---
license: bsd-2-clause
dataset_info:
features:
- name: image
dtype: image
- name: writer_id
dtype: string
- name: hsf_id
dtype: int64
- name: character
dtype:
class_label:
names:
'0': '0'
'1': '1'
'2': '2'
'3': '3'
'4': '4'
'5': '5'
'6': '6'
'7': '7'
'8': '8'
'9': '9'
'10': A
'11': B
'12': C
'13': D
'14': E
'15': F
'16': G
'17': H
'18': I
'19': J
'20': K
'21': L
'22': M
'23': 'N'
'24': O
'25': P
'26': Q
'27': R
'28': S
'29': T
'30': U
'31': V
'32': W
'33': X
'34': 'Y'
'35': Z
'36': a
'37': b
'38': c
'39': d
'40': e
'41': f
'42': g
'43': h
'44': i
'45': j
'46': k
'47': l
'48': m
'49': 'n'
'50': o
'51': p
'52': q
'53': r
'54': s
'55': t
'56': u
'57': v
'58': w
'59': x
'60': 'y'
'61': z
splits:
- name: train
num_bytes: 206539811.49
num_examples: 814277
download_size: 200734290
dataset_size: 206539811.49
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
task_categories:
- image-classification
size_categories:
- 100K<n<1M
---
# Dataset Card for FEMNIST
The FEMNIST dataset is a part of the [LEAF](https://leaf.cmu.edu/) benchmark.
It represents image classification of handwritten digits, lower and uppercase letters, giving 62 unique labels.
## Dataset Details
### Dataset Description
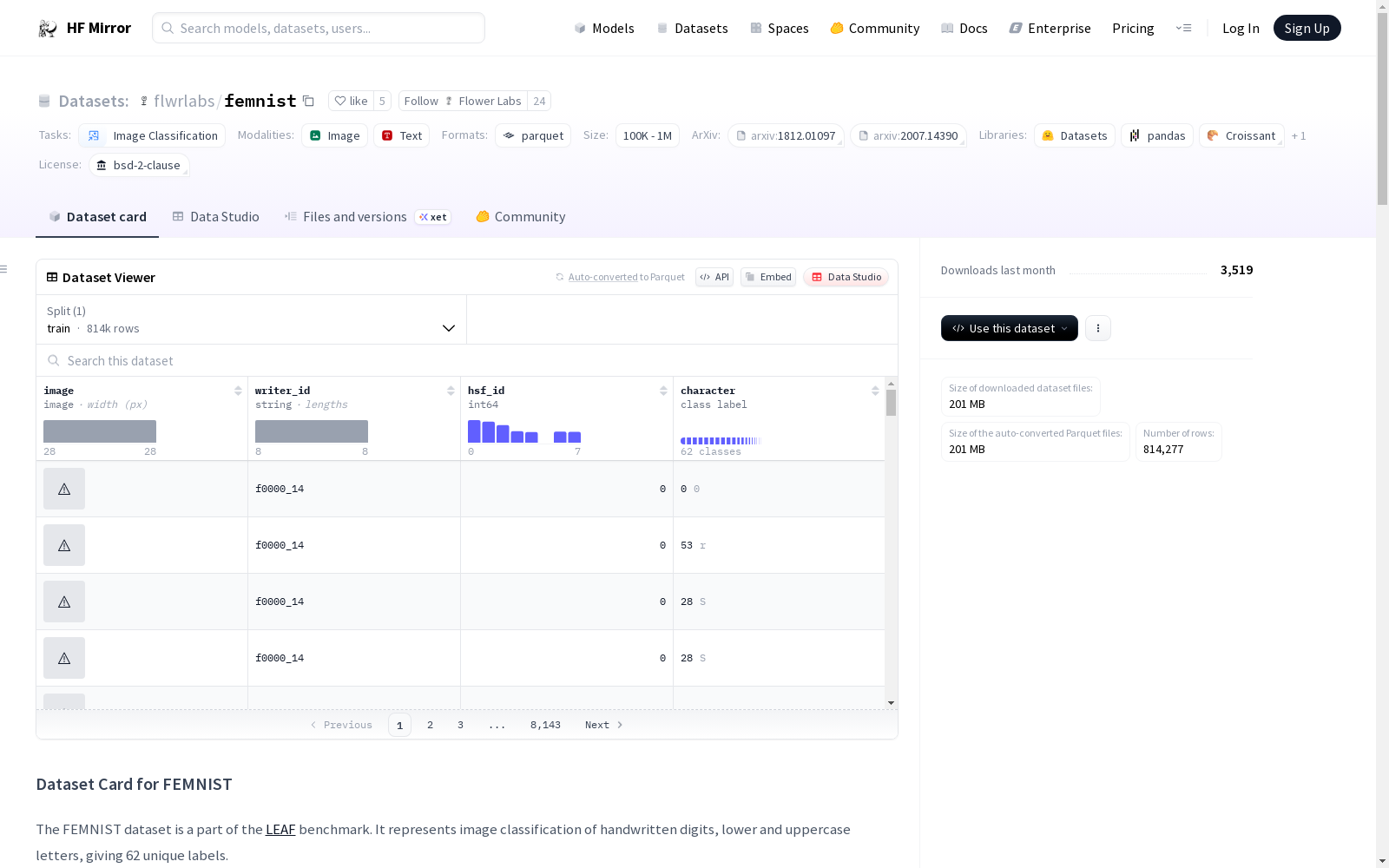
Each sample is comprised of a (28x28) grayscale image, writer_id, hsf_id, and character.
- **Curated by:** [LEAF](https://leaf.cmu.edu/)
- **License:** BSD 2-Clause License
### Dataset Sources
The FEMNIST is a preprocessed (in a way that resembles preprocessing for MNIST) version of [NIST SD 19](https://www.nist.gov/srd/nist-special-database-19).
## Uses
This dataset is intended to be used in Federated Learning settings.
### Direct Use
We recommend using [Flower Dataset](https://flower.ai/docs/datasets/) (flwr-datasets) and [Flower](https://flower.ai/docs/framework/) (flwr).
To partition the dataset, do the following.
