Near-collision
收藏arXiv2020-11-02 更新2024-06-21 收录
下载链接:
https://aashi7.github.io/NearCollision.html
下载链接
链接失效反馈官方服务:
资源简介:
本研究贡献了一个名为Near-collision的大型数据集,包含13,658个以第一人称视角拍摄的室内视频片段,旨在为移动机器人提供更直观的碰撞预测数据。数据集中的每个视频片段至少展示了一个人的轨迹,最终与装有摄像头的移动行李箱形平台接近(即接近碰撞)。数据集的创建过程涉及使用立体摄像机和LIDAR传感器进行数据收集和标注,确保了数据的准确性和可靠性。该数据集主要应用于预测移动机器人与附近行人之间的接近碰撞时间,为动态路径规划中的碰撞避免提供支持。
This study contributes a large-scale dataset named Near-collision, which consists of 13,658 indoor video clips captured from a first-person perspective. The dataset is designed to provide more intuitive collision prediction data for mobile robots. Each video clip in the dataset depicts the trajectory of at least one person who ultimately comes close to a camera-equipped mobile luggage-shaped platform (i.e., near-collision). The dataset creation process involves data collection and annotation using stereo cameras and LIDAR sensors, ensuring the accuracy and reliability of the data. This dataset is primarily applied to predict the near-collision time between mobile robots and nearby pedestrians, providing support for collision avoidance in dynamic path planning.
提供机构:
卡内基梅隆大学机器人研究所
创建时间:
2019-03-22
搜集汇总
数据集介绍
构建方式
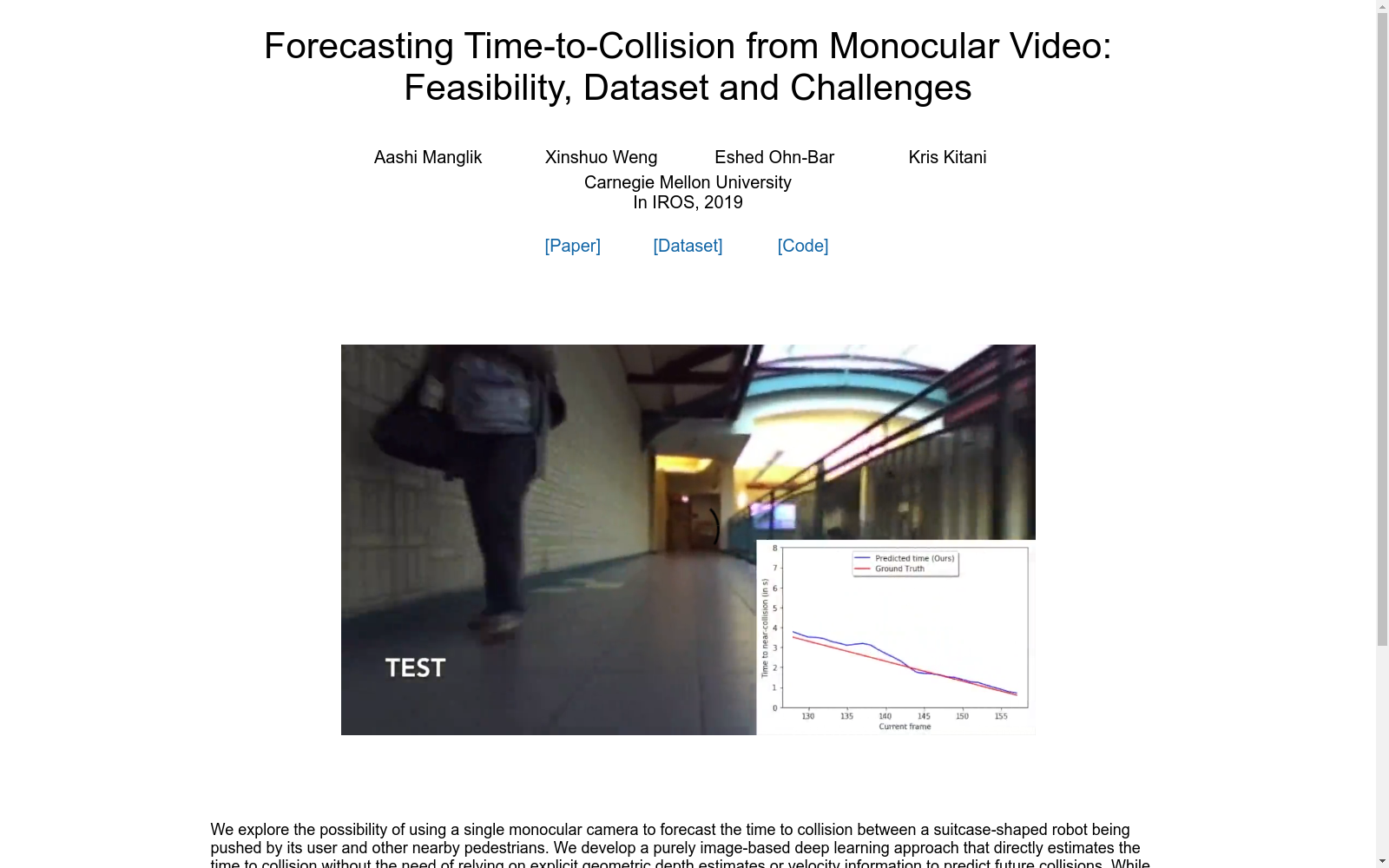
为了研究利用单个单目摄像头预测手推行李箱形机器人和附近行人之间碰撞时间的问题,我们构建了一个名为Near-collision的数据集。该数据集包含超过13,000个室内视频片段,每个片段都展示至少一个人的轨迹,最终以与摄像头近距离(接近碰撞)结束。数据采集过程中,使用了立体相机和激光雷达传感器,其中立体相机用于自动标注地面真实标签和提供左右视角的训练样本,而激光雷达则用于确保深度标注的稳定性和可靠性。通过LIDAR点云数据,我们计算每个检测到的行人框像素的中位数距离,以获得3D位置。数据集中,我们定义了一个人在移动平台1米半径内的存在为接近碰撞,如果有人在此半径内,我们将其标记为需要预测的接近碰撞。为了模拟视觉障碍人士使用行李箱的情况,我们将行李箱形训练原型推过三个不同的大学建筑,以获取多样化的场景和行人动态数据。
特点
