CounterBench
收藏arXiv2025-02-16 更新2025-02-19 收录
下载链接:
https://huggingface.co/datasets/CounterBench/CounterBench
下载链接
链接失效反馈官方服务:
资源简介:
CounterBench是一个专为评估大型语言模型在反事实推理任务上的性能而设计的综合数据集。该数据集由Rutgers University创建,包含1000个反事实推理问题,涵盖不同的难度级别、因果图结构、反事实问题类型和非 sensical名称变体。数据集中的问题旨在通过要求真正的推理而不仅仅是模式识别或记忆响应,系统地评估四个关键维度。该数据集适用于医疗保健、商业、公共管理等领域,支持对错过的机会和替代结果进行评估,从而指导决策制定。
CounterBench is a comprehensive dataset specifically engineered to evaluate the performance of large language models (LLMs) on counterfactual reasoning tasks. Created by Rutgers University, it comprises 1000 counterfactual reasoning problems covering diverse difficulty levels, causal graph structures, counterfactual question types, and nonsensical name variants. The problems within this dataset are designed to systematically evaluate four key dimensions by requiring genuine reasoning rather than mere pattern recognition or memorized responses. This dataset is applicable across domains including healthcare, business, and public administration, supporting the assessment of missed opportunities and alternative outcomes to guide decision-making.
提供机构:
Rutgers University
创建时间:
2025-02-16
搜集汇总
数据集介绍
构建方式
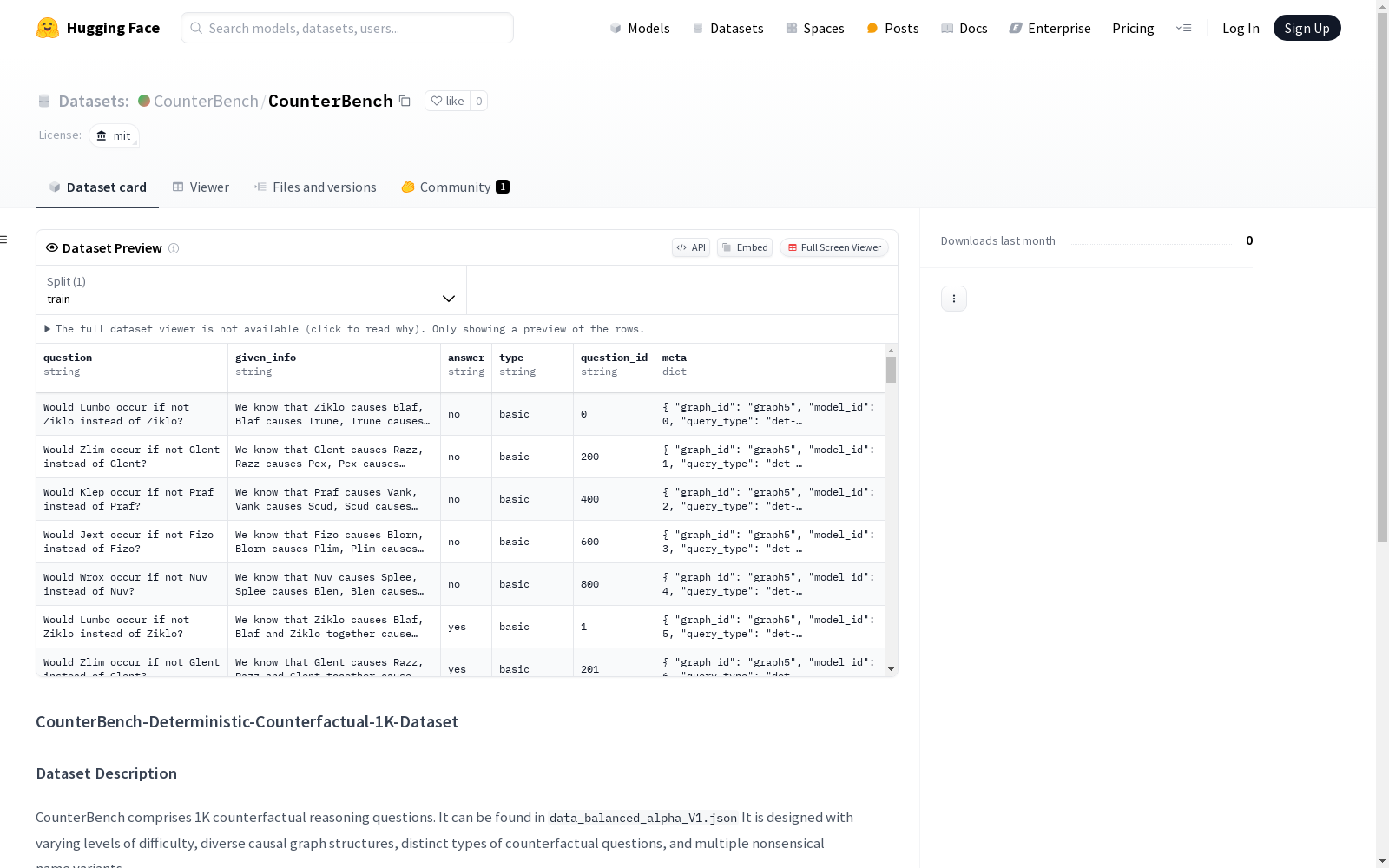
CounterBench 数据集的构建旨在评估大型语言模型 (LLM) 在反事实推理方面的能力。该数据集包含 1,000 个反事实推理问题,这些问题具有不同的难度级别、多样的因果图结构、不同的反事实问题类型以及多个无意义的名称变体。这些问题是根据确定性结构因果模型 (SCM) 构建的,每个问题都包含背景信息和具体问题,并以二元答案(是/否)表示。此外,数据集还进行了分层,根据每个问题中事件的数量分为五个难度级别,以确保问题的均匀分布和答案的平衡分布。
特点
CounterBench 数据集的特点在于其全面性和多样性。数据集中的问题涵盖了不同的领域和推理类型,并且具有不同的难度级别,这要求模型进行真正的推理,而不仅仅是模式识别或记忆响应。数据集还包含了多个无意义的名称变体,以防止模型依赖于预训练数据中的记忆知识,从而迫使模型进行因果推理。此外,数据集还进行了平衡分布,以避免偏差并确保每个问题和类型都有均匀的答案分布。
使用方法
CounterBench 数据集的使用方法包括评估大型语言模型在反事实推理任务上的性能。研究人员可以使用该数据集来测试和比较不同 LLM 的性能,并分析其推理过程中的错误。此外,数据集还可以用于训练和改进 LLM 的反事实推理能力,以及开发新的推理策略。为了提高 LLM 的反事实推理能力,研究人员还提出了一种新的推理范式 CoIn,该范式通过迭代推理和回溯来引导 LLM 系统地探索反事实解决方案。实验结果表明,CoIn 方法显著提高了 LLM 在反事实推理任务上的性能,并一致地提高了不同 LLM 的性能。
背景与挑战
背景概述
Counterfactual reasoning is a critical aspect of causality in artificial intelligence, essential for understanding and predicting alternative outcomes based on hypothetical changes in variables. The CounterBench dataset, developed by researchers at Rutgers University and Case Western Reserve University, aims to evaluate the counterfactual reasoning capabilities of large language models (LLMs). This dataset, introduced in a paper by Yuefei Chen et al., is designed to challenge LLMs with 1,000 counterfactual reasoning questions, each with varying difficulty levels, diverse causal graph structures, and distinct types of counterfactual scenarios. The creation of CounterBench addresses the lack of a