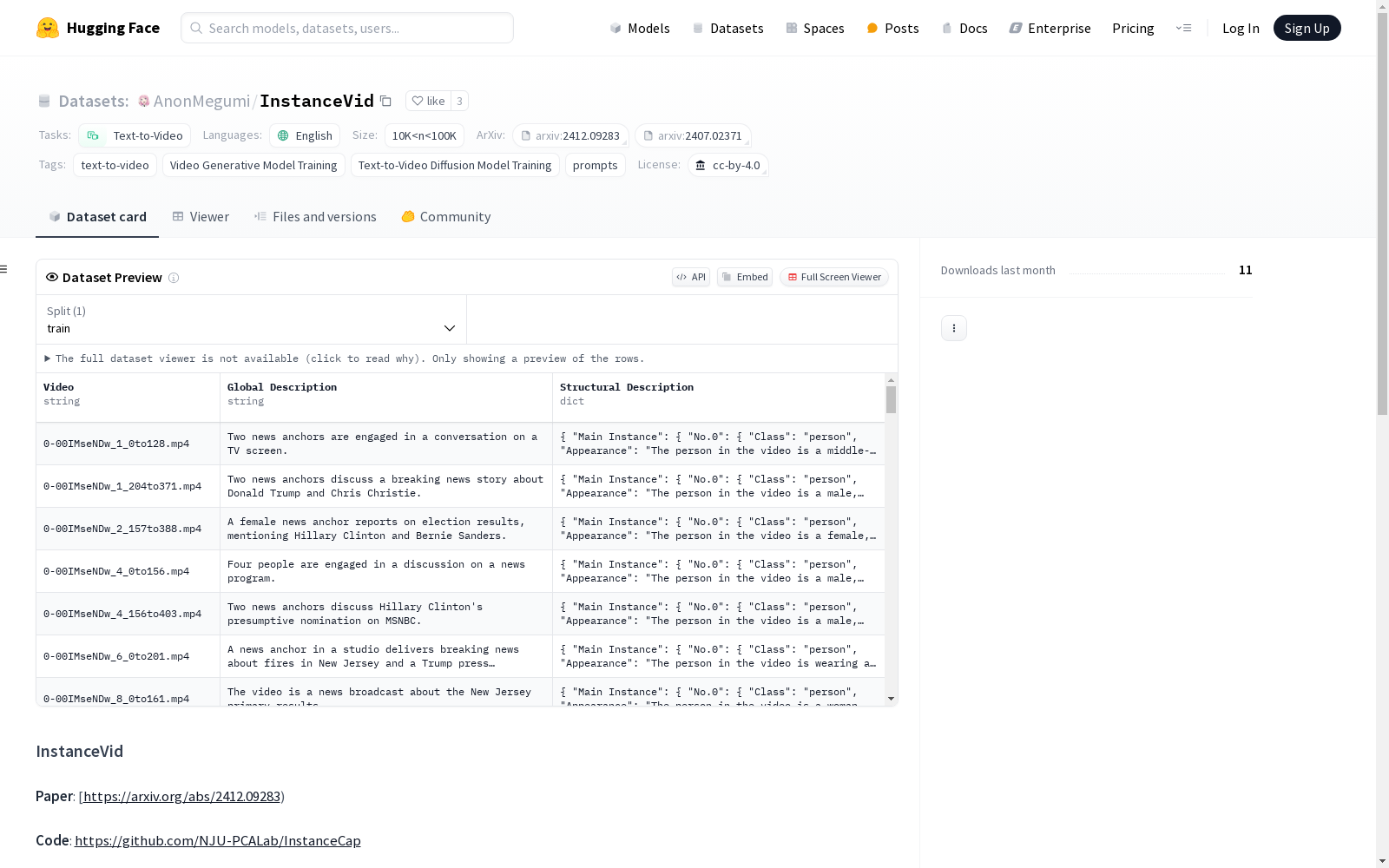
InstanceVid
收藏InstanceVid
概述
InstanceVid 是一个用于文本到视频生成任务的数据集,属于 OpenVid-1M 的子集。该数据集主要用于视频生成模型的训练,特别是文本到视频扩散模型的训练。
数据集信息
- 任务类别: 文本到视频生成
- 语言: 英语
- 标签: 文本到视频生成, 视频生成模型训练, 文本到视频扩散模型训练, 提示
- 数据集大小: 10K<n<100K
- 许可证: CC-BY-4.0
使用方法
用户需要从 OpenVid-1M 获取相应的视频文件,并提供给仓库索引。数据集中包含三个文件:
- 原始 InstanceCap (Instancecap.jsonl)
- 压缩的 Dense 形式 (InstanceCap_Dense.csv/jsonl)
除了 Caption 外,数据集还记录了视频的帧数、高度、宽度、宽高比、帧率和分辨率等信息。
许可证
InstanceVid 数据集以 CC-BY-4.0 许可证发布。视频样本来自公开可用的数据集,用户在使用这些视频样本时必须遵循相关的许可证,包括 Panda, ChronoMagic, Open-Sora-plan, CelebvHQ(未知)。
引用
@misc{fan2024instancecapimprovingtexttovideogeneration, title={InstanceCap: Improving Text-to-Video Generation via Instance-aware Structured Caption}, author={Tiehan Fan and Kepan Nan and Rui Xie and Penghao Zhou and Zhenheng Yang and Chaoyou Fu and Xiang Li and Jian Yang and Ying Tai}, year={2024}, eprint={2412.09283}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2412.09283}, }
@article{nan2024openvid, title={OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation}, author={Nan, Kepan and Xie, Rui and Zhou, Penghao and Fan, Tiehan and Yang, Zhenheng and Chen, Zhijie and Li, Xiang and Yang, Jian and Tai, Ying}, journal={arXiv preprint arXiv:2407.02371}, year={2024} }