphCarnegie Mellon University · 2018年
- 4Multimodal Sentiment Analysis: A Survey on Current Approaches and Future DirectionsUniversity of Surrey · 2020年
- 5Multimodal Machine Learning: A Survey and Taxonomy of the State of the ArtUniversity of Illinois at Urbana-Champaign · 2019年
以上内容由遇见数据集搜集并总结生成