1. Install the package.
```bash
pip install flwr-datasets[vision]
```
2. Use the HF Dataset under the hood in Flower Datasets.
```python
from flwr_datasets import FederatedDataset
from flwr_datasets.partitioner import NaturalIdPartitioner
fds = FederatedDataset(
dataset="flwrlabs/femnist",
partitioners={"train": NaturalIdPartitioner(partition_by="writer_id")}
)
partition = fds.load_partition(partition_id=0)
```
## Dataset Structure
The whole dataset is kept in the train split. If you want to leave out some part of the dataset for centralized evaluation, use Resplitter. (The full example is coming soon here)
Dataset fields:
* image: grayscale of size (28, 28), PIL Image,
* writer_id: string, unique value per each writer,
* hsf_id: string, corresponds to the way that the data was collected (see more details [here](https://www.nist.gov/srd/nist-special-database-19),
* character: ClassLabel (it means it's int if you access it in the dataset, but you can convert it to the original value by `femnist["train"].features["character"].int2str(value)`.
## Dataset Creation
### Curation Rationale
This dataset was created as a part of the [LEAF](https://leaf.cmu.edu/) benchmark.
We make it available in the HuggingFace Hub to facilitate its seamless use in FlowerDatasets.
### Source Data
[NIST SD 19](https://www.nist.gov/srd/nist-special-database-19)
#### Data Collection and Processing
For the preprocessing details, please refer to the original paper, the source code and [NIST SD 19](https://www.nist.gov/srd/nist-special-database-19)
#### Who are the source data producers?
For the preprocessing details, please refer to the original paper, the source code and [NIST SD 19](https://www.nist.gov/srd/nist-special-database-19)
## Citation
When working on the LEAF benchmark, please cite the original paper. If you're using this dataset with Flower Datasets, you can cite Flower.
