Estonian Subjectivity Dataset
收藏arXiv2025-12-10 更新2025-12-12 收录
下载链接:
https://huggingface.co/datasets/tartuNLP/Estonian_Subjectivity
下载链接
链接失效反馈官方服务:
资源简介:
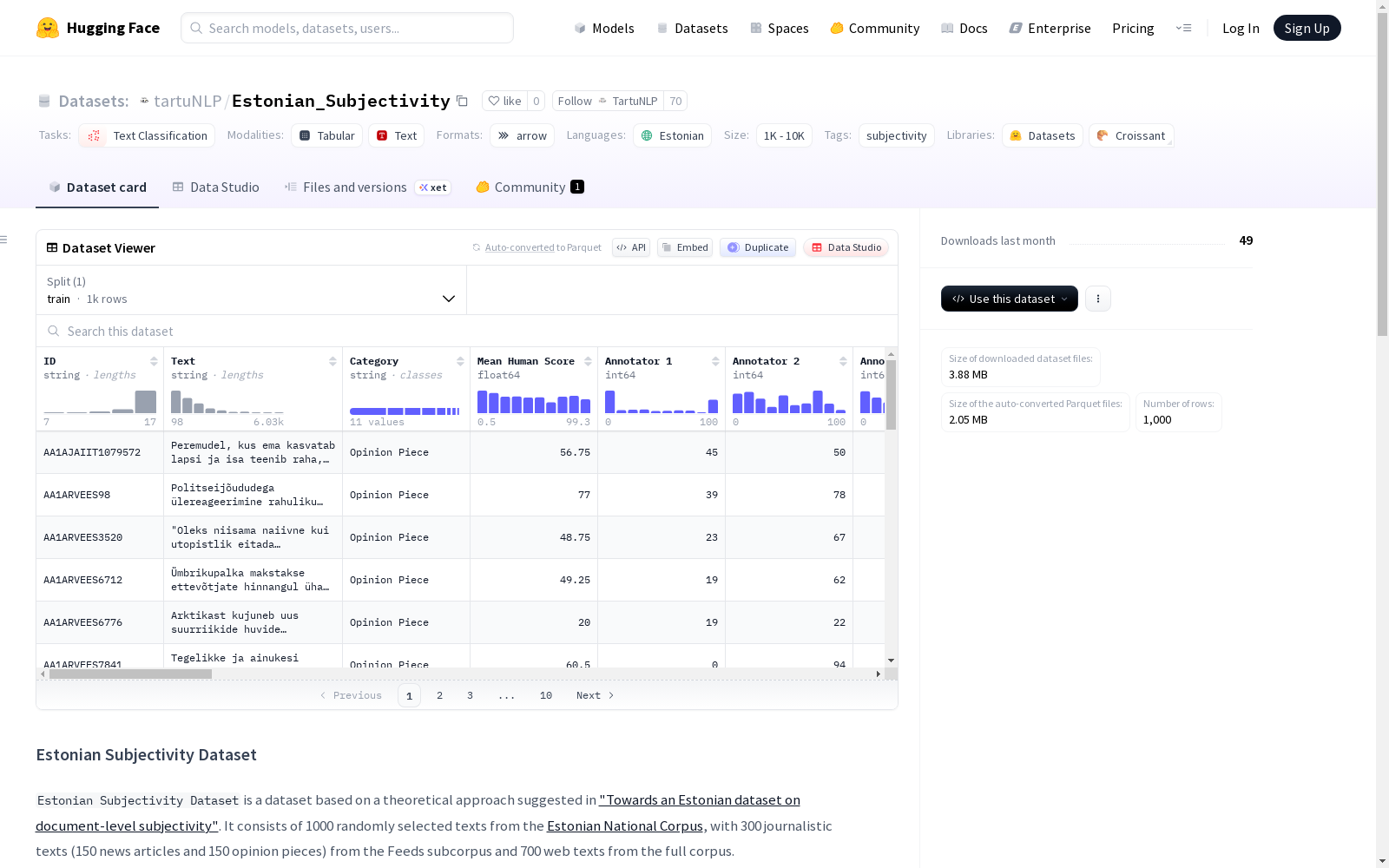
爱沙尼亚主观性数据集由塔尔图大学构建,是首个针对爱沙尼亚语文档级主观性分析的标注资源。该数据集包含1000篇文本(300篇新闻文章和700篇随机网络文本),每条文本由4名标注者采用0-100连续尺度标注主观性程度,并融合了GPT-5的自动化标注结果作为对比实验。数据源自2021年爱沙尼亚国家语料库,经过严格的长度筛选(100-6000字符)和隐私脱敏处理,涵盖新闻、社论、广告等10个不平衡分布的文本类别。该数据集旨在支持细粒度主观性分析研究,为情感分析、立场检测等NLP任务提供爱沙尼亚语基准,同时探索大语言模型在主观性标注中的适用性边界。
The Estonian Subjectivity Dataset, developed by the University of Tartu, is the first annotated resource for document-level subjectivity analysis of the Estonian language. This dataset includes 1,000 texts: 300 news articles and 700 randomly sampled web texts. Each text was annotated for its subjectivity level by four annotators using a continuous 0–100 scale, and automated annotation results from GPT-5 were added as a comparative experimental baseline. The dataset is derived from the 2021 Estonian National Corpus, and has undergone strict length filtering (100–6000 characters) and privacy de-identification processing. It covers 10 imbalanced text categories such as news, editorials, advertisements and more. This dataset is intended to support fine-grained subjectivity analysis research, provide an Estonian-language benchmark for NLP tasks including sentiment analysis and stance detection, and explore the applicability boundaries of Large Language Models (LLMs) in subjectivity annotation.
