stanfordnlp/imdb
收藏Hugging Face2024-01-04 更新2024-04-19 收录
下载链接:
https://hf-mirror.com/datasets/stanfordnlp/imdb
下载链接
链接失效反馈资源简介:
---
annotations_creators:
- expert-generated
language_creators:
- expert-generated
language:
- en
license:
- other
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- sentiment-classification
paperswithcode_id: imdb-movie-reviews
pretty_name: IMDB
dataset_info:
config_name: plain_text
features:
- name: text
dtype: string
- name: label
dtype:
class_label:
names:
'0': neg
'1': pos
splits:
- name: train
num_bytes: 33432823
num_examples: 25000
- name: test
num_bytes: 32650685
num_examples: 25000
- name: unsupervised
num_bytes: 67106794
num_examples: 50000
download_size: 83446840
dataset_size: 133190302
configs:
- config_name: plain_text
data_files:
- split: train
path: plain_text/train-*
- split: test
path: plain_text/test-*
- split: unsupervised
path: plain_text/unsupervised-*
default: true
train-eval-index:
- config: plain_text
task: text-classification
task_id: binary_classification
splits:
train_split: train
eval_split: test
col_mapping:
text: text
label: target
metrics:
- type: accuracy
- name: Accuracy
- type: f1
name: F1 macro
args:
average: macro
- type: f1
name: F1 micro
args:
average: micro
- type: f1
name: F1 weighted
args:
average: weighted
- type: precision
name: Precision macro
args:
average: macro
- type: precision
name: Precision micro
args:
average: micro
- type: precision
name: Precision weighted
args:
average: weighted
- type: recall
name: Recall macro
args:
average: macro
- type: recall
name: Recall micro
args:
average: micro
- type: recall
name: Recall weighted
args:
average: weighted
---
# Dataset Card for "imdb"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [http://ai.stanford.edu/~amaas/data/sentiment/](http://ai.stanford.edu/~amaas/data/sentiment/)
- **Repository:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 84.13 MB
- **Size of the generated dataset:** 133.23 MB
- **Total amount of disk used:** 217.35 MB
### Dataset Summary
Large Movie Review Dataset.
This is a dataset for binary sentiment classification containing substantially more data than previous benchmark datasets. We provide a set of 25,000 highly polar movie reviews for training, and 25,000 for testing. There is additional unlabeled data for use as well.
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Structure
### Data Instances
#### plain_text
- **Size of downloaded dataset files:** 84.13 MB
- **Size of the generated dataset:** 133.23 MB
- **Total amount of disk used:** 217.35 MB
An example of 'train' looks as follows.
```
{
"label": 0,
"text": "Goodbye world2\n"
}
```
### Data Fields
The data fields are the same among all splits.
#### plain_text
- `text`: a `string` feature.
- `label`: a classification label, with possible values including `neg` (0), `pos` (1).
### Data Splits
| name |train|unsupervised|test |
|----------|----:|-----------:|----:|
|plain_text|25000| 50000|25000|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@InProceedings{maas-EtAl:2011:ACL-HLT2011,
author = {Maas, Andrew L. and Daly, Raymond E. and Pham, Peter T. and Huang, Dan and Ng, Andrew Y. and Potts, Christopher},
title = {Learning Word Vectors for Sentiment Analysis},
booktitle = {Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies},
month = {June},
year = {2011},
address = {Portland, Oregon, USA},
publisher = {Association for Computational Linguistics},
pages = {142--150},
url = {http://www.aclweb.org/anthology/P11-1015}
}
```
### Contributions
Thanks to [@ghazi-f](https://github.com/ghazi-f), [@patrickvonplaten](https://github.com/patrickvonplaten), [@lhoestq](https://github.com/lhoestq), [@thomwolf](https://github.com/thomwolf) for adding this dataset.
