NbAiLab/nst_tts_dataset_trimmed
收藏Hugging Face2026-05-03 更新2026-05-10 收录
下载链接:
https://hf-mirror.com/datasets/NbAiLab/nst_tts_dataset_trimmed
下载链接
链接失效反馈官方服务:
资源简介:
这是一个经过边缘修剪的挪威语文本转语音(TTS)数据集,源自NbAiLab/nst_tts_dataset。数据集包含channel_1的元数据文件metadata.jsonl和修剪后的.wav音频文件,修剪仅应用于音频剪辑的开头和结尾。数据集旨在为训练TTS系统提供较少前后静音时长的音频样本,同时保留内部停顿。
Edge-trimmed Norwegian TTS dataset derived from NbAiLab/nst_tts_dataset. Includes metadata.jsonl plus trimmed .wav files for channel_1, with trimming only applied to the beginning and end of each clip. This version is intended for training TTS systems with less leading and trailing silence while preserving internal pauses.
提供机构:
NbAiLab
搜集汇总
数据集介绍
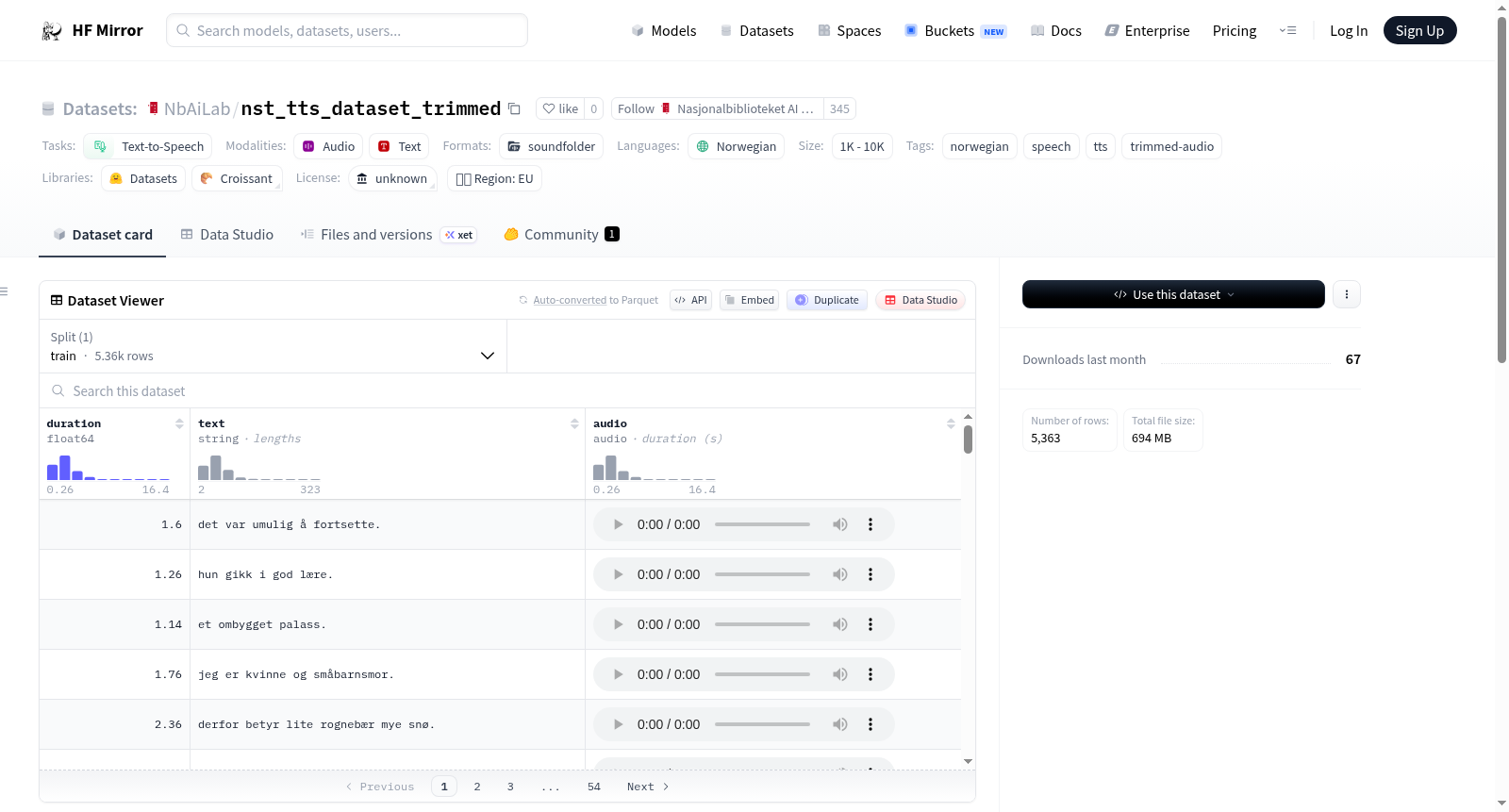
构建方式
本数据集由原始挪威语TTS数据集NbAiLab/nst_tts_dataset经过边缘静音裁剪而构建。具体而言,对全部5363个音频片段的首尾静音部分进行了切除,裁剪策略基于20.0毫秒的帧大小,最低语音活动检测跨度为120.0毫秒,并在语音起点和终点分别保留80.0毫秒与120.0毫秒的前后填充,以确保语音内容的完整性。内部停顿得以完整保留,合计移除了长达12302.27秒的静音,每个片段中位数移除静音约2.193秒。
特点
该数据集的核心特点在于其精简的音频结构,通过精准去除首尾静音,显著提升了语音数据的有效利用率。所有音频仅包含单个通道(channel_1),并附有对应的metadata.jsonl元数据文件。最大单片段静音移除量可达5.154秒,使得音频片段更加紧凑,尤其适合用于训练语音合成模型,减少了模型对冗余静音段的学习负担,从而提升合成语音的自然流畅度。