提供机构:
塔尔图大学
创建时间:
2025-12-10
原始信息汇总
爱沙尼亚主观性数据集概述
数据集基本信息
- 数据集名称:Estonian Subjectivity Dataset
- 数据集标识:tartuNLP/Estonian_Subjectivity
- 语言:爱沙尼亚语 (et)
- 任务类别:文本分类
- 数据规模:小于1K条样本
- 配置名称:default
数据来源与构成
- 基于理论方法构建,相关论文为"Towards an Estonian dataset on document-level subjectivity"。
- 包含1000条从爱沙尼亚国家语料库中随机选取的文本。
- 其中300条为新闻文本(150篇新闻报道和150篇评论文章),来自Feeds子语料库;700条为网络文本,来自完整语料库。
标注信息
- 由4名标注者对文本的主观性进行标注,使用0(客观)到100(主观)的滑动评分尺度。
- 标注者还需使用3点李克特量表提供其标注的置信度。
- 额外选取了250条文本由两名原始标注者进行重新标注。该子集包含220条评分差异较大的文本以及30条控制文本。
数据列描述
- ID:唯一标识符
- Text:完整的标注文本(爱沙尼亚语)
- Category:文本的类别或体裁
- Mean Human Score:所有4名标注者评分的平均值(0到100之间的整数)
- Annotator 1-4:单个标注者对文本的评分(0到100之间的整数)
- Annotator 1-4 Certainty:单个标注者对其评分的置信度
- Annotator 2 & 3 Addition:仅适用于重新标注子集,单个标注者对文本的评分(0到100之间的整数)
- Annotator 2 & 3 Addition Certainty:仅适用于重新标注子集,单个标注者对其评分的置信度
- Mean GPT Score:所有3批GPT-5评分的平均值(0到100之间的整数)
- GPT Score 1-3:GPT-5对文本的评分,三个提示各为一列
- GPT Explanation 1-3:GPT-5对给出评分的解释,三个提示各为一列
- Number of Characters:文本字符数
- Number of Words:文本词数(使用EstNLTK计算)
- Number of Sentences:文本句子数(使用EstNLTK计算)
- Batch:文本所属的初始批次(共四批)
- Original Metadata:爱沙尼亚国家语料库提供的文本元数据
数据加载方式
Python
python from datasets import load_dataset ds = load_dataset("tartuNLP/Estonian_Subjectivity")["train"] print(ds[0])
R (使用 arrow 包)
r library(arrow) data <- read_ipc_stream(file = "https://huggingface.co/datasets/tartuNLP/Estonian_Subjectivity/resolve/main/data-00000-of-00001.arrow", as_data_frame = TRUE)
引用要求
使用本数据集时,请按如下方式引用:
[Insert Arxiv citation]
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,构建高质量的主观性数据集对于理解文本中的观点与情感至关重要。爱沙尼亚主观性数据集的构建采用了严谨的多阶段流程,首先通过小规模试点研究验证了连续评分量表的可行性,随后从爱沙尼亚国家语料库2021版中选取了1000篇文本,包括700篇随机网络文本和300篇新闻与评论文章,所有文本长度均控制在100至6000字符之间。四名标注者使用0至100的连续量表对每篇文本进行主观性评分,其中0代表完全客观,100代表完全主观。针对标注者间分歧较大的文本子集,研究还进行了二次标注,以提高标注结果的一致性。此外,数据集还包含了由GPT-5生成的自动化评分,为探索大语言模型在主观性标注中的应用提供了实验数据。