annotations_creators:
- 专家生成
language_creators:
- 专家生成
language:
- 英语(en)
license:
- 其他(other)
multilinguality:
- 单语言(monolingual)
size_categories:
- 10000<样本数<100000
source_datasets:
- 原始数据集(original)
task_categories:
- 文本分类(text-classification)
task_ids:
- 情感分类(sentiment-classification)
paperswithcode_id: imdb-movie-reviews
pretty_name: IMDB
dataset_info:
config_name: plain_text
features:
- name: text
dtype: 字符串(string)
- name: label
dtype:
class_label:
names:
'0': neg(负面)
'1': pos(正面)
splits:
- name: 训练集(train)
num_bytes: 33432823
num_examples: 25000
- name: 测试集(test)
num_bytes: 32650685
num_examples: 25000
- name: 无监督集(unsupervised)
num_bytes: 67106794
num_examples: 50000
download_size: 83446840
dataset_size: 133190302
configs:
- config_name: plain_text
data_files:
- split: 训练集(train)
path: plain_text/train-*
- split: 测试集(test)
path: plain_text/test-*
- split: 无监督集(unsupervised)
path: plain_text/unsupervised-*
default: true
train-eval-index:
- config: plain_text
task: 文本分类(text-classification)
task_id: 二元分类(binary_classification)
splits:
train_split: 训练集(train)
eval_split: 测试集(test)
col_mapping:
text: text
label: target
metrics:
- type: 准确率(accuracy)
name: 准确率(Accuracy)
- type: F1值
name: 宏平均F1(F1 macro)
args:
average: 宏平均(macro)
- type: F1值
name: 微平均F1(F1 micro)
args:
average: 微平均(micro)
- type: F1值
name: 加权平均F1(F1 weighted)
args:
average: 加权平均(weighted)
- type: 精确率(precision)
name: 宏平均精确率(Precision macro)
args:
average: 宏平均(macro)
- type: 精确率(precision)
name: 微平均精确率(Precision micro)
args:
average: 微平均(micro)
- type: 精确率(precision)
name: 加权平均精确率(Precision weighted)
args:
average: 加权平均(weighted)
- type: 召回率(recall)
name: 宏平均召回率(Recall macro)
args:
average: 宏平均(macro)
- type: 召回率(recall)
name: 微平均召回率(Recall micro)
args:
average: 微平均(micro)
- type: 召回率(recall)
name: 加权平均召回率(Recall weighted)
args:
average: 加权平均(weighted)
# "IMDB"数据集卡片
## 目录
- [数据集描述](#dataset-description)
- [数据集摘要](#dataset-summary)
- [支持的任务与基准排行榜](#supported-tasks-and-leaderboards)
- [语言](#languages)
- [数据集结构](#dataset-structure)
- [数据实例](#data-instances)
- [数据字段](#data-fields)
- [数据划分](#data-splits)
- [数据集创建](#dataset-creation)
- [数据集构建初衷](#curation-rationale)
- [源数据](#source-data)
- [注释标注](#annotations)
- [个人与敏感信息](#personal-and-sensitive-information)
- [数据使用注意事项](#considerations-for-using-the-data)
- [数据集的社会影响](#social-impact-of-dataset)
- [偏差讨论](#discussion-of-biases)
- [其他已知局限性](#other-known-limitations)
- [附加信息](#additional-information)
- [数据集维护者](#dataset-curators)
- [授权信息](#licensing-information)
- [引用信息](#citation-information)
- [贡献者](#contributions)
## 数据集描述
- **主页**:[http://ai.stanford.edu/~amaas/data/sentiment/](http://ai.stanford.edu/~amaas/data/sentiment/)
- **代码仓库**:[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **论文**:[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **联系人**:[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **下载数据集大小**:84.13 MB
- **生成后数据集大小**:133.23 MB
- **总磁盘占用**:217.35 MB
### 数据集摘要
大型电影评论数据集(Large Movie Review Dataset)。本数据集用于二元情感分类任务,相较以往的基准数据集包含更多数据。我们提供了25000条高极性电影评论用于训练,25000条用于测试,此外还有额外的无标注数据可供使用。
### 支持的任务与基准排行榜
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 语言
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 数据集结构
### 数据实例
#### plain_text
- **下载数据集大小**:84.13 MB
- **生成后数据集大小**:133.23 MB
- **总磁盘占用**:217.35 MB
训练集的一个示例如下:
{
"label": 0,
"text": "Goodbye world2
"
}
### 数据字段
所有数据划分的字段均保持一致。
#### plain_text
- `text`:字符串类型特征。
- `label`:分类标签,可选值包括`neg`(0,负面情感)、`pos`(1,正面情感)。
### 数据划分
| 划分名称 | 训练集 | 无监督集 | 测试集 |
|----------|-------:|---------:|-------:|
| plain_text | 25000 | 50000 | 25000 |
## 数据集创建
### 数据集构建初衷
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 源数据
#### 初始数据收集与标准化
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### 源语言生产者是谁?
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 注释标注
#### 标注流程
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### 标注者是谁?
