sagawa/pubchem-10m-canonicalized
收藏Hugging Face2022-09-04 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/sagawa/pubchem-10m-canonicalized
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators: []
language: []
language_creators:
- expert-generated
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: canonicalized PubChem-10m
size_categories:
- 100K<n<1M
source_datasets:
- original
tags:
- PubChem
- chemical
- SMILES
task_categories: []
task_ids: []
---
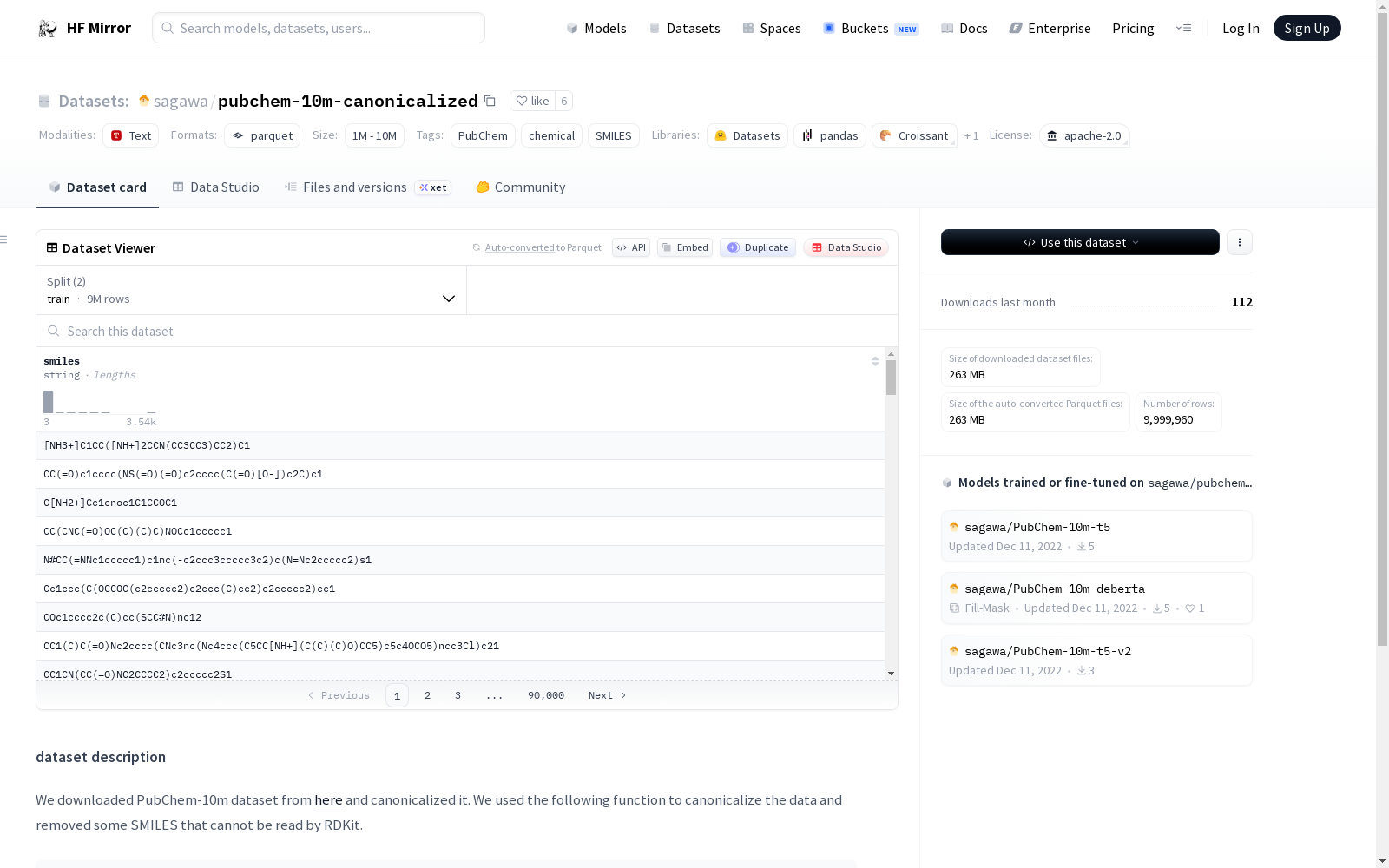
### dataset description
We downloaded PubChem-10m dataset from [here](https://deepchemdata.s3-us-west-1.amazonaws.com/datasets/pubchem_10m.txt.zip) and canonicalized it.
We used the following function to canonicalize the data and removed some SMILES that cannot be read by RDKit.
```python:
from rdkit import Chem
def canonicalize(mol):
mol = Chem.MolToSmiles(Chem.MolFromSmiles(mol),True)
return mol
```
We randomly split the preprocessed data into train and validation. The ratio is 9 : 1.
annotations_creators: []
language: []
language_creators:
- expert-generated
license:
- apache-2.0
multilinguality:
- monolingual
pretty_name: canonicalized PubChem-10m
size_categories:
- 100K<n<1M
source_datasets:
- original
tags:
- PubChem
- 化学
- SMILES(Simplified Molecular Input Line Entry System)
task_categories: []
task_ids: []
### 数据集说明
我们从指定链接(https://deepchemdata.s3-us-west-1.amazonaws.com/datasets/pubchem_10m.txt.zip)下载PubChem-10m数据集并完成标准化处理。
我们采用如下函数实现数据标准化,并剔除了无法被RDKit读取的SMILES(Simplified Molecular Input Line Entry System)字符串:
python:
from rdkit import Chem
def canonicalize(mol):
mol = Chem.MolToSmiles(Chem.MolFromSmiles(mol),True)
return mol
我们将预处理完成的数据集按照9:1的比例随机划分为训练集与验证集。
提供机构:
sagawa
原始信息汇总
数据集概述
- 名称: canonicalized PubChem-10m
- 语言: 单语种(Monolingual)
- 语言生成方式: 专家生成(expert-generated)
- 许可证: Apache-2.0
- 数据集大小: 100K<n<1M
- 数据来源: 原始数据(original)
- 标签:
- PubChem
- chemical
- SMILES
- 数据处理:
- 数据从此处下载并进行规范化处理。
- 使用RDKit工具对数据进行规范化,移除了无法被RDKit读取的SMILES数据。
- 数据被随机分为训练集和验证集,比例为9:1。
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集包含约1000万条经过规范化的化学分子SMILES字符串,主要用于化学信息学和机器学习研究。数据集已划分为900万条训练数据和100万条验证数据,格式为Parquet,总大小为263MB。
以上内容由遇见数据集搜集并总结生成