特点
该数据集在主观性研究领域展现出若干鲜明特点。其核心创新在于采用了连续数值量表而非传统的二元分类,这更贴合人类对主观性的渐进式感知,能够捕捉文本中细微的主观性程度差异。数据集的文本来源多样,涵盖新闻、评论、广告、社交媒体等多种体裁,确保了语言风格和主题的广泛代表性。标注过程中不仅收集了主观性评分,还记录了标注者的确信度,为分析标注不确定性提供了额外维度。尤为重要的是,数据集同时包含了人类标注与大语言模型生成的评分,使得研究者能够系统比较两者在主观性判断上的异同,例如人类更易受非正式语言风格影响,而模型则更关注文本内容本身。
使用方法
该数据集为爱沙尼亚语的主观性分析与模型训练提供了重要资源。研究者可直接使用数据集中四位人类标注者的平均评分作为连续的主观性标签,用于训练回归模型以预测文本的主观性程度。对于分类任务,用户可根据应用场景设定阈值,将连续评分转换为客观或主观的类别标签。数据集中的GPT-5评分可用于探索自动化标注的可行性,或作为模型训练的辅助特征。在进行语言学分析时,标注者间的分歧数据可用于研究影响主观性判断的因素,如文本体裁或语言特征。此外,该数据集可作为基准测试集,用于评估不同主观性检测模型在爱沙尼亚语上的性能,推动低资源语言自然语言处理技术的发展。
背景与挑战
背景概述
在自然语言处理领域,主观性分析旨在区分表达作者观点或情感的主观语言与陈述事实的客观语言,这对于情感分析、立场检测等任务至关重要。爱沙尼亚主观性数据集由塔尔图大学的研究团队于2025年创建,旨在填补爱沙尼亚语在文档级主观性标注资源上的空白。该数据集包含1000个文档,涵盖新闻文章与随机网络文本,由四位标注者使用连续数值尺度(0至100)进行主观性评分,并探索了大型语言模型在自动标注中的应用。该资源的建立为低资源语言的主观性建模提供了重要基础,推动了跨语言主观性分析研究的发展。
当前挑战
该数据集致力于解决文档级主观性分析的挑战,即如何准确量化文本的主观性程度,而非进行简单的二元分类。构建过程中的主要挑战包括:确保标注者间一致性,尽管使用了连续尺度,但不同标注者对主观性的理解存在差异,导致评分相关性仅为中等水平;处理文本多样性带来的标注困难,随机选取的网络文本在主题、风格和类型上差异显著,增加了标注复杂度;以及探索自动化标注的可行性,虽然大型语言模型能够生成与人类评分相关性接近的结果,但在处理引用内容和非正式语言时仍存在系统性偏差,表明其尚无法完全替代人类标注。
常用场景
经典使用场景
在自然语言处理领域,爱沙尼亚主观性数据集为文档级主观性分析提供了重要资源。该数据集通过连续数值标度(0至100)标注文本的主观性程度,突破了传统二元分类的局限,使得研究者能够更精细地探究语言中主观与客观表达的渐变光谱。其经典应用场景包括训练和评估主观性检测模型,尤其在资源稀缺的爱沙尼亚语中,为跨语言主观性研究搭建了桥梁,促进了语言技术在小语种中的发展。
实际应用
在实际应用中,爱沙尼亚主观性数据集可服务于媒体内容分析与信息过滤系统。例如,新闻机构可利用该数据集训练的模型自动识别并分类新闻与评论文章,辅助内容审核与推荐。在教育领域,它有助于开发语言学习工具,帮助学生区分事实陈述与观点表达。此外,在舆情监控与社交媒体分析中,该数据集能提升对爱沙尼亚语用户生成内容中主观倾向的检测精度,为公共决策和市场分析提供更细腻的语言洞察。
衍生相关工作
该数据集的创建衍生了一系列相关研究,尤其是在小语种资源构建与标注方法创新方面。受其连续标度标注的启发,后续工作可能探索其他语言中类似数据集的构建,以促进跨语言主观性模型的比较研究。同时,数据集对人类与LLM标注差异的分析,推动了关于标注一致性、上下文效应及自动化标注可靠性的深入探讨,为自然语言处理中主观任务的标准制定提供了参考,并可能激发在新兴领域如可解释人工智能与伦理计算中的应用。
以上内容由遇见数据集搜集并总结生成