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 个人与敏感信息
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 数据使用注意事项
### 数据集的社会影响
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 偏差讨论
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 其他已知局限性
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## 附加信息
### 数据集维护者
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 授权信息
[更多信息待补充](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### 引用信息
@InProceedings{maas-EtAl:2011:ACL-HLT2011,
author = {Maas, Andrew L. and Daly, Raymond E. and Pham, Peter T. and Huang, Dan and Ng, Andrew Y. and Potts, Christopher},
title = {Learning Word Vectors for Sentiment Analysis},
booktitle = {Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies},
month = {June},
year = {2011},
address = {Portland, Oregon, USA},
publisher = {Association for Computational Linguistics},
pages = {142--150},
url = {http://www.aclweb.org/anthology/P11-1015}
}
### 贡献者
感谢[@ghazi-f](https://github.com/ghazi-f)、[@patrickvonplaten](https://github.com/patrickvonplaten)、[@lhoestq](https://github.com/lhoestq)、[@thomwolf](https://github.com/thomwolf) 为本数据集的添加做出贡献。
提供机构:
stanfordnlp
原始信息汇总
数据集概述
基本信息
- 数据集名称: IMDB
- 数据集ID: imdb-movie-reviews
- 语言: 英语(en)
- 许可证: 其他
- 多语言性: 单语种
- 数据集大小: 10K<n<100K
- 源数据集: 原始数据
- 任务类别: 文本分类
- 任务ID: 情感分类
数据集结构
数据字段
- text: 字符串类型,文本内容。
- label: 分类标签,可能的值包括
neg(0) 和pos(1)。
数据分割
- 训练集: 25000个样本
- 测试集: 25000个样本
- 无监督学习集: 50000个样本
数据集创建
注释和语言创建
- 注释创建者: 专家生成
- 语言创建者: 专家生成
使用考虑
训练与评估指标
