ArtificialAnalysis/AA-LCR
收藏Hugging Face2025-12-08 更新2025-08-09 收录
下载链接:
https://hf-mirror.com/datasets/ArtificialAnalysis/AA-LCR
下载链接
链接失效反馈官方服务:
资源简介:
AA-LCR数据集是一个包含100个基于文本的难题的数据集,这些难题需要跨多个真实世界文档进行推理。每个文档集合平均包含约10万个输入令牌。数据集的开发经历了多个阶段,包括问题编写和验证,文档的选择涵盖了多种类型,如公司报告、政府咨询、法律文件和学术论文等。问题需要使用文档集合进行通用和数学推理。
The AA-LCR dataset includes 100 text-based questions that require reasoning across multiple real-world documents, with each document set averaging ~100k input tokens. The development of the dataset involves multiple phases, including question writing and validation, and the selection of documents covers various types such as company reports, government consultations, legal documents, and academic papers. The questions require using the document set for general and mathematical reasoning.
提供机构:
ArtificialAnalysis
搜集汇总
数据集介绍
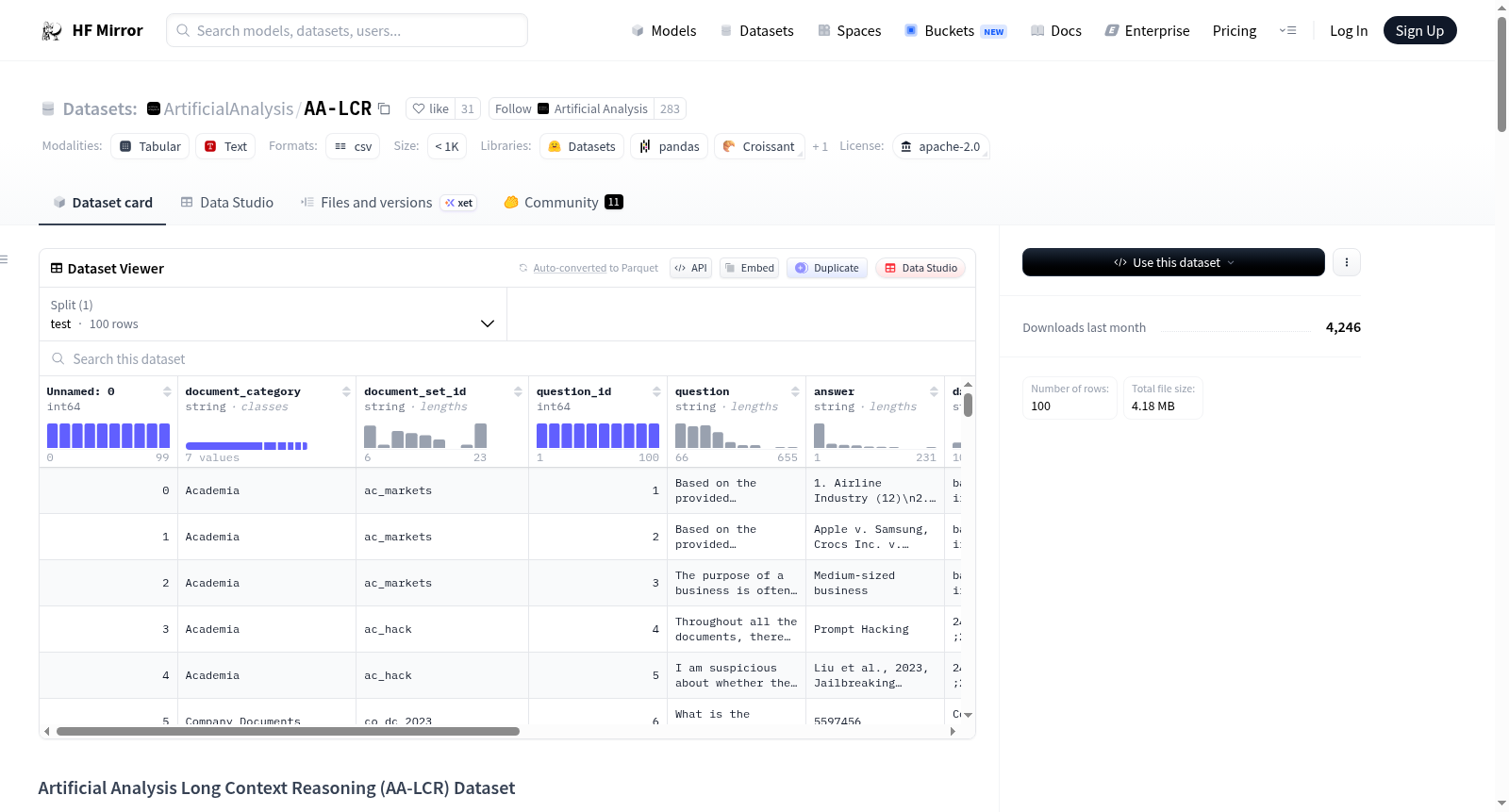
构建方式
在长文本推理研究领域,构建高质量的评估基准需要模拟真实的知识工作场景。AA-LCR数据集的构建遵循了严谨的多阶段流程。研究团队首先精心筛选了七类现实世界文档,包括公司报告、政府咨询文件和学术论文等,每个文档集平均包含约十万个标记。随后,来自不同学科的本科生在特定开发面板的辅助下,基于非前沿测试模型的能力感知,创作了需要跨文档综合推理的难题。每一道题目均经过严格的人工验证:评估者需独立使用相同文档集回答问题,其表现证实了基准的挑战性,同时所有题目均被至少一名人类测试者正确解答,确保了答案的可验证性与合理性。
特点
AA-LCR数据集的核心特征在于其专注于评估模型在超长上下文中的深度推理能力。该数据集包含一百道纯文本问题,每个问题关联一个平均长度约十万标记的独立文档集,总标记数接近三百万。题目设计刻意规避了直接检索答案的可能性,要求模型必须对公司财务、法律条文、学术研究等多元信息进行综合、比较与逻辑推导。其难度不仅体现在规模上,更体现在人类评估者首次尝试的准确率仅为40%至60%,这凸显了其对高级认知能力的考察。数据集覆盖了金融分析、法律解释、信息合成等多种问题类型,为衡量大语言模型在复杂、真实场景下的长程推理性能提供了精准的标尺。
使用方法