Near-collision数据集的特点在于其从第一人称视角捕获的视频片段,这对于移动机器人来说更为直观。与现有的大多数从固定俯视摄像头捕获的人体轨迹预测数据集不同,我们的数据集更加贴近实际应用场景。此外,数据集还提供了与视频片段对应的3D点云数据,为自动标注地面真实标签提供了便利。数据集的主要任务是预测接近碰撞的时间,这是一个回归问题,即通过学习附近行人的时空运动到接近碰撞时间的映射,来预测未来6秒内发生接近碰撞的确切时间。我们的研究结果表明,基于VGG-16的多流卷积神经网络在预测接近碰撞时间方面表现最佳,平均预测误差为0.75秒。
使用方法
使用Near-collision数据集时,首先需要明确预测接近碰撞时间的任务定义,即回归问题。然后,可以采用多种视频网络架构进行实验,如VGG-16和I3D,并比较它们的性能。此外,还需要考虑输入的时间窗口长度,即连续帧的数量,以确定最佳的预测精度。在实验中,我们发现0.5秒(6帧)的时间窗口能够为多流VGG网络提供最准确的预测结果。最后,可以对预测结果进行定性评估,以观察预测的平滑性和与地面真实标签的一致性。通过这种方式,研究人员可以利用Near-collision数据集来训练和评估他们的碰撞预测模型,从而为移动机器人提供更加准确的碰撞避免能力。
背景与挑战
背景概述
在移动机器人领域,自动避障技术是不可或缺的。传统方法依赖于多模态传感器,而近期,基于图像的避障策略开始受到关注。这些策略利用大数据的力量来检测即时碰撞,将其视为一个二元变量——碰撞或不碰撞。本研究探讨了使用单目摄像头预测用户推动的行李箱形状机器人与附近行人之间的碰撞时间的可能性。研究人员开发了一种纯粹基于图像的深度学习方法,该方法直接估计碰撞时间,无需依赖于显式的几何深度估计或速度信息来预测未来的碰撞。与之前主要集中在检测无人机导航中的即时碰撞的工作不同,本研究提出了一种更精细的方法,通过预测以毫秒为单位的确切碰撞时间来预测碰撞,这对于动态路径规划中的避障更有帮助。为了评估这种方法,研究人员收集了一个包含超过13,000个室内视频片段的新数据集,每个片段都显示了至少一个人的轨迹,最终与安装在移动行李箱形状平台上的相机发生近距离接触(近碰撞)。使用这个数据集,研究人员在不同的时间窗口上进行了广泛的实验,使用了一系列最先进的卷积神经网络(CNNs)。结果表明,他们提出的多流CNN是预测近碰撞时间的最佳模型。在测试视频中,近碰撞时间的平均预测误差为0.75秒。该项目的网页可在https://arxiv.org/abs/1903.09102v3找到。
当前挑战
本研究面临的主要挑战包括:1)直接从图像序列中预测碰撞时间,无需显式地跟踪周围行人的位置;2)在存在传感器噪声和检测附近行人时的不确定性时,物理方法可能会失败;3)多模态传感器在户外环境中可能不适用;4)为了获得地面真实标注,设计了一种高效的训练原型;5)数据收集过程中,行人检测和跟踪的准确性对于预测结果至关重要;6)选择合适的时间窗口作为输入,以便更好地捕捉时间和空间特征。
常用场景
经典使用场景
该数据集的经典使用场景是预测一个由用户推动的行李箱形状的机器人和周围行人之间的碰撞时间。这需要使用单个单目摄像头进行图像分析,以估计未来碰撞的确切时间,而不是仅检测当前时刻的碰撞。这种预测对于动态路径规划中的碰撞避免尤为重要。
实际应用
在实际应用中,该数据集可用于开发辅助性行李箱系统,帮助视觉障碍人士避免与周围行人的碰撞。此外,该数据集还可以用于训练能够在室内走廊中导航的移动机器人,使其能够在动态环境中安全地避开行人。
衍生相关工作
该数据集的衍生相关工作包括使用单目摄像头进行碰撞预测的研究,以及使用深度学习技术进行时间和碰撞预测的研究。此外,该数据集还促进了视频架构在时空特征学习方面的研究,包括2D卷积网络和3D卷积网络的使用。
以上内容由遇见数据集搜集并总结生成


