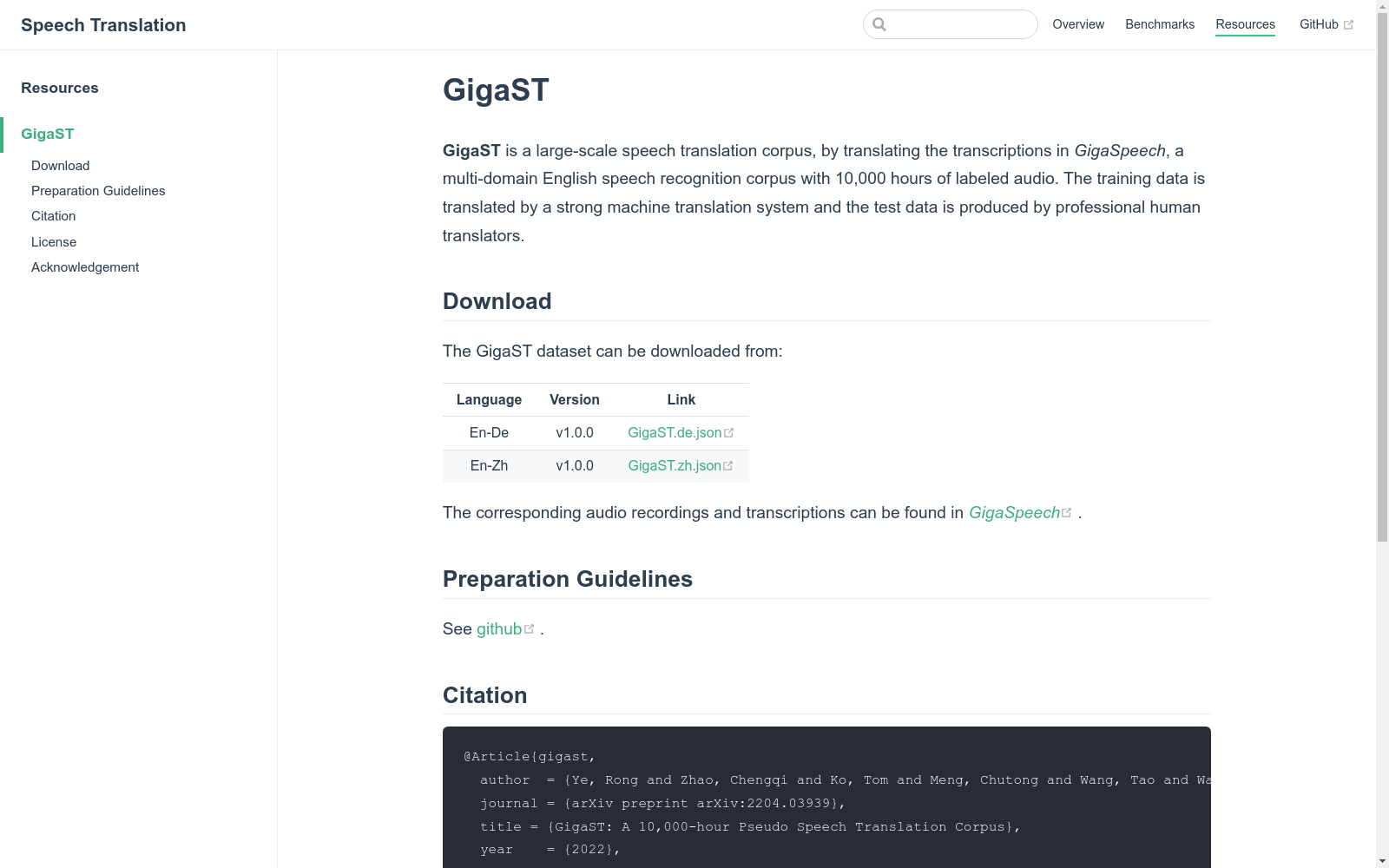
GigaST
收藏arXiv2023-06-06 更新2024-06-21 收录
下载链接:
https://st-benchmark.github.io/resources/GigaST
下载链接
链接失效反馈官方服务:
资源简介:
GigaST是由字节跳动创建的一个大规模伪语音到文本翻译(ST)数据集,基于GigaSpeech英语ASR数据集,将其转录翻译成德语和中文。该数据集通过强大的机器翻译系统翻译训练集,人工翻译测试集,显著提升了MuST-C英语-德语基准测试集的性能。GigaST数据集不仅包含英语-中文(En-Zh)和英语-德语(En-De)翻译方向,还通过发布训练脚本,便于复现其系统,旨在推动语音翻译领域的研究。
GigaST is a large-scale pseudo speech-to-text translation (ST) dataset developed by ByteDance. Built upon the GigaSpeech English ASR dataset, it translates the transcripts from the source dataset into German and Chinese. For the training split, the dataset uses powerful machine translation systems, while the test split is manually translated, which significantly improves the performance on the MuST-C English-German benchmark. The GigaST dataset supports two translation directions: English-Chinese (En-Zh) and English-German (En-De). Additionally, it releases training scripts to facilitate the reproduction of its experimental system, aiming to advance research in the field of speech translation.