- 配置: plain_text
- 任务: 文本分类
- 任务ID: 二分类
- 训练分割: 训练集
- 评估分割: 测试集
- 列映射:
text: 文本label: 目标
- 评估指标:
- 准确率 (Accuracy)
- F1分数 (F1 macro, F1 micro, F1 weighted)
- 精确率 (Precision macro, Precision micro, Precision weighted)
- 召回率 (Recall macro, Recall micro, Recall weighted)
搜集汇总
数据集介绍
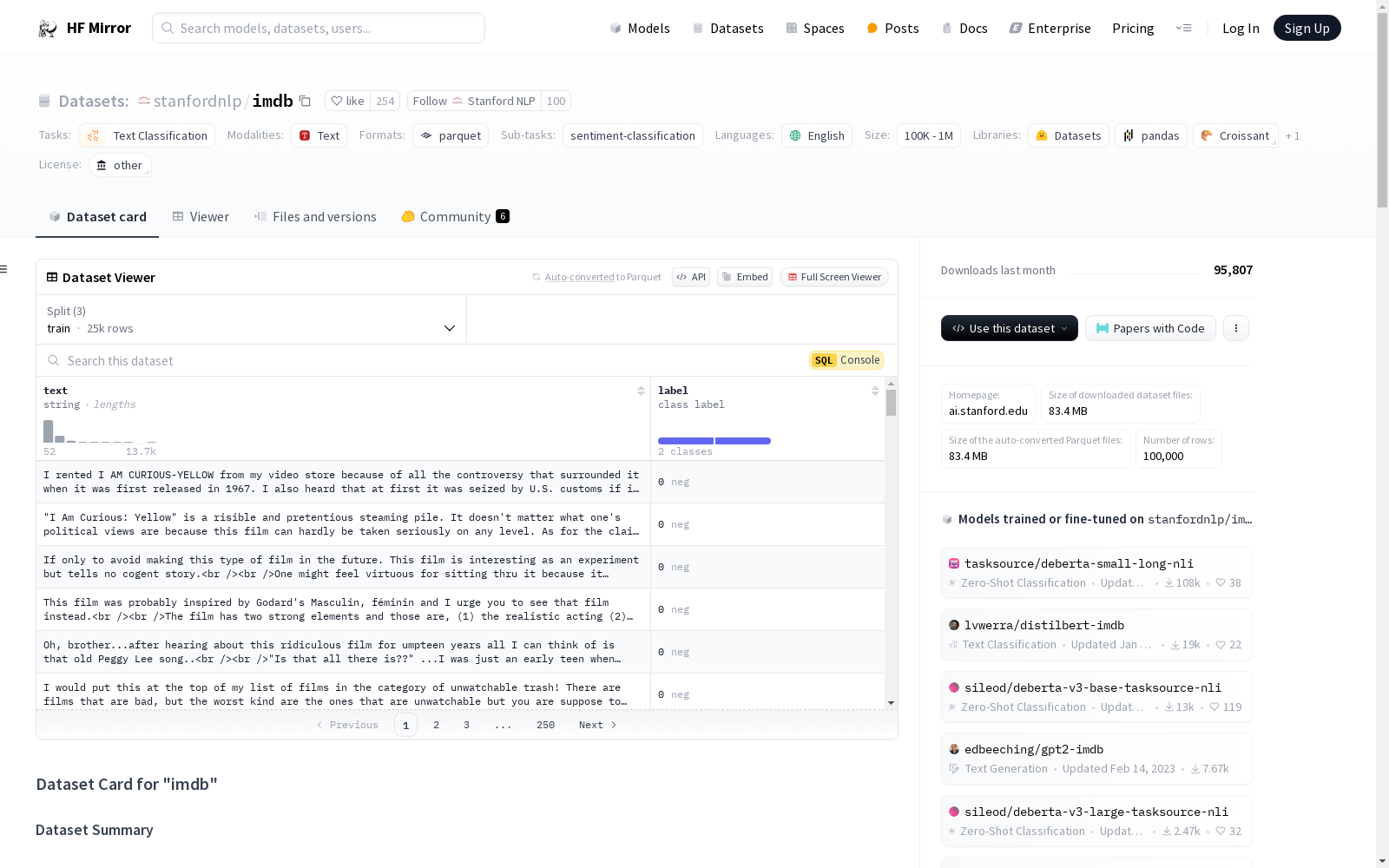
构建方式
该数据集由专家生成,包含25,000条高度极化的电影评论用于训练,25,000条用于测试,并额外提供了50,000条未标注的数据。数据集的构建旨在为二元情感分类提供一个比以往基准数据集更为丰富的资源,确保了数据的高质量和多样性。
特点
IMDB数据集的主要特点在于其大规模和极性明显的电影评论,涵盖了正面和负面两种情感标签。此外,数据集提供了明确的训练、测试和无监督学习划分,使得研究者可以在不同的任务场景中灵活应用。
使用方法
该数据集适用于文本分类任务,特别是情感分类。用户可以通过加载'plain_text'配置来访问数据,数据包含'text'和'label'两个字段。训练集和测试集分别包含25,000条数据,而无监督集则包含50,000条未标注数据,适合用于预训练或数据增强。
背景与挑战
背景概述
IMDB数据集,由Stanford NLP团队创建,是一个用于二元情感分类的大型电影评论数据集。该数据集包含25,000条高度极化的电影评论用于训练,以及25,000条用于测试,此外还有额外的未标注数据。该数据集的创建旨在提供比先前基准数据集更多的数据,以推动情感分析领域的发展。通过提供丰富的文本数据和明确的情感标签,IMDB数据集已成为自然语言处理领域中情感分析任务的重要基准。
当前挑战
IMDB数据集在构建过程中面临的主要挑战包括数据标注的复杂性和数据集的平衡性。首先,情感分类任务要求对文本进行精确的情感标注,这需要专家的参与,确保标注的准确性和一致性。其次,数据集的平衡性也是一个重要问题,确保正负样本的分布均匀,以避免模型在训练过程中出现偏差。此外,处理大量未标注数据以提取有用的信息,也是该数据集构建过程中的一大挑战。
常用场景
经典使用场景
IMDB数据集在情感分析领域中被广泛应用于二元情感分类任务。该数据集包含25,000条高度极性的电影评论用于训练,以及25,000条用于测试,为研究者提供了一个标准化的基准来评估情感分析模型的性能。通过分析这些评论的文本内容,模型能够学习到如何区分正面和负面情感,从而在实际应用中实现高效的情感分类。
解决学术问题
IMDB数据集解决了情感分析领域中缺乏大规模、高质量标注数据的问题。通过提供大量标注数据,该数据集使得研究者能够训练和验证情感分析模型,推动了情感分类技术的进步。此外,该数据集还为研究者提供了一个标准化的基准,便于不同模型之间的性能比较,从而促进了情感分析领域的学术研究。
衍生相关工作
IMDB数据集的发布激发了大量相关研究工作,尤其是在情感分析和文本分类领域。许多研究者基于该数据集提出了新的情感分类模型,如基于深度学习的情感分析模型和基于预训练语言模型的情感分类方法。此外,该数据集还被广泛用于评估不同情感分析算法的性能,推动了情感分析技术的不断进步。
以上内容由遇见数据集搜集并总结生成