使用方法
使用方法简洁直接,加载metadata.jsonl文件即可获取每个裁剪后.wav文件的路径与对应文本标注。用户可直接将这些片段作为TTS模型的输入输出对,无需额外进行静音检测或预处理。由于内部停顿被妥善保留,该数据非常适合训练需要精确控制语速与韵律的语音合成系统。建议在模型训练时配合其他挪威语文本数据使用,以增强语种覆盖与发音多样性。
背景与挑战
背景概述
该数据集由挪威国家图书馆(NbAiLab)的研究团队于近期创建,专注于挪威语文本到语音(TTS)合成任务。其核心研究问题在于如何通过去除音频边缘静音段,提升TTS系统训练数据的质量与效率。作为NST TTS数据集的精简版本,它通过精确的静音检测与裁剪策略,为低资源语言语音合成领域提供了关键数据支撑,尤其对挪威语这一小语种的自然语音生成具有重要推动作用。
当前挑战
数据集所解决的领域挑战在于,原始挪威语语音数据中存在大量边缘静音,导致TTS模型学习效率低下且生成语音停顿不自然。通过基于20毫秒帧大小、120毫秒最小语音活动检测等参数的边缘裁剪,该数据集有效减少了总计12302.27秒的无效音频。然而构建过程中面临精准区分边缘静音与内部停顿的挑战,既要保证去除冗余静音,又必须完整保留语音内部的自然间歇,这对裁剪算法的鲁棒性提出了严格要求。
常用场景
经典使用场景
该数据集专为挪威语文本到语音合成任务而设计,其核心应用在于训练高质量的TTS系统。通过对原始音频进行边缘静音裁剪,数据集剔除了语音片段首尾的无用静音部分,从而为声学模型和声码器提供了更为紧凑、对齐良好的训练样本。研究者可借此构建端到端的语音合成模型,如Tacotron2、FastSpeech或VITS等,并在挪威语这一低资源语言上实现更加自然流畅的语音生成。
实际应用
在实际应用中,该数据集可助力开发挪威语智能语音助手、有声读物生成系统及无障碍辅助技术。例如,基于此数据训练的TTS模型可嵌入导航设备,为挪威用户提供清晰的路况播报;或用于教育场景中自动生成挪威语学习材料的朗读音频。边缘裁剪后的音频还减少了实时合成时的延迟,提升了交互体验,特别适用于资源受限的嵌入式设备和移动终端。
衍生相关工作
该数据集衍生了一系列挪威语语音合成方向的研究工作,包括基于迁移学习的跨语言TTS模型、韵律可控的语音生成系统以及结合自监督预训练的低资源语音合成方法。此外,裁剪策略启发了后续针对其他语种的静音剔除数据集构建工作,如边缘裁剪与内部静音保留相结合的前后处理流程被应用于丹麦语、瑞典语等斯堪的纳维亚语系TTS项目中,推动了北欧语言语音技术的发展。
以上内容由遇见数据集搜集并总结生成