为有效利用AA-LCR数据集进行模型评估,需遵循其特定的数据处理与提示构建规范。研究人员首先从HuggingFace仓库下载包含问题元数据的CSV文件及对应的文档文本压缩包。对于每个问题,必须严格按照`data_source_filenames`字段指定的顺序,将提取的文档文本依次拼接,并嵌入预设的提示模板中,形成完整的模型输入。该模板明确划分了文档区域与问题区域。评估时,将模型生成的候选答案与官方答案一同提交给指定的评判模型(如Qwen3 235B),该模型严格依据一致性原则输出“CORRECT”或“INCORRECT”的二元判定。这种流程确保了评估过程的可复现性与客观性,聚焦于模型的核心推理能力。
背景与挑战
背景概述
在人工智能领域,长文本理解与推理能力是衡量大型语言模型认知深度的关键标尺。由Artificial Analysis研究团队于2025年创建的AA-LCR数据集,正是针对这一核心研究问题而设计的基准测试工具。该数据集聚焦于评估模型在跨越多个真实世界文档、处理约十万令牌级长上下文时的复杂推理性能。其研究团队通过精心策划,选取了公司报告、政府咨询、法律文书及学术论文等七类文本,构建了包含一百个高难度问题的集合。这些问题要求模型进行跨文档信息综合与逻辑推导,而非简单检索,旨在模拟知识工作者处理海量材料的真实场景,对推动语言模型在长上下文理解和复杂推理方面的发展具有显著影响力。
当前挑战
AA-LCR数据集所针对的领域挑战,在于解决当前大型语言模型在长上下文、多文档环境下进行深度推理的普遍性难题。具体而言,模型需要克服信息分散、逻辑关联隐蔽以及数学与条件推理交织的复杂性,而非依赖表层模式匹配。在数据集构建过程中,挑战同样显著:首先,确保问题的真实性与难度平衡至关重要,创作团队需设计出无法被非前沿模型轻易解决、却又具备明确可验证答案的问题;其次,大规模长文档的筛选与整理工作繁重,需保证文档集的多样性与代表性;最后,通过多轮人工验证来校准问题质量,确保其既能有效区分模型能力,又符合人类专家的推理逻辑,这一过程对资源协调与质量控制提出了较高要求。
常用场景
经典使用场景
在长文本理解与推理的研究领域,AA-LCR数据集为评估大型语言模型在超长上下文环境下的综合推理能力提供了经典基准。该数据集精心构建了平均约十万令牌的文档集合,涵盖公司报告、法律文件、学术论文等七类真实文本,并设计了无法通过简单检索直接获取答案的复杂问题。研究者通常利用该数据集,通过统一的提示模板将文档与问题输入模型,以系统测试模型在跨文档信息整合、逻辑推导及数学计算等方面的性能,从而精准衡量模型处理实际长文档分析任务的核心能力。
解决学术问题
AA-LCR数据集有效应对了当前大模型研究中长上下文推理评估标准缺失的核心挑战。它解决了如何量化模型在真实、复杂文档集合中进行深度分析与综合推理的学术问题,超越了传统短文本或合成数据评测的局限性。该数据集的意义在于其通过严谨的人类验证流程,确保了问题既具有足够难度,又具备明确的、可辩护的答案,从而将评估焦点从模型的知识记忆能力转向真正的推理技能。其影响在于为学术界提供了一个可靠、高难度的评测基准,推动了长上下文建模、信息检索与多步推理等关键方向的技术进步与模型迭代。
衍生相关工作
围绕AA-LCR数据集,已衍生出一系列聚焦于提升长上下文理解和推理能力的经典研究工作。这些工作主要探索更高效的上下文压缩与检索机制、改进的推理链生成策略,以及针对超长文本的注意力优化算法。同时,该数据集也常被用于对比研究不同模型架构(如Transformer变体)在长序列处理上的优劣,并催生了旨在提升模型跨文档信息关联与综合推理性能的新训练范式与评估协议。这些衍生研究共同推动了长文本处理技术向更实用、更可靠的方向发展。
以上内容由遇见数据集搜集并总结生成