**BibTeX:**
```
@article{DBLP:journals/corr/abs-1812-01097,
author = {Sebastian Caldas and
Peter Wu and
Tian Li and
Jakub Kone{\v{c}}n{\'y} and
H. Brendan McMahan and
Virginia Smith and
Ameet Talwalkar},
title = {{LEAF:} {A} Benchmark for Federated Settings},
journal = {CoRR},
volume = {abs/1812.01097},
year = {2018},
url = {http://arxiv.org/abs/1812.01097},
eprinttype = {arXiv},
eprint = {1812.01097},
timestamp = {Wed, 23 Dec 2020 09:35:18 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1812-01097.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
```
@article{DBLP:journals/corr/abs-2007-14390,
author = {Daniel J. Beutel and
Taner Topal and
Akhil Mathur and
Xinchi Qiu and
Titouan Parcollet and
Nicholas D. Lane},
title = {Flower: {A} Friendly Federated Learning Research Framework},
journal = {CoRR},
volume = {abs/2007.14390},
year = {2020},
url = {https://arxiv.org/abs/2007.14390},
eprinttype = {arXiv},
eprint = {2007.14390},
timestamp = {Mon, 03 Aug 2020 14:32:13 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2007-14390.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
## Dataset Card Contact
In case of any doubts, please contact [Flower Labs](https://flower.ai/).
# FEMNIST 数据集卡片
许可证:BSD 2条款许可证
## 数据集元信息
### 数据集特征
1. **图像(image)**:图像格式数据
2. **作者ID(writer_id)**:字符串类型,用于标识手写样本的创作者
3. **HSF ID(hsf_id)**:64位整数类型,对应数据采集相关标识
4. **字符标签(character)**:类别标签(class_label),类别索引与对应字符的映射关系如下:
| 索引 | 字符 |
| --- | --- |
| 0 | 0 |
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
| 4 | 4 |
| 5 | 5 |
| 6 | 6 |
| 7 | 7 |
| 8 | 8 |
| 9 | 9 |
| 10 | A |
| 11 | B |
| 12 | C |
| 13 | D |
| 14 | E |
| 15 | F |
| 16 | G |
| 17 | H |
| 18 | I |
| 19 | J |
| 20 | K |
| 21 | L |
| 22 | M |
| 23 | N |
| 24 | O |
| 25 | P |
| 26 | Q |
| 27 | R |
| 28 | S |
| 29 | T |
| 30 | U |
| 31 | V |
| 32 | W |
| 33 | X |
| 34 | Y |
| 35 | Z |
| 36 | a |
| 37 | b |
| 38 | c |
| 39 | d |
| 40 | e |
| 41 | f |
| 42 | g |
| 43 | h |
| 44 | i |
| 45 | j |
| 46 | k |
| 47 | l |
| 48 | m |
| 49 | n |
| 50 | o |
| 51 | p |
| 52 | q |
| 53 | r |
| 54 | s |
| 55 | t |
| 56 | u |
| 57 | v |
| 58 | w |
| 59 | x |
| 60 | y |
| 61 | z |
### 数据拆分
训练拆分(train):占用字节数206539811.49,共包含814277个样本
### 下载与数据集规模
下载大小:200734290字节,数据集总大小:206539811.49字节
### 配置项
默认配置(default):数据文件路径为`data/train-*`,对应训练拆分
### 任务类别
图像分类
### 样本规模
10万 < 样本数量 < 100万
---
FEMNIST 数据集属于 [LEAF](https://leaf.cmu.edu/) 基准测试套件的一部分,用于手写数字、大小写字母的图像分类任务,共包含62个唯一类别标签。
## 数据集详情
### 数据集概述
每个样本由一张(28×28)灰度图像、作者ID、HSF ID以及字符标签组成。
- **整理方**:[LEAF](https://leaf.cmu.edu/)
- **许可证**:BSD 2条款许可证
### 数据集来源
FEMNIST 是对 [NIST SD 19](https://www.nist.gov/srd/nist-special-database-19) 进行预处理后的版本,其预处理逻辑与MNIST数据集的预处理方式相近。