dedicated benchmark for evaluating LLMs in counterfactual reasoning, providing a standardized platform for assessing their ability to handle complex causal relationships. The dataset's impact is significant as it exposes the limitations of current LLMs in counterfactual reasoning and paves the way for the development of more sophisticated reasoning paradigms, such as CoIn, which enhances LLM performance by guiding them through iterative reasoning and backtracking.
当前挑战
The CounterBench dataset presents several challenges in the realm of counterfactual reasoning for LLMs. Firstly, the dataset reveals that LLMs often perform at levels comparable to random guessing, highlighting the difficulty of capturing nuanced causal relationships. This challenge stems from the complexity of counterfactual scenarios and the need for sophisticated reasoning beyond pattern recognition. Secondly, the dataset demonstrates that even advanced prompting techniques, such as CausalCoT, offer only marginal improvements in LLM performance. This indicates a need for more effective strategies that can guide LLMs through the intricacies of counterfactual reasoning. The CounterBench dataset also poses a challenge in the construction of counterfactual scenarios that require LLMs to engage in genuine reasoning rather than relying on prior knowledge. The dataset's design, with nonsensical names and diverse causal graph structures, forces LLMs to derive logical conclusions based on the explicit information provided, thereby pushing the boundaries of their reasoning capabilities. Lastly, the dataset's evaluation of state-of-the-art LLMs shows a consistent struggle with maintaining logical coherence during multi-step reasoning processes, emphasizing the need for enhanced reasoning frameworks that can systematically explore counterfactual solutions.
常用场景
经典使用场景
CounterBench数据集为大型语言模型(LLMs)在反事实推理方面的性能评估提供了一个全面的基准。该数据集包含1,000个反事实推理问题,涵盖了不同的难度水平、多样化的因果图结构、不同的反事实问题类型以及多个无意义的名称变体。通过对LLMs在CounterBench上的表现进行评估,研究人员发现,反事实推理对LLMs构成了重大挑战,大多数模型的性能与随机猜测相当。为了提高LLMs的反事实推理能力,研究人员提出了一种新的推理范式,称为CoIn,该范式通过迭代推理和回溯来引导LLMs系统地探索反事实解决方案。实验结果表明,CoIn方法显著提高了LLMs在反事实推理任务上的性能,并在不同的LLMs上始终如一地增强了性能。
实际应用
CounterBench数据集的实际应用场景广泛,包括但不限于医疗保健、商业、公共行政和科学研究等领域。在医疗保健领域,CounterBench可以帮助评估替代治疗方案的潜在效果,从而为临床决策提供支持。在商业领域,CounterBench可以帮助预测不同决策对业务结果的影响,从而优化商业策略。在公共行政领域,CounterBench可以帮助评估政策干预的影响,从而提高政策制定的科学性和有效性。在科学研究领域,CounterBench可以帮助探索因果关系,从而推动科学知识的进步。
衍生相关工作
CounterBench数据集衍生了多项相关研究工作,其中最具代表性的是CoIn推理范式。CoIn方法通过迭代推理和回溯来引导LLMs系统地探索反事实解决方案,显著提高了LLMs在反事实推理任务上的性能。此外,CounterBench数据集还推动了LLMs在反事实推理方面的研究,为未来的研究和应用提供了重要的基础。
以上内容由遇见数据集搜集并总结生成