提供机构:
字节跳动
创建时间:
2022-04-08
搜集汇总
数据集介绍
构建方式
GigaST数据集的构建过程主要基于GigaSpeech英文语音识别语料库,通过将GigaSpeech中的英文语音转录文本翻译成德语和中文,从而形成了一个大规模的伪语音到文本翻译语料库。训练集的翻译是通过强大的机器翻译系统完成的,而测试集的翻译则由人工完成。这一构建方法有效地扩展了现有的语音翻译语料库规模,为语音翻译研究提供了更丰富的数据资源。
特点
GigaST数据集的特点在于其规模庞大,包含了10,000小时的英文语音转录文本,翻译成德语和中文后,形成了远超现有开源数据集的语料库。此外,GigaST数据集的翻译质量经过自动化指标评估和人工评估的双重验证,确保了翻译的准确性和流畅性。数据集还包含了详细的翻译过程描述,为研究者提供了参考。
使用方法
使用GigaST数据集的方法包括首先对其进行预处理和过滤,提取音频特征和文本编码,然后进行训练和评估。在实验中,研究者使用了语音Transformer模型和SSL-Transformer模型,通过对比不同训练数据规模和模型参数规模下的性能,验证了GigaST数据集对语音翻译模型性能的提升作用。此外,研究者还分析了预训练语音编码器在语音翻译任务中的作用,发现其在提升模型性能方面具有重要意义。
背景与挑战
背景概述
语音到文本翻译(Speech-to-Text Translation,ST)技术是自然语言处理领域的一个重要研究方向,其目标是将源语言的语音直接翻译成目标语言的文本,无需输出源语言的转录。随着注意力机制在语音和文本相关任务中的成功应用,基于语音转换器的ST模型成为了一个典型且有效的基准模型。为了训练这样的端到端ST模型,高质量的数据集至关重要。GigaST数据集正是在这样的背景下应运而生。该数据集由字节跳动的研究人员于2023年6月创建,旨在解决现有ST数据集规模较小的问题。GigaST数据集通过将GigaSpeech语音识别数据集中的英语语音转录翻译成德语和中文来构建,其规模比现有的开源数据集如MuST-C和TEDx大25倍。GigaST数据集的发布对于推动语音翻译研究具有重要意义,它为研究人员提供了一个大规模的ST数据集,有助于提升模型的训练效果,并为相关领域的研究提供了新的方向。
当前挑战
GigaST数据集的创建过程中面临的主要挑战包括:1)如何构建大规模的ST数据集,以解决现有数据集规模较小的问题;2)如何保证翻译文本的质量,使其能够与人类翻译相媲美。为了解决这些挑战,研究人员采用了一系列技术手段,如使用高质量的机器翻译系统进行翻译、对翻译文本进行人工校验等。同时,研究人员还分析了不同模型在不同训练数据规模下的性能,发现随着训练数据规模的增加,模型的翻译性能也随之提升。这些研究成果对于推动ST技术的发展具有重要意义,并为未来的研究提供了重要的参考依据。
常用场景
经典使用场景
GigaST数据集是一个大规模的伪语音到文本翻译(ST)语料库,由将GigaSpeech英文语音识别语料库的转录翻译成德语和中文创建而成。该数据集包含英语-中文(En-Zh)和英语-德语(En-De)两种翻译方向的训练集和测试集。GigaST数据集的一个经典使用场景是训练端到端语音到文本翻译模型,例如Speech-Transformer模型和SSL-Transformer模型。通过使用GigaST数据集进行训练,这些模型在MuST-C英德基准测试集上取得了新的最先进成果。
解决学术问题
GigaST数据集解决了语音翻译领域中数据规模不足的问题。传统的语音翻译数据集规模较小,难以支持模型训练出高质量的翻译效果。GigaST数据集提供了超过10,000小时的语音转录平行数据,使得模型训练的数据规模得到了显著提升。此外,GigaST数据集还提供了手动标注和验证的测试集,避免了之前MuST-C数据集中存在的对齐错误,从而提高了测试集的质量。GigaST数据集的发布为语音翻译研究提供了重要的数据资源,推动了该领域的发展。
衍生相关工作
GigaST数据集的发布衍生了多个相关研究工作。例如,研究人员使用GigaST数据集训练了多种语音翻译模型,并在MuST-C英德基准测试集上取得了新的最先进成果。此外,研究人员还分析了预训练语音编码器在语音翻译任务中的作用,并发现预训练语音编码器可以提高模型性能。此外,研究人员还研究了SSL-Transformer模型在语音翻译任务中的应用,并发现SSL-Transformer模型可以进一步提高模型性能。这些研究成果为语音翻译领域的发展提供了新的思路和方向。
以上内容由遇见数据集搜集并总结生成