## 数据集用途
本数据集专为联邦学习场景设计。
### 直接使用建议
我们推荐使用 [Flower 数据集](https://flower.ai/docs/datasets/)(flwr-datasets)与 [Flower](https://flower.ai/docs/framework/)(flwr)框架开展相关研究与开发。
如需对数据集进行分区,可按照以下步骤操作:
1. 安装依赖包:
bash
pip install flwr-datasets[vision]
2. 在 Flower 数据集框架中调用 Hugging Face 原生数据集:
python
from flwr_datasets import FederatedDataset
from flwr_datasets.partitioner import NaturalIdPartitioner
fds = FederatedDataset(
dataset="flwrlabs/femnist",
partitioners={"train": NaturalIdPartitioner(partition_by="writer_id")}
)
partition = fds.load_partition(partition_id=0)
## 数据集结构
整个数据集仅包含训练拆分。如需预留部分数据用于集中式评估,可使用`Resplitter`工具进行拆分(完整示例将后续补充)。
数据集字段说明如下:
* **image**:尺寸为(28, 28)的灰度图像,格式为PIL图像
* **writer_id**:字符串类型,每个手写作者对应唯一的ID
* **hsf_id**:整数类型,对应数据采集的具体方式(详见[官方文档](https://www.nist.gov/srd/nist-special-database-19))
* **character**:类别标签(class_label):在数据集中以整数形式存储,可通过`femnist["train"].features["character"].int2str(value)`将其转换为原始字符值。
## 数据集构建
### 构建初衷
本数据集作为 [LEAF](https://leaf.cmu.edu/) 基准测试套件的一部分开发完成,我们将其上传至 Hugging Face Hub,以方便在 FlowerDatasets 中无缝使用。
### 源数据
[NIST SD 19](https://www.nist.gov/srd/nist-special-database-19)
#### 数据采集与预处理
如需了解预处理细节,请参考原始论文、源代码以及 [NIST SD 19](https://www.nist.gov/srd/nist-special-database-19) 官方文档。
#### 原始数据生产者
如需了解相关信息,请参考原始论文、源代码以及 [NIST SD 19](https://www.nist.gov/srd/nist-special-database-19) 官方文档。
## 引用规范
当使用 LEAF 基准测试套件时,请引用原始论文;若结合 Flower Datasets 使用本数据集,请同时引用 Flower 相关文献。
**BibTeX 引用格式:**
@article{DBLP:journals/corr/abs-1812-01097,
author = {Sebastian Caldas and
Peter Wu and
Tian Li and
Jakub Kone{v}c{n}'y} and
H. Brendan McMahan and
Virginia Smith and
Ameet Talwalkar},
title = {{LEAF:} {A} Benchmark for Federated Settings},
journal = {CoRR},
volume = {abs/1812.01097},
year = {2018},
url = {http://arxiv.org/abs/1812.01097},
eprinttype = {arXiv},
eprint = {1812.01097},
timestamp = {Wed, 23 Dec 2020 09:35:18 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1812-01097.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
@article{DBLP:journals/corr/abs-2007-14390,
author = {Daniel J. Beutel and
Taner Topal and
Akhil Mathur and
Xinchi Qiu and
Titouan Parcollet and
Nicholas D. Lane},
title = {Flower: {A} Friendly Federated Learning Research Framework},
journal = {CoRR},
volume = {abs/2007.14390},
year = {2020},
url = {https://arxiv.org/abs/2007.14390},
eprinttype = {arXiv},
eprint = {2007.14390},
timestamp = {Mon, 03 Aug 2020 14:32:13 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2007.14390.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
## 数据集卡片联系方式
如有任何疑问,请联系 [Flower Labs](https://flower.ai/).