LIUshu123/knowledgeDAO
收藏Hugging Face2023-09-05 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/LIUshu123/knowledgeDAO
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
---
# KnowledgeDAO(知识岛)
供AI训练的中文数据集(持续更新。。。)
为了推进中文AI的发展,促进AI技术公开化、国际化,我们成立了知识岛(KnowledgeDAO)项目,希望借助大家的力量推进中文AI数据集的建设。
数据、算法和算力,是AI发展的三大基石,其中数据的质量对模型最终性能至关重要。然而,从Hugging Face上的模型数据集数量来看,5W多的数据集中,英语的占比超过90%,优质中文数据少之又少。
OpenAI完成数据集的收集花费了巨大成本,以至于需要从微软集资。我们无力承担如此巨大的开销,于是需要各位有志于筹建开放获取语料,并有一定技术基础的网友们献上自己的力量。
如果您有意向参与此项目,我们将不胜感激。
# 知识岛目前的数据集
1、餐饮行业:
a、餐饮行业8000问,文件名:《餐饮行业8000问.jsonl》
来源:2022年和2023年餐饮行业报告与行业白皮书,由chatGPT 3.5负责整理总结,共8204条问答对,1.3M的tokens总数(680k汉字总数)
2、百度知道,WebQA文件夹中,文件名:test数据集《KD_WebQA_test.json》《KD_WebQA_test.jsonl》,validation数据集《KD_WebQA_validation.json》《KD_WebQA_validation.jsonl》,
train数据集:《KD_WebQA_train.json》《KD_WebQA_train.jsonl》,同时压缩文件为原数据(付处理代码)
来源:百度知道的帖子(2017年的数据整理),共211741条问答对,1.3M的tokens总数(680k汉字总数),42M的tokens总数(21M汉字总数),json和jsonl的区别是json文件
格式为一个json列表,jsonl文件为每一个json数据一行
# 知识岛项目参与方式
QQ群:916663510
知识岛社区文档: https://docs.qq.com/aio/DVXZ6d3V6T2lYaENP?p=0Tv6BON3xXocBIBQ629PMO
Dodo平台:https://imdodo.com/s/209426?inv=4RL32 (主要看中了dodo类似于discord的在线语音功能以及积分系统,可以用来量化成员的贡献)
GitHub: https://github.com/shuliu586/KnowledgeDAO
# 知识岛需要的人
作为知识岛的发起者,很惭愧我不是专业的技术人员,只会简单的代码(不懂的请教项目上的大神以及GPT),因此,知识岛需要的人:
