sinhala-english-singlish-translation
收藏Sinhala–English–Singlish Translation Dataset 概述
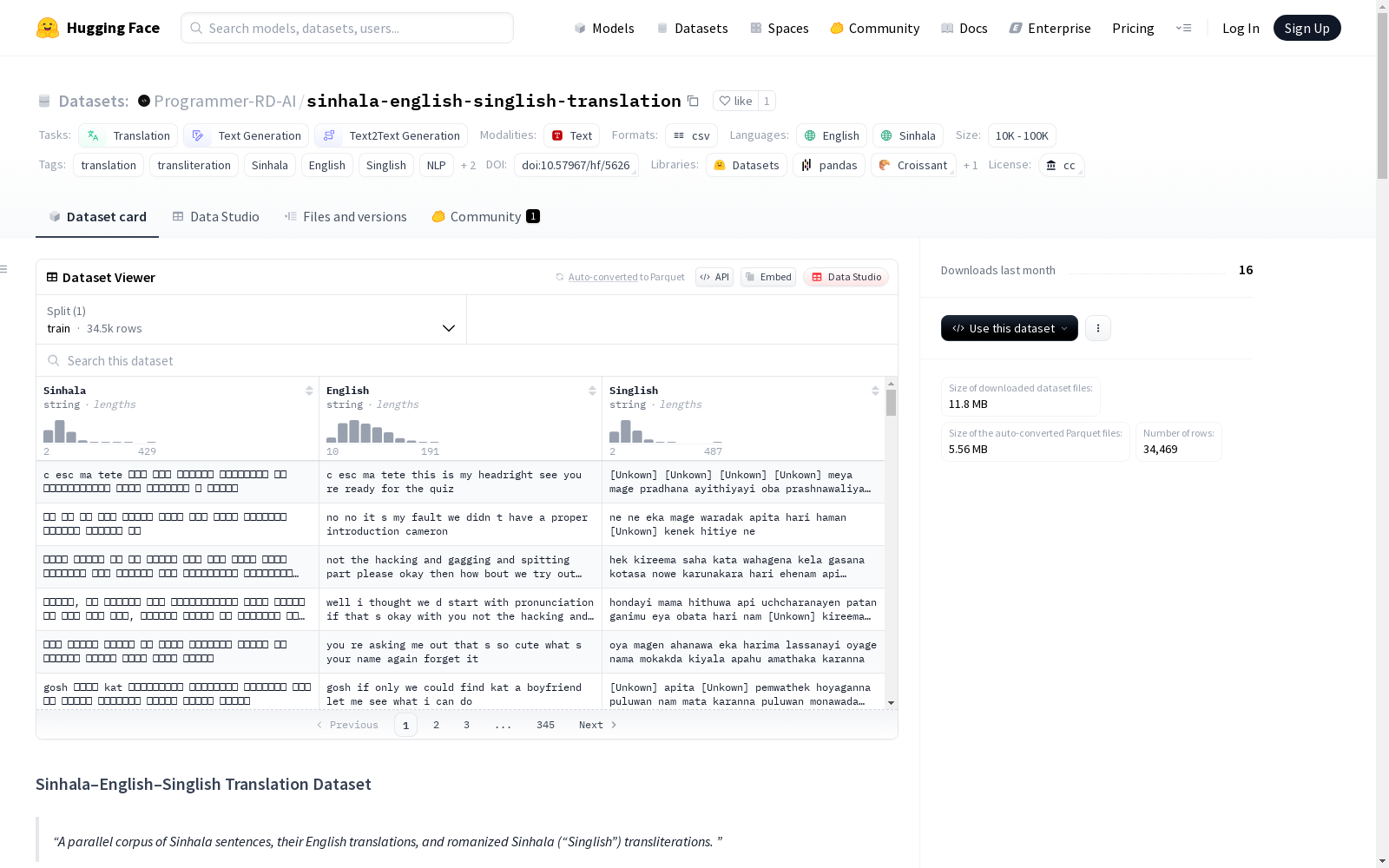
数据集基本信息
- 名称: Sinhala–English–Singlish Translation Dataset
- 任务类别: 翻译、文本生成、文本到文本生成
- 语言: 英语 (en)、僧伽罗语 (si)
- 标签: 翻译、转写、僧伽罗语、英语、新加坡式英语、自然语言处理、数据集、低资源
- 大小: 10K<n<100K
- 许可证: CC License
数据集描述
- 内容: 34,500个对齐的三元组,包括:
- 僧伽罗语(原生脚本)
- 英语(人工翻译)
- 新加坡式英语(罗马化的僧伽罗语)
- 来源:
- Kaggle数据集:
programmerrdai/sinhala-english-singlish-translation-dataset - 收集管道: GitHub Sinenglish-LLM-Data-Collection
- Kaggle数据集:
- DOI: 10.57967/hf/5605
- 发布日期: 2025年(修订版
c6560ff)
数据集结构
| 列名 | 类型 | 描述 |
|---|---|---|
sinhala |
string |
僧伽罗语脚本的原句 |
english |
string |
对应的英语翻译 |
singlish |
string |
罗马化的僧伽罗语(新加坡式英语) |
- 行数: 34,500
- 格式: CSV(在HF上以Parquet格式查看)
使用示例
-
加载到Pandas: python import pandas as pd from datasets import load_dataset
df = load_dataset( "Programmer-RD-AI/sinhala-english-singlish-translation", split="train" ).to_pandas()
-
微调翻译模型: python from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, Trainer, TrainingArguments
tokenizer = AutoTokenizer.from_pretrained("t5-small") model = AutoModelForSeq2SeqLM.from_pretrained("t5-small")
def preprocess(ex): inputs = "translate Sinhala to English: " + ex["sinhala"] targets = ex["english"] tokenized = tokenizer(inputs, text_target=targets, truncation=True) return tokenized
train_dataset = ds.map(preprocess, remove_columns=ds.column_names)
引用
bibtex @misc{ranuga_disansa_gamage_2025, author = { Ranuga Disansa Gamage and Sasvidu Abesinghe and Sheneli Fernando and Thulana Vithanage }, title = { sinhala-english-singlish-translation (Revision b6bde25) }, year = 2025, url = { https://huggingface.co/datasets/Programmer-RD-AI/sinhala-english-singlish-translation }, doi = { 10.57967/hf/5626 }, publisher = { Hugging Face } }
许可证
- 类型: CC License