1、愿意分享行业经验的伙伴,共同参与AI行业专家的模型训练;
2、拥有IT技术的伙伴,为社区的发展添砖加瓦;
3、想要参与社区运营的伙伴,为社区稳步发展保驾护航;
4、天使投资者,看好知识岛,为知识岛的建设提供资金支持;
5、热心的参与者,参与知识岛社群规则建立,为社区的良性发展出谋划策。
# 训练效果
ChatGPT3.5 + LangChain + 餐饮行业8000问之后的训练效果(上面是原生的GPT3.5,下面是加上了餐饮行业8000问的效果)

提供机构:
LIUshu123
原始信息汇总
知识岛数据集概述
数据集介绍
知识岛项目旨在推进中文AI的发展,通过收集和整理中文数据集,促进AI技术的公开化和国际化。数据集的质量对模型性能至关重要,目前项目已收集多个领域的数据集。
数据集列表
-
餐饮行业数据集
- 文件名:《餐饮行业8000问.jsonl》
- 来源:2022年和2023年餐饮行业报告与行业白皮书
- 整理工具:chatGPT 3.5
- 数据量:8204条问答对
- 总tokens数:1.3M(680k汉字总数)
-
百度知道WebQA数据集
- 文件名:
- 测试数据集:《KD_WebQA_test.json》、《KD_WebQA_test.jsonl》
- 验证数据集:《KD_WebQA_validation.json》、《KD_WebQA_validation.jsonl》
- 训练数据集:《KD_WebQA_train.json》、《KD_WebQA_train.jsonl》
- 来源:百度知道的帖子(2017年数据整理)
- 数据量:211741条问答对
- 总tokens数:1.3M(680k汉字总数),42M(21M汉字总数)
- 格式说明:json文件格式为一个json列表,jsonl文件为每一个json数据一行
- 文件名:
项目参与方式
- QQ群:916663510
- 知识岛社区文档:https://docs.qq.com/aio/DVXZ6d3V6T2lYaENP?p=0Tv6BON3xXocBIBQ629PMO
- Dodo平台:https://imdodo.com/s/209426?inv=4RL32
- GitHub:https://github.com/shuliu586/KnowledgeDAO
项目需求
- 愿意分享行业经验的伙伴
- 拥有IT技术的伙伴
- 想要参与社区运营的伙伴
- 天使投资者
- 热心的参与者
训练效果
- 使用ChatGPT3.5 + LangChain + 餐饮行业8000问进行训练后的效果展示。
搜集汇总
数据集介绍
背景与挑战
背景概述
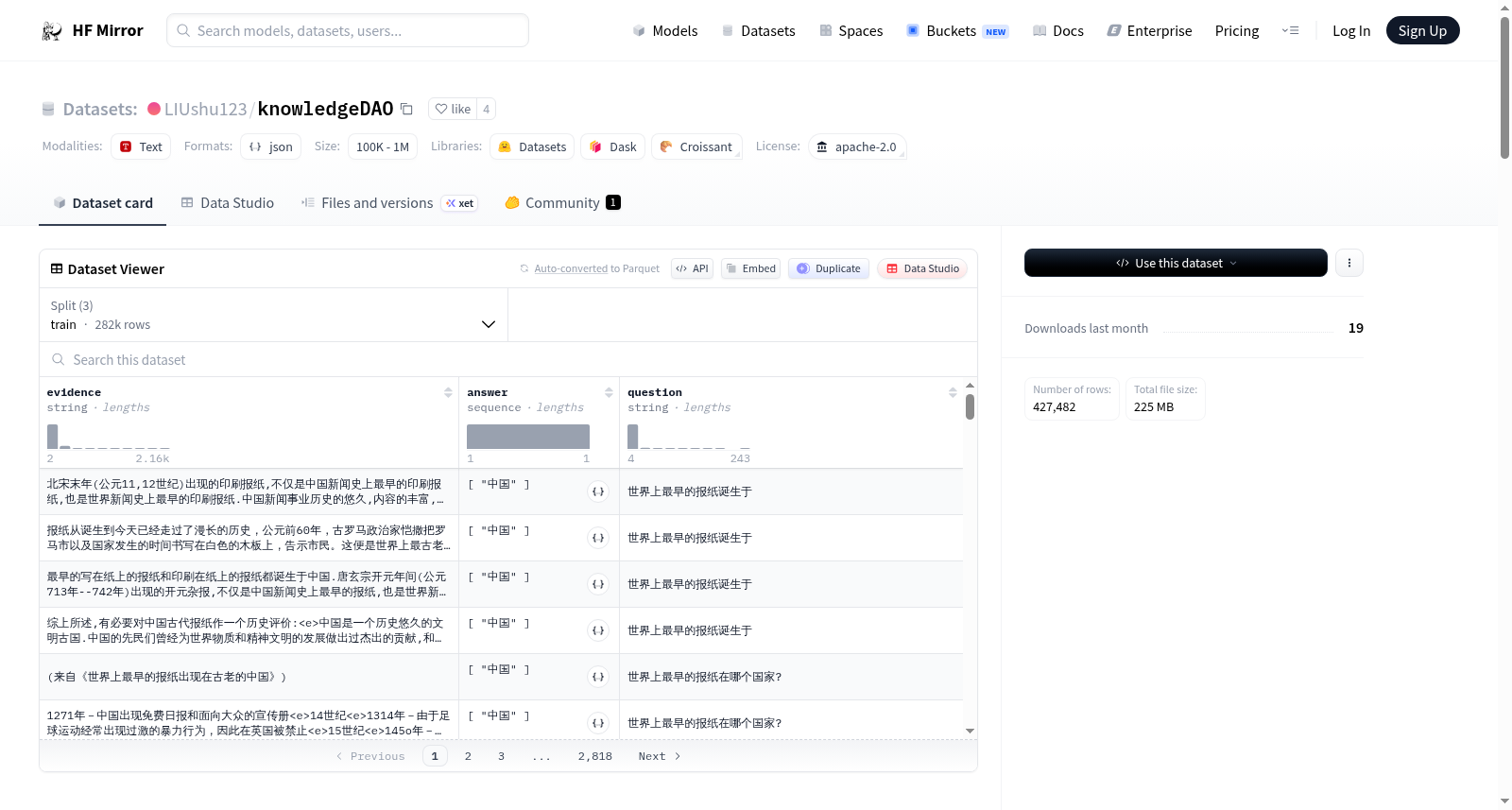
knowledgeDAO是一个中文问答数据集,包含约427,000条文本数据,涵盖餐饮行业、百度知道等多个领域,旨在支持AI模型的训练和优化。该数据集采用JSON格式,遵循Apache 2.0许可证,由社区驱动项目构建,以促进中文AI技术的发展。
以上内容由遇见数据集搜集并总结生成